Production RAG with LangChain, Qdrant & Cohere Rerank in 2026
TL;DR
- A Retrieval Augmented Generation pipeline is five components, not one prompt — index, retriever, reranker, generator, evaluator. Spec each one separately or they fight each other in production.
- Dense-only retrieval ships demos. Production needs hybrid retrieval (dense + sparse) plus a cross-encoder rerank. Skip either and your recall or precision craters on real queries.
- If you cannot measure faithfulness and context precision, you cannot ship. Wire Ragas in before the LLM call goes live, not after.
It works in the demo. The team types three sample questions, gets three crisp answers, ships it. Then a customer asks for the refund policy and the system returns the cancellation form template instead. Not because the LLM hallucinated — because the index was dense-only and nothing reranked the candidates before generation.
That gap — between “RAG that works on three samples” and “RAG that survives a thousand customer queries” — is what this guide closes.
Before You Start
You’ll need:
- A Vector Database (this guide uses Qdrant — Qdrant Cloud Free works for development, Standard for production)
- Working knowledge of LangChain 1.x and the LangGraph runtime
- An understanding of Chunking Strategy for your document type (legal, FAQ, and general docs each behave differently)
- A Cohere API key for Rerank 4
- A way to run Ragas — typically the same Python environment as your LangChain pipeline
This guide teaches you: How to decompose a production RAG system into five owned components, specify the contract between each, and validate the result with Ragas — instead of typing prompts into an LLM and hoping retrieval keeps up.
The Demo That Worked, The Pipeline That Didn’t
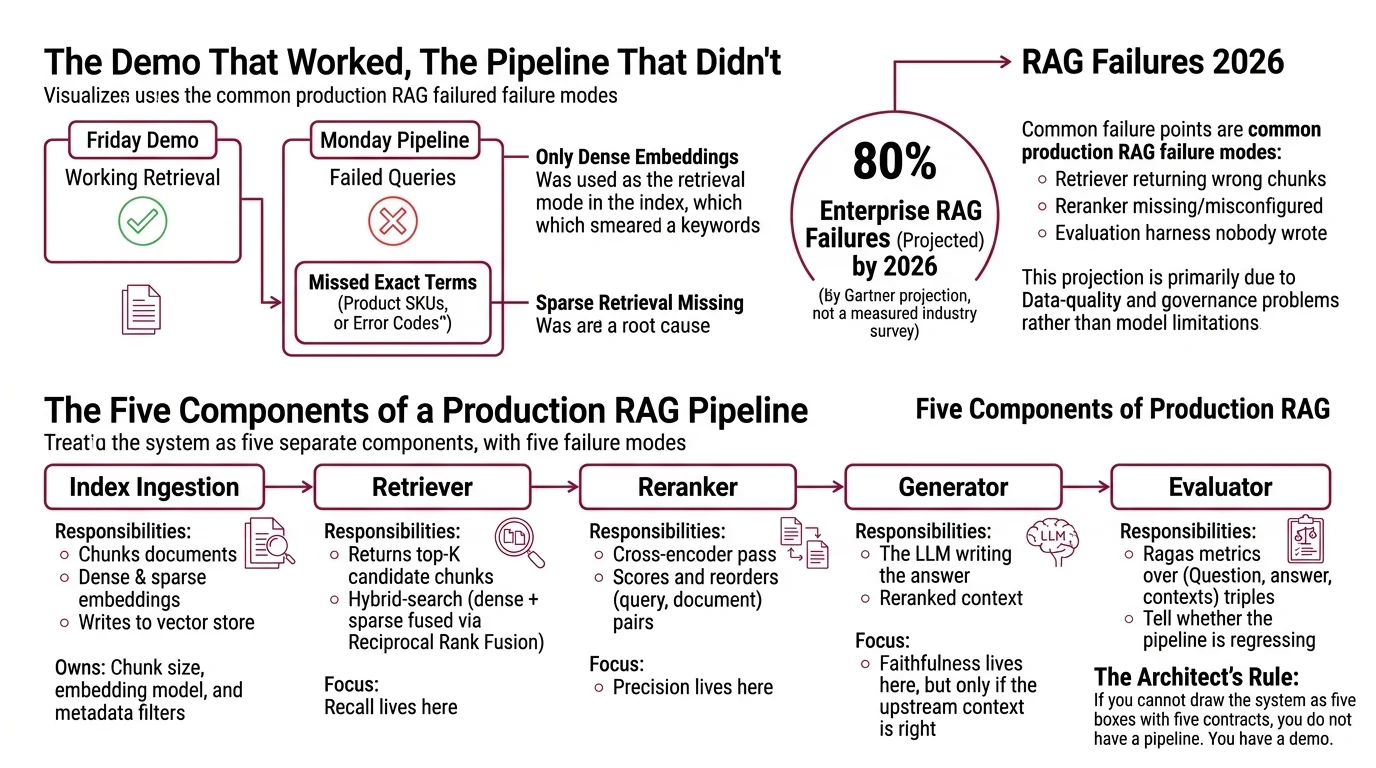
The most common production RAG failure mode in 2026 is not the LLM. It’s the retriever returning the wrong chunks, the reranker either missing or misconfigured, and an evaluation harness that nobody wrote. Gartner projects that around 80% of enterprise RAG projects will fail by 2026, primarily due to data-quality and governance problems rather than model limitations (IBM Think) — frame this as a projection, not a measured industry survey.
It worked on Friday. On Monday, customer queries started missing exact-match terms — product SKUs, error codes, regulatory IDs — because the only retrieval mode in the index was dense embeddings, which smear keywords into semantic neighborhoods. Sparse retrieval was never wired in.
Step 1: Map the Five Components of a Production RAG Pipeline
A production RAG system is not a chain — it is five components with five separate failure modes. Treat the architecture this way and you can debug each part in isolation when something breaks.
Your system has these parts:
- Index ingestion — chunks documents, computes dense + sparse embeddings, writes them to the vector store. Owns chunk size, embedding model, and metadata filters.
- Retriever — given a user query, returns the top-K candidate chunks using Hybrid Search (dense + sparse fused via Reciprocal Rank Fusion). Recall lives here.
- Reranker — takes the candidate set, runs a cross-encoder pass that scores each (query, document) pair jointly, and reorders. Precision lives here.
- Generator — the LLM that takes the reranked context and writes the answer. Faithfulness lives here, but only if the upstream context is right.
- Evaluator — Ragas metrics over (question, answer, contexts) triples. Tells you whether the pipeline is regressing before customers do.
The Architect’s Rule: If you cannot draw the system as five boxes with five contracts, you do not have a pipeline. You have a demo with extra steps.
The reranker is non-negotiable for production quality. A cross-encoder reranker after retrieval and fusion gives the largest single precision lift in the pipeline — but it cannot recover documents the retriever missed (Superlinked VectorHub). Recall comes from the retriever. Precision comes from the reranker. Mix those up and you tune the wrong stage.
Step 2: Lock Down the Stack Contract
Before you generate a single line of pipeline code, the AI tool needs to know exactly which versions, packages, and APIs you are committing to. Vague specs produce vague code. Pinned specs produce pipelines that survive a dependency upgrade.
Context checklist:
- Framework: LangChain 1.0 with the LangGraph runtime, both released 22 October 2025 (LangChain Blog).
Agentic RAG patterns should use LangGraph (
create_react_agent, state graphs), not the older LCEL chains from 0.x. - Vector store package:
langchain-qdrantv1.1.0 from PyPI (langchain-qdrant on PyPI). Import asfrom langchain_qdrant import QdrantVectorStore— the olderlangchain_community.vectorstores.Qdrantimport is deprecated and slated for removal. - Vector store server: Qdrant server v1.10 or higher for the new Query API and hybrid retrieval (LangChain Docs). The current GA at the time of writing is v1.17.
- Retrieval mode:
RetrievalMode.HYBRID— dense + sparse fused via Qdrant’s Query API. FastEmbed provides the sparse encoder out of the box (LangChain Docs). - Reranker: Cohere Rerank 4, released 11 December 2025 (Cohere Docs). Use
rerank-v4.0-profor quality-critical paths andrerank-v4.0-fastfor high-throughput, low-latency paths. Both are multilingual single models on the/v2/rerankendpoint with a 32K-token context window per query+document pair. - Reranker API contract: v2 endpoint requires the
modelparameter; the oldermax_chunks_per_docparameter has been replaced bymax_tokens_per_doc. - Evaluator: Ragas 0.4.3 with the four reference-free metrics: Faithfulness, Answer Relevance, Context Precision, and Context Recall (Ragas Docs).
The Spec Test: If your context document does not pin Qdrant server to ≥1.10 and the Cohere model to a specific Rerank 4 SKU, the AI tool will fall back to a tutorial it ingested during pre-training — which is probably the deprecated
langchain_communityimport paired withrerank-v3.5. That code will run today. It will also rot the moment you upgrade.
Security & compatibility notes:
- LangChain Qdrant import — BREAKING:
langchain_community.vectorstores.Qdrantdeprecated since 0.0.37. Migrate to thelangchain-qdrantpackage (from langchain_qdrant import QdrantVectorStore); the legacy import path is on track to break under LangChain 1.x cleanups.- Cohere Rerank model — WARNING: Pre-December-2025 tutorials still showing
rerank-v3.5as “the” model are outdated. Default torerank-v4.0-profor new builds; keeprerank-v3.5callable only as a previous-gen fallback.- Cohere Rerank pricing — WARNING: Cost models are not interchangeable. Rerank 3.5 was billed per-search ($2 per 1,000 searches; one search = one query + up to 100 docs ≤500 tokens). Rerank 4 Pro is billed per token at $2.50 per 1M input tokens. Re-estimate cost when migrating; do not extrapolate from old invoices. Rerank 4 Fast pricing is not on the public pricing page at time of writing — contact Cohere.
- Cohere Rerank API v2 — WARNING:
modelparameter is now required;max_chunks_per_docremoved in favor ofmax_tokens_per_doc. The v1 endpoint still works but v2 is the migration path.- Cohere Rerank legacy v2.0 family — WARNING: Some legacy v2.x SKUs were scheduled for retirement on 4 April 2026. Verify any v2.x model name on Cohere’s deprecations page before quoting it in a spec.
- Qdrant server — INFO: Hybrid mode requires Qdrant
>=1.10. Older self-hosted servers must upgrade or fall back to dense-only retrieval, which kills recall on keyword-heavy queries.
Step 3: Wire the Components in Order
Order matters more than people admit. Build a pipeline backwards and you debug five layers at once.
Build order:
- Index ingestion first — because nothing downstream works without populated vectors. The contract: in are documents and a chunking strategy; out are dense + sparse vectors written to a Qdrant collection with metadata for filtering. Constraint: no rerank or LLM call in this layer. Failure mode to spec: empty embeddings on edge-case documents (very short, very long, non-text PDFs).
- Retriever next — because the rest of the pipeline depends on what comes back. Contract: in is a query string and a top-K integer; out is a ranked list of (chunk, dense_score, sparse_score) tuples. Use
RetrievalMode.HYBRIDand Reciprocal Rank Fusion at k=60 as the zero-config baseline; only switch to weighted convex combination once you have at least 50 labeled query/relevance pairs to tune the weights against (Superlinked VectorHub). Constraint: no rerank yet — keep stages separable. - Reranker third — because it operates on what the retriever returned. Contract: in is the query plus the top-K candidates; out is a reordered list with cross-encoder scores. Pick
rerank-v4.0-proif your bottleneck is answer quality;rerank-v4.0-fastif it is per-query latency at scale. Constraint: never use the reranker as your retriever — the cross-encoder pass is too expensive to run over the entire corpus. - Generator fourth — because it consumes the reranked context. Contract: in is the question plus the top-N reranked chunks; out is an answer plus a citation map. Constraint: cap the context window so the LLM cannot pad with whatever else is in scope. Failure mode to spec: the model “answers” using its own training data when retrieval returned nothing relevant — the prompt must explicitly say “if context does not contain the answer, say so.”
- Evaluator last — because it needs all four upstream stages to produce the (question, answer, contexts) triple it scores. Contract: in is the triple plus an optional ground-truth answer; out is per-metric scores. Constraint: wrap every Ragas call in a try/skip with structured logging — the framework returns
NaNif the LLM judge emits invalid JSON, and there is no graceful fallback in 0.4.x.
For each component, your context document must specify what it receives, what it returns, what it must NOT do, and how it handles failure. Without that, the AI tool will silently merge concerns — and you will spend a week debugging why the reranker is calling the LLM directly.
Step 4: Validate with Ragas Before You Trust the Pipeline
Validation is not “ask three questions and read the answers.” It is automated metric collection over a fixed eval set, run on every spec change.
Validation checklist:
- Faithfulness check — failure looks like: the answer contains claims that the retrieved context does not support, even when retrieval returned the right chunks. Per Ragas Docs, faithfulness measures whether generated claims are grounded in retrieved context. It does NOT tell you whether the retrieved context is correct, current, or relevant — that is a different metric.
- Context Precision check — failure looks like: relevant chunks are present but ranked too low, drowned by noise. This points at the reranker, not the LLM.
- Context Recall check — failure looks like: relevant chunks never made it into the candidate set at all. This points at the retriever, the chunk size, or the embedding model.
- Answer Relevance check — failure looks like: the answer is grounded in the context but does not actually address the question. Often a prompt template problem at the generator stage.
- NaN check — failure looks like: a metric returns NaN with no error. Wrap every eval call with retry/skip logic and log the raw judge output. Silent NaNs are how regression sneaks into production.
The four Ragas metrics map cleanly to the four upstream stages. If your faithfulness drops, look at the generator. If your context precision drops, look at the reranker. If your context recall drops, look at the retriever and the chunking. That diagnostic mapping is the whole point of decomposing the system in Step 1.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Asked the AI to “build a RAG pipeline” in one shot | Too many concerns — the AI picked an old LCEL example and hardcoded rerank-v3.5 | Decompose into five components first; spec the stack contract per Step 2 |
Used langchain_community.vectorstores.Qdrant | Deprecated import path — code runs today, breaks on the next LangChain upgrade | Pin langchain-qdrant ≥1.1; import QdrantVectorStore from langchain_qdrant |
| Skipped the sparse encoder | Dense-only retrieval misses exact-match terms — SKUs, error codes, IDs | Use RetrievalMode.HYBRID with FastEmbed sparse out of the box; fuse via RRF k=60 |
Stuck with rerank-v3.5 because the tutorial used it | Tutorial pre-dates 11 December 2025 — Rerank 4 is the current generation | Default to rerank-v4.0-pro; reserve rerank-v3.5 as previous-gen fallback only |
| Treated Ragas NaN scores as zeros | LLM judge returned invalid JSON; framework has no graceful fallback in 0.4.x | Wrap eval calls in retry/skip with structured logging; track NaN rate as its own metric |
Pro Tip
Five components, five contracts. Every time you change one — new chunk size, new reranker model, new prompt template — write the change down as a spec delta and re-run Ragas on a fixed eval set before you ship. The pipeline is not the chain. The pipeline is the spec, and the chain is what the AI generates when the spec is good enough.
The reason production RAG fails so often in the field is not that the components are hard. It is that teams run the components together as one undifferentiated blob and then debug the blob. Spec each component. Validate each component. Then compose.
Frequently Asked Questions
Q: How to build a production RAG pipeline with LangChain and a vector database in 2026?
A: Decompose into five components — index, retriever, reranker, generator, evaluator — and pin the stack: LangChain 1.x with LangGraph runtime, langchain-qdrant ≥1.1 against Qdrant ≥1.10 in RetrievalMode.HYBRID, Cohere Rerank 4, Ragas 0.4.3. The same five-contract architecture works if you swap Qdrant for
Pinecone or LangChain for
LlamaIndex — the components stay the same, only the package names change. Watch for the deprecated langchain_community.vectorstores.Qdrant import; add a CI check that fails the build if anyone re-introduces it.
Q: How to add reranking and Ragas evaluation to a RAG system step by step?
A: Wire the reranker after retrieval and Reciprocal Rank Fusion — never as the retriever itself — using rerank-v4.0-pro for quality or rerank-v4.0-fast for latency. Then wrap your generator output with Ragas Faithfulness, Context Precision, Context Recall, and Answer Relevance over a fixed eval set. The watch-out: Ragas 0.4.x returns NaN when the LLM judge emits invalid JSON, with no built-in fallback. Track NaN rate as its own metric so silent regressions surface early.
Q: When should you choose RAG over fine-tuning an LLM? A: Choose RAG when knowledge changes, freshness matters, or you need question-answering over private documents. Choose fine-tuning when behavior, format, or style must change — RAG cannot teach a model a new tone. The current enterprise default is hybrid: RAG for the knowledge layer, light supervised fine-tuning for behavior (IBM Think). The trap is fine-tuning a model on facts that update weekly; you will repeat the train cycle every week.
Q: How to use RAG for enterprise document Q&A in 2026? A: Treat the corpus as governed data first. Per IBM Think, well-governed corpora retrieve at 85–92% accuracy while ungoverned ones drop to 45–60% — and the Gartner projection of around 80% RAG-project failure by 2026 is mostly traced back to data-quality issues. Practical: enforce metadata schemas, version your chunking strategy alongside the documents, and add per-tenant filters at the retriever stage. Never hand a RAG system a document store nobody owns.
Your Spec Artifact
By the end of this guide, you should have:
- A five-box pipeline diagram naming index, retriever, reranker, generator, and evaluator — each with explicit inputs, outputs, and forbidden behaviors.
- A pinned stack contract: LangChain 1.x with LangGraph,
langchain-qdrant≥1.1, Qdrant server ≥1.10, Cohere Rerank 4 (Pro or Fast SKU), Ragas 0.4.3. - A validation plan that maps each Ragas metric to the pipeline stage it diagnoses, with NaN handling specified.
Your Implementation Prompt
Drop this prompt into your AI coding tool of choice (Claude Code, Cursor, Codex). Fill the bracketed placeholders with your project values. The prompt encodes the five-component decomposition from Step 1, the stack contract from Step 2, the build order from Step 3, and the validation step from Step 4 — so the AI has no excuse to merge concerns or default to deprecated imports.
Build a production RAG pipeline for [project name / domain] using the following five-component architecture.
Stack contract — pin exactly:
- Framework: LangChain 1.x with LangGraph runtime (do NOT use deprecated LCEL-only patterns from 0.x).
- Vector store package: langchain-qdrant >=1.1 (import: `from langchain_qdrant import QdrantVectorStore`). Do NOT use `langchain_community.vectorstores.Qdrant` — it is deprecated.
- Vector store server: Qdrant >=1.10 (Query API required for hybrid).
- Retrieval mode: RetrievalMode.HYBRID, dense + sparse via FastEmbed, fused via Reciprocal Rank Fusion at k=60.
- Reranker: Cohere Rerank 4 — model = "[rerank-v4.0-pro OR rerank-v4.0-fast]" via /v2/rerank. The `model` parameter is required; use `max_tokens_per_doc` (NOT the deprecated `max_chunks_per_doc`).
- Evaluator: Ragas 0.4.3 with Faithfulness, Answer Relevance, Context Precision, Context Recall.
Components — implement in this order, each as a separate function/module with its own contract:
1. Index ingestion: input = documents from [your data source]; output = dense + sparse vectors written to Qdrant collection "[collection name]". Chunk size = [your tokens]. Metadata schema = [your fields]. Constraint: no LLM call in this layer.
2. Retriever: input = (query: str, top_k: int); output = list of (chunk, dense_score, sparse_score). Use HYBRID + RRF. Constraint: no rerank in this layer.
3. Reranker: input = (query, candidates from step 2); output = reordered candidates with cross-encoder scores. Constraint: never used as the primary retriever.
4. Generator: input = (question, top_n reranked chunks); output = (answer, citation_map). Prompt template MUST instruct: "If the provided context does not contain the answer, say so explicitly — do not answer from prior knowledge."
5. Evaluator: input = (question, answer, contexts, optional ground_truth); output = per-metric scores. Wrap every Ragas call in a try/except with retry/skip on NaN — log the raw judge output. Track NaN rate as its own metric.
Failure modes I want explicit handling for:
- Empty embeddings on [edge-case document type, e.g., very short docs, multi-hundred-page PDFs, non-text PDFs].
- Retriever returns zero candidates → generator must fall through to "no answer in context."
- Reranker timeout → fall back to retriever order, do NOT silently drop the request.
- Ragas judge returns NaN → log + skip, do NOT default to zero.
Do NOT generate a single end-to-end chain. Generate five separate units with the contracts above, plus a thin LangGraph orchestrator that wires them.
Ship It
You now have a pipeline that decomposes cleanly into five owned components, a stack contract that survives a dependency upgrade, and a validation harness that tells you which component regressed when something breaks. That is what production RAG looks like in 2026 — not one chain, but five contracts and a way to measure each one.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors