Query Transformation Pipeline: HyDE & LangChain v1 in 2026
TL;DR
- Single-query retrieval ships demos. Production traffic includes ambiguous short queries, jargon-heavy questions, and broad topic queries — each needs a different transformation strategy.
- HyDE, multi-query, and step-back are not interchangeable. HyDE rewrites detail-rich questions into the corpus’s dialect; multi-query expands ambiguous short queries; step-back surfaces foundational context.
- LangChain v1 moved both
MultiQueryRetrieverandHypotheticalDocumentEmbedderinto thelangchain-classicpackage. Tutorial code with the old import paths breaks on first install.
A user types “auth issue” into your search. Your pipeline embeds three words, hits the vector store, returns chunks about authorization headers, OAuth flows, and a deprecated SAML guide. The actual ticket is about a token refresh loop. Your dense embedding had no exact match for “auth issue” — and “auth issue” had no semantic neighborhood to land in.
That gap — between what users type and what the corpus indexed — is where Query Transformation lives. And in 2026, the mistake is not failing to add transformations. The mistake is adding all of them, to every query, indiscriminately.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex)
- Working knowledge of Retrieval Augmented Generation and a deployed retriever
- A deployed retrieval backend — ideally Hybrid Search (dense + sparse) for the components downstream of query transformation
- A
LangChain 1.x environment with
langchain-classicinstalled - A query log from real production traffic — you cannot tune routing for a distribution you have never measured
This guide teaches you: How to decompose query transformation into a routing decision, three transformation strategies, and a fusion stage — so the AI tool generates a pipeline that fits your query distribution instead of a textbook example.
The Three-Word Query That Killed Recall
Most teams enable HyDE, slap multi-query on top, and call it “advanced retrieval.” Then production traffic comes in. Many queries are three words. Some mention specific product names that HyDE invents fictional context around. Others are broad topic questions that benefit from broader context, not narrower.
It worked on Friday. On Monday, recall dropped because every query triggered the same expansion strategy regardless of shape — and HyDE was hallucinating documents about features that did not exist in the corpus.
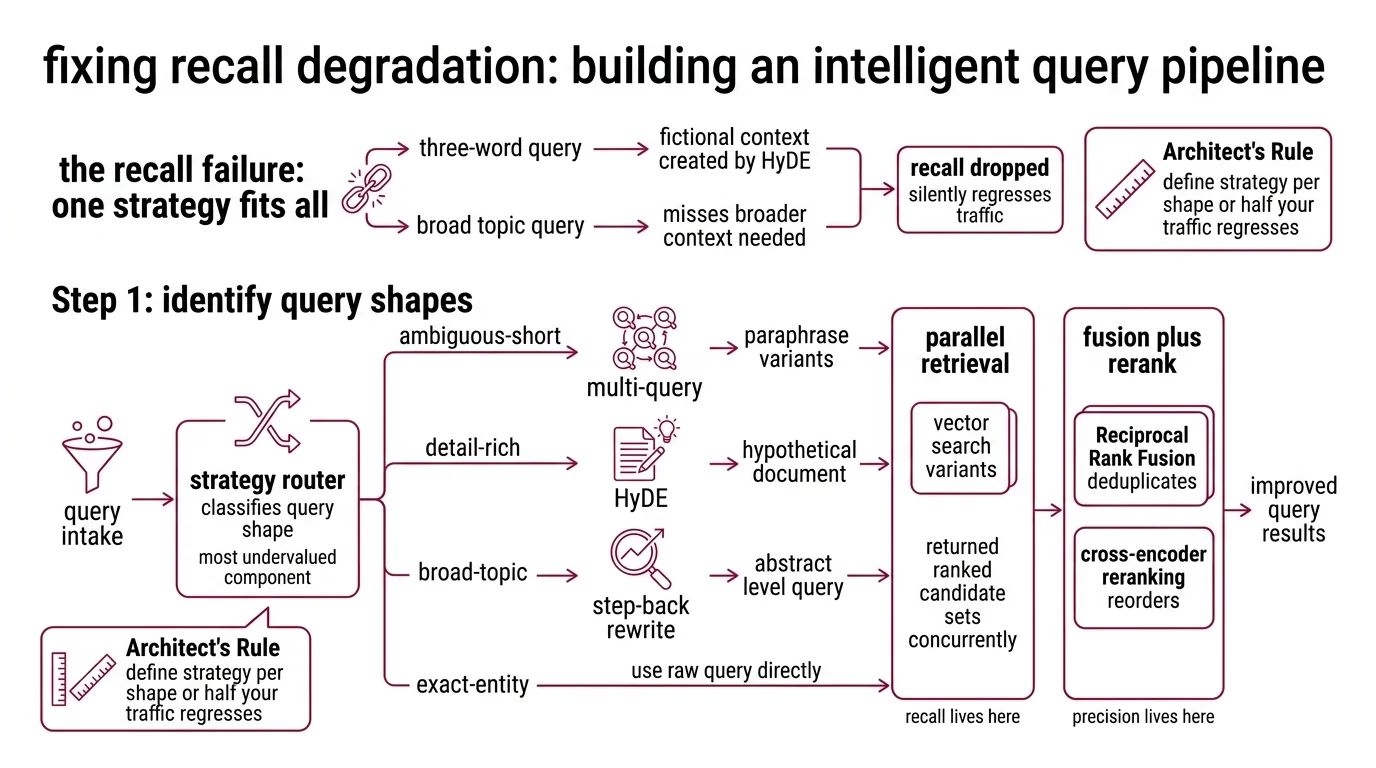
Step 1: Identify the Query Shapes Your Pipeline Receives
Before picking a transformation, decompose your query distribution. Different shapes need different strategies — and the routing decision is the component most pipelines pretend they do not need.
Your system has these parts:
- Query intake — receives the raw user query, normalizes case, whitespace, and punctuation, enforces length bounds. Owns nothing else.
- Strategy router — classifies the query shape (ambiguous-short, detail-rich, broad-topic, exact-entity) and dispatches to the right transformation. The single most undervalued component in the pipeline.
- Query expanders — three of them, each a separate function. Multi-query produces paraphrase variants. HyDE generates a hypothetical document and embeds that. Step-back rewrites the query at a more abstract level. Each owns one shape.
- Parallel retrieval — runs vector search per variant, returns ranked candidate sets concurrently. Recall lives here.
- Fusion plus rerank — Reciprocal Rank Fusion deduplicates across variants, then a cross-encoder pass via Reranking reorders. Precision lives here.
The Architect’s Rule: If you cannot tell the AI which query shape triggers which transformation, the AI will pick one strategy and apply it to everything. Then half your traffic regresses silently.
The reason this matters is empirical. HyDE — Hypothetical Document Embeddings — prompts an instruction-tuned LLM to generate a hypothetical answer document, then encodes that document and retrieves real docs by vector similarity (Gao et al. 2022). It only helps when the LLM actually knows something about your domain. Recent research warns that HyDE can leak training-data biases into retrieval and underperforms when the LLM lacks the domain knowledge it is fabricating (arXiv 2504.14175). Multi-query, by contrast, paraphrases the query itself — it cannot hallucinate a topic it does not know.
Step 2: Lock Down the Stack and Strategy Contracts
Vague specs produce vague code. Pinned contracts produce pipelines that survive a dependency upgrade — and the dependency upgrade in 2026 already broke the most popular tutorials on the web.
Context checklist:
- Framework: LangChain Python 1.2.x with
langchain-core1.3.x. Use LCEL — the|operator — not the legacyLLMChainfrom 0.x. - Legacy retrievers package:
langchain-classicis required for bothMultiQueryRetrieverandHypotheticalDocumentEmbedderafter LangChain v1.0 (LangChain v1 migration guide). Imports:from langchain_classic.retrievers import MultiQueryRetrieverandfrom langchain_classic.chains import HypotheticalDocumentEmbedder. - Generation LLM for query rewrites: gpt-4o-mini at $0.15 per 1M input tokens and $0.60 per 1M output tokens (OpenAI API Pricing). Cost-optimal default for query expansion. Switch to a more capable model only after the strategy router shows quality regressions traceable to the rewrite stage.
- Embedding model: text-embedding-3-small at $0.02 per 1M tokens, 1536 dimensions by default with Matryoshka shortening to 256–1536. Use the same encoder for the HyDE base and direct query embedding — never mix encoders inside one candidate set.
- Reranker: Cohere Rerank 3.5 at $2.00 per 1,000 searches, where one search is one query plus up to 100 documents and chunks over 500 tokens count separately (Cohere Rerank). Budget accordingly when each variant fans out additional sub-queries.
- Strategy router contract:
route(query: str) -> Literal["multi_query", "hyde", "step_back", "raw"]. Inputs explicit, output enumerated, no fallthrough. - HyDE prompt key: Pick from the eight built-in templates —
web_search,sci_fact,arguana,trec_covid,fiqa,dbpedia_entity,trec_news,mr_tydi— or pass your own viacustom_prompt(LangChain API Reference). Match the prompt to your domain.sci_factwill hurt recall on a customer-support corpus. - MultiQueryRetriever defaults: Three alternative phrasings per query and dedup by chunk ID across retrievals. The
parser_keyparameter is deprecated in v1.x — do not specify it. - Retrieval substrate: Assume hybrid search (dense plus sparse fused) underneath. Query transformation amplifies whatever the retriever can do. It does not fix a retriever that cannot match exact tokens.
The Spec Test: If your context document does not pin
langchain-classicand the exact import paths forMultiQueryRetrieverandHypotheticalDocumentEmbedder, the AI tool will ingest a 0.x tutorial and emitfrom langchain.retrievers import MultiQueryRetriever. That import willImportErroron a fresh install. The error happens at startup, not in tests — your CI may pass and prod will refuse to boot.
Security & compatibility notes:
- LangChain v1.0 import paths — BREAKING:
MultiQueryRetrieverandHypotheticalDocumentEmbeddermoved tolangchain-classicin October 2025 (LangChain v1 migration guide). Old tutorials withfrom langchain.retrievers import ...andfrom langchain.chains import ...willImportError. Installlangchain-classicand update imports.- HyDE knowledge leakage — WARNING: HyDE underperforms when the generation LLM lacks domain knowledge and can leak training-data biases into retrieval (arXiv 2504.14175). Do not enable HyDE by default — gate it through the strategy router and pair with a fallback to raw query when the generated document scores low confidence.
- MultiQueryRetriever
parser_key— INFO: Parameter deprecated in v1.x. Do not specify it; rely on the defaultRunnableinterface.- gpt-4o-mini knowledge cutoff — INFO: Cutoff is October 2023. For queries about post-cutoff releases, pair HyDE with a newer generation model or web-augmented context, or route those queries to
raw.
Step 3: Wire the Components in Order
Build a transformation pipeline backwards and you debug five layers at once. Build it forward and each component becomes a unit you can swap.
Build order:
- Strategy router first — because every other stage depends on its output. Contract: in is a normalized query string; out is a strategy label plus pre-computed features such as token count, has-named-entity, is-question. Constraint: avoid an LLM call here unless your router itself uses an LLM classifier — and if it does, cache aggressively. Starting heuristics: short queries with no named entity route to
multi_query; detail-rich questions route tohyde; queries framed as “how does X work” or “why” route tostep_back; queries with an exact ID, SKU, or quoted phrase route toraw. Tune these from your query log, not from a blog post. - Query expanders next — three sibling functions, each isolated. The multi-query expander returns a list of paraphrases. The HyDE expander returns a list containing the hypothetical document. The step-back expander returns the original query paired with its abstract reformulation. Constraint: each expander returns the same shape — a list of strings to embed — so the downstream stage stays uniform.
- Parallel retrieval third — because the rest of the pipeline depends on candidates. Contract: in is a list of query strings and a top-K integer; out is a list of (chunk, score, source_query) tuples. Run searches concurrently — total latency is bounded by the slowest variant, not the sum.
- Fusion fourth — Reciprocal Rank Fusion across variants, deduplicating by chunk ID. Contract: in is the multi-source candidate list; out is a single deduped ranked list. Constraint: do not skip fusion when only one variant ran (the
rawroute) — pass through with a no-op so the downstream contract stays uniform. - Rerank last — cross-encoder pass over the top-N fused candidates with Cohere Rerank 3.5 as the default. Contract: in is the query plus top-N; out is reordered candidates with cross-encoder scores. Constraint: rerank the original user query, not a transformed variant. The user’s intent lives in the raw query, not in the hypothetical document.
For each component, your context document must specify what it receives, what it returns, what it must NOT do, and how it handles failure. Without that, the AI tool will silently merge the router into the expander, or rerank against the HyDE document instead of the user query.
Step 4: Validate Each Component in Isolation
Validation is not “type three queries and read the answers.” It is automated metric collection per stage, run on a fixed eval set every spec change.
Validation checklist:
- Router accuracy — failure looks like every query routing to
hyderegardless of shape. Hand-label a sample of queries from your log with the correct strategy, measure router accuracy, and track it as its own metric. If accuracy drifts, the router is the problem — not the expanders. - Expander quality (HyDE) — failure looks like a plausible-sounding hypothetical document that invents facts that do not exist in your corpus, retrieving chunks unrelated to user intent. Track an HyDE-confidence proxy — for example, the cosine similarity between the HyDE doc and its top retrieved chunk. When confidence falls below threshold, fall back to the raw query. Adaptive HyDE (arXiv 2507.16754) implements exactly this gate as a 2026 evolution of the original method.
- Expander quality (multi-query) — failure looks like three paraphrases that are near-duplicates of the original. Measure pairwise diversity across variants; if duplicates dominate, raise temperature on the rewrite LLM or change the prompt template.
- Fusion sanity — failure looks like RRF demoting a chunk that every variant ranked top of its list. Spot-check the fused top-K against per-variant rankings; if unanimous picks fall, your fusion key or score normalization is wrong.
- End-to-end recall vs raw baseline — failure looks like the full transformation pipeline scoring worse than direct embedding on a labeled eval set. Hold a baseline of “raw query → retrieve → rerank” and gate every spec change against it. If transformation regresses, ship the baseline and debug the router.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| One-shot “add HyDE to my RAG” | Too many concerns — AI enabled HyDE on every query and silently hurt recall on short ones | Decompose into router plus three expanders; route by query shape |
Used from langchain.retrievers import MultiQueryRetriever | LangChain v1 moved it to langchain-classic — code ImportErrors on fresh install | Pin langchain-classic; import from langchain_classic.retrievers |
| Reranked the HyDE document instead of the user query | The hypothetical doc is for retrieval recall, not precision scoring | Rerank against the original query; HyDE retrieves, the user query ranks |
| Picked the default HyDE prompt key for any domain | web_search template hurts recall on customer-support corpora | Match prompt key to domain or pass custom_prompt; eight built-ins exist |
| Enabled multi-query for queries with exact identifiers | Paraphrasing dilutes exact-match terms — SKUs, error codes, IDs disappear | Route exact-entity queries to raw; let the retriever handle them directly |
| Ignored knowledge cutoff for HyDE | gpt-4o-mini cuts off in October 2023 — HyDE invents stale or wrong context | Pair HyDE with a fresher model or route post-cutoff topics to raw |
Pro Tip
Three transformations is two too many for most queries. A large share of production traffic is well-served by raw retrieval with a strong reranker. Query transformation pays off on the long tail — ambiguous short queries, jargon-heavy questions, broad topic questions — and that long tail is rarely the majority. Build the router first. Measure how often each strategy actually helps. Only then decide which expanders earn their place in the pipeline.
The same warning applies the moment you reach for Agentic RAG loops on top of this. An iterative refinement agent compounds every weakness in the underlying transformation layer. Get the static pipeline measured and stable before you wrap it in a loop that calls itself.
Frequently Asked Questions
Q: How to implement HyDE and multi-query retrieval in a RAG pipeline step by step in 2026?
A: Install langchain-classic, build a strategy router that classifies queries by shape, then wire HypotheticalDocumentEmbedder.from_llm() for detail-rich queries and MultiQueryRetriever.from_llm() for ambiguous short ones — both imported from langchain_classic. Fan results into Reciprocal Rank Fusion, then rerank the original query, not the HyDE document, with Cohere Rerank 3.5. The watch-out: HyDE leaks training-data bias when the LLM lacks domain knowledge — gate it via a confidence check or use the Adaptive HyDE pattern (arXiv 2507.16754) as a fallback to the raw query.
Your Spec Artifact
By the end of this guide, you should have:
- A five-box pipeline diagram naming router, three expanders, parallel retrieval, fusion, and rerank — each with explicit inputs, outputs, and forbidden behaviors.
- A pinned stack contract: LangChain Python 1.2.x with
langchain-classicfor legacy retrievers, gpt-4o-mini for query rewrites, text-embedding-3-small as the encoder, and Cohere Rerank 3.5 as the precision pass. - A validation plan that scores router accuracy, per-expander quality, fusion sanity, and end-to-end recall against a raw-query baseline gate — so you ship the baseline whenever a transformation regresses.
Your Implementation Prompt
Drop this prompt into your AI coding tool of choice (Claude Code, Cursor, Codex). Fill the bracketed placeholders with your project values. The prompt encodes the router-first decomposition from Step 1, the stack contract from Step 2, the build order from Step 3, and the validation gates from Step 4 — so the AI cannot default to a 0.x tutorial or merge the router into an expander.
Build a query-transformation pipeline for [project name / domain] using the
following five-component architecture.
Stack contract — pin exactly:
- Framework: LangChain Python 1.2.x with langchain-core 1.3.x. Use LCEL (the
`|` operator), not legacy LLMChain.
- Legacy retrievers package: langchain-classic (required after LangChain
v1.0). Imports:
from langchain_classic.retrievers import MultiQueryRetriever
from langchain_classic.chains import HypotheticalDocumentEmbedder
Do NOT use `from langchain.retrievers import ...` or
`from langchain.chains import ...` for these — they break on v1.x.
- Generation LLM for query rewrites: gpt-4o-mini.
- Embedding model: text-embedding-3-small (1536 dims default; same model for
HyDE base encoder and direct query embedding).
- Reranker: Cohere Rerank 3.5 via /v2/rerank.
- HyDE prompt key: pick one of [web_search, sci_fact, arguana, trec_covid,
fiqa, dbpedia_entity, trec_news, mr_tydi] OR pass custom_prompt =
[your domain-specific prompt template].
- MultiQueryRetriever: default 3 paraphrases; DO NOT specify the deprecated
parser_key parameter.
Components — implement in this order, each as a separate function/module
with its own contract:
1. Query intake: input = raw user string; output = normalized query (case,
whitespace, length bounds). Constraint: no LLM call.
2. Strategy router: input = normalized query; output =
Literal["multi_query", "hyde", "step_back", "raw"] plus features
(token_count, has_named_entity, is_question). Heuristics to start:
- short query, no named entity → "multi_query"
- detail-rich question → "hyde"
- "how does X work" or "why" framing → "step_back"
- quoted phrase or exact ID/SKU → "raw"
Tune from query log [path or name of your eval set].
3. Query expanders (three siblings, same output shape — list of strings to
embed):
a. multi_query_expand(query) -> list[str]
b. hyde_expand(query) -> list[str]
# via HypotheticalDocumentEmbedder.from_llm
c. step_back_expand(query) -> list[str]
# original + abstract reformulation
4. Parallel retrieval: input = (variants: list[str], top_k: int);
output = list of (chunk, score, source_query). Run searches concurrently.
Constraint: no rerank in this layer.
5. Fusion: Reciprocal Rank Fusion across variants, deduplicated by chunk ID.
Constraint: pass-through no-op when only one variant ran (raw route) so
the downstream contract stays uniform.
6. Rerank: Cohere Rerank 3.5 over top-N fused candidates. Rerank the
ORIGINAL user query — never a transformed variant.
Failure modes I want explicit handling for:
- HyDE confidence below threshold → fall back to raw query (Adaptive HyDE
pattern).
- Generation LLM timeout on rewrite → fall back to raw query, do NOT block.
- Rerank API failure → return fused order, log the failure, do NOT silently
drop the request.
- Router fallthrough (no rule matched) → default to "raw".
Validation gates:
- Router accuracy on labeled sample [N] queries > [your threshold].
- End-to-end recall vs raw baseline must NOT regress on eval set [path].
- Per-expander pairwise diversity > [your threshold] for multi-query.
Do NOT generate a single end-to-end chain. Generate the units above with
the contracts as written, plus a thin LCEL orchestrator that wires them.
Ship It
You now have a query-transformation pipeline that decomposes into a router, three expanders, fused retrieval, and a precision pass — each owned, each measurable, each replaceable. That is what 2026 query transformation looks like — not “enable HyDE everywhere,” but a routing decision that sends each query to the strategy that fits its shape, with a baseline gate that catches regressions before users do.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors