Persistent Memory for AI Agents: Mem0 vs Letta vs Zep (2026)
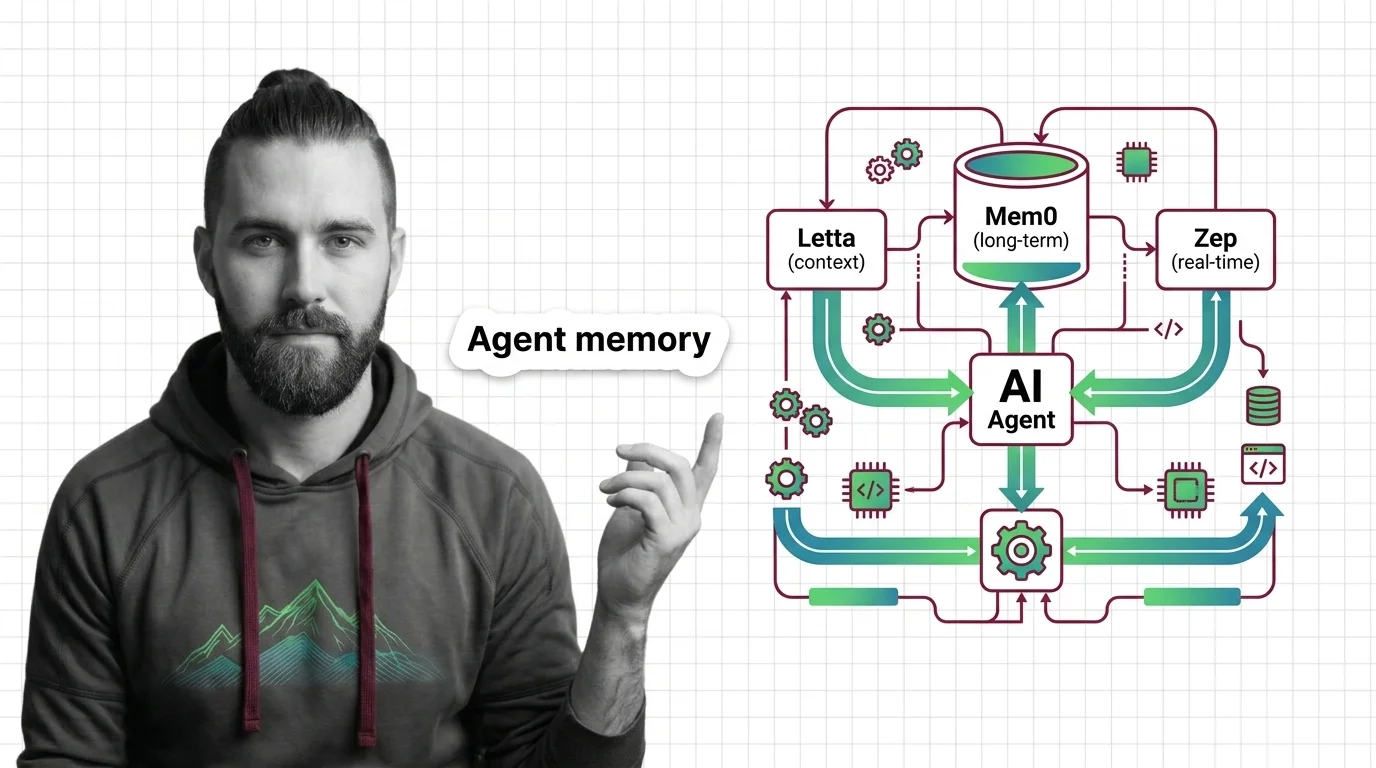
Table of Contents
TL;DR
- Memory is not one thing. It is at least three jobs — write, recall, forget — and the tool you pick has to do all three or it does not count as memory.
- The hard part is not the storage. It is specifying what counts as a memory in the first place. Skip that step and your agent remembers garbage forever.
- Mem0, Letta, and Zep solve different shapes of the same problem. Pick by deployment posture and writer model, not by benchmark leaderboards you cannot reproduce.
A support agent ships on a Tuesday. It greets returning users by name, recalls their last ticket, picks up the thread. Two weeks in, the same user asks about their refund. The agent confidently quotes a policy that changed six months ago — extracted, stored, and never forgotten. The retriever found the memory. The memory was wrong. Nobody specified what should expire and what should not.
That is the failure shape this guide is built around — and it is what an Agent Memory Systems stack is supposed to prevent.
Before You Start
You’ll need:
- A working agent loop (LLM call + tool use) you can wrap with a memory client
- Familiarity with the difference between Episodic Memory (events) and semantic memory (facts) — they need different retention rules
- A clear answer to “whose memory is this?” (one user, one workspace, or one shared knowledge base)
- Python or TypeScript runtime, plus a vector store you control or a managed plan with one of the three vendors
This guide teaches you: how to decompose agent memory into surfaces, contracts, and a build order — so the tool you pick does what your agent actually needs, not what the marketing page promised.
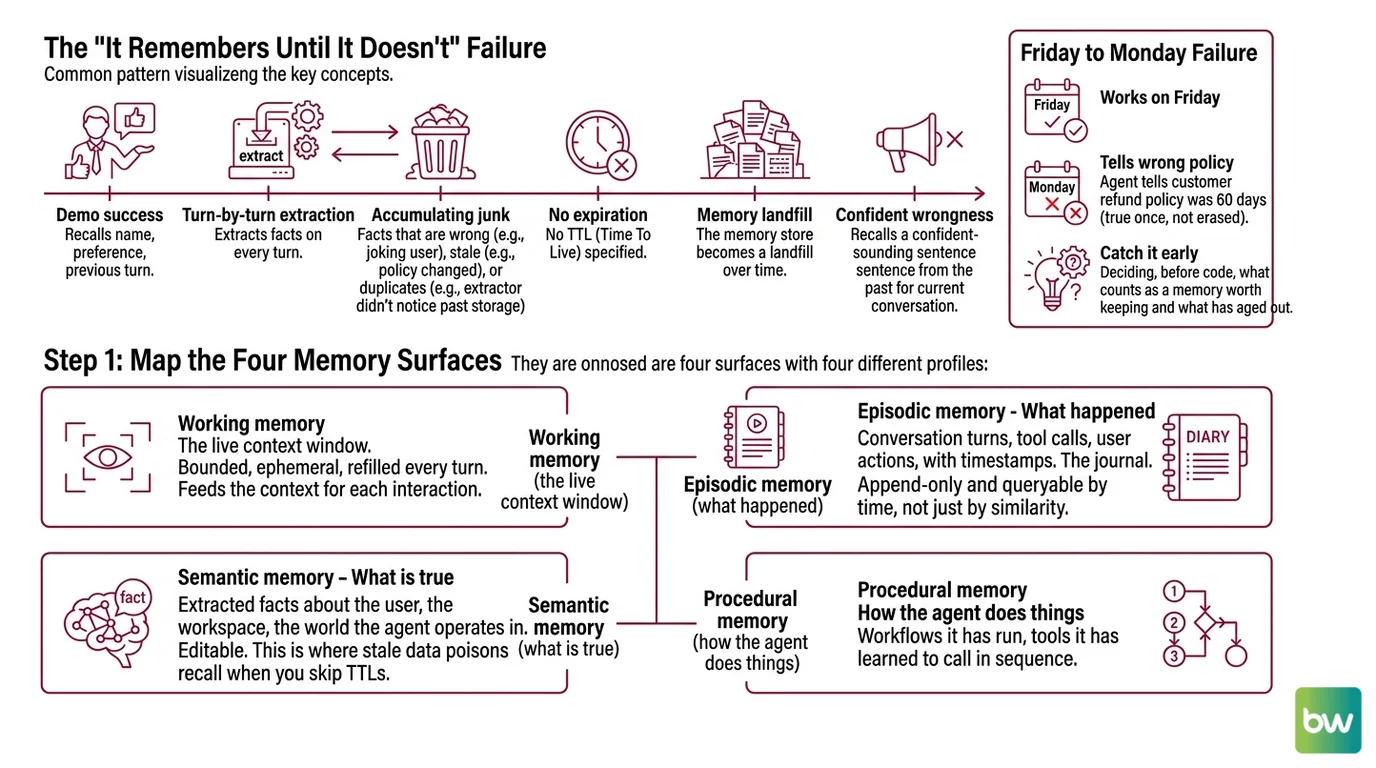
The “It Remembers Until It Doesn’t” Failure
Most agent memory systems fail in the same direction. They are good at the demo — the agent recalls a name, a preference, a previous turn — and they are bad at the part that ships. The bad part has a pattern.
The agent extracts facts on every turn. Some facts are wrong because the user was joking. Some are stale because the policy changed. Some are duplicates because the extractor did not notice it had already stored that fact yesterday. None of them ever expire because nobody specified a TTL. Six weeks later the memory store is a landfill, and the recall step pulls a confident-sounding sentence from 2024 into a conversation about today.
It worked on Friday. On Monday, the agent told a customer its refund policy was 60 days because that was true once and nothing has erased it.
You will not catch this by reading a few demos. You catch it by deciding, before any code is written, what counts as a memory worth keeping — and what counts as one that has aged out.
Step 1: Map the Four Memory Surfaces
Agent memory is not a database. It is four surfaces with four different write rules, four different recall patterns, and four different decay profiles. Decompose before you specify, or you will end up with one tool trying to do three jobs and doing none of them well.
Your system has these parts:
- Working memory — the live context window. Bounded, ephemeral, refilled every turn. Not a memory layer; it is what the memory layer feeds.
- Episodic memory — what happened. Conversation turns, tool calls, user actions, with timestamps. The journal. Should be append-only and queryable by time, not just by similarity.
- Semantic memory — what is true. Extracted facts about the user, the workspace, the world the agent operates in. Editable. This is where stale data poisons recall when you skip TTLs.
- Procedural memory — how the agent does things. Workflows it has run, tools it has learned to call in sequence, prompt patterns that worked. Often missing in V1 systems and often the difference between an agent that improves and one that just runs.
The other axis worth naming up front: who writes the memory? MemGPT — the original 2023 paper from Berkeley, now the design pattern behind Letta — argued the LLM itself should manage its memory through function calls (Letta Blog). Mem0 takes the opposite stance: a separate extraction pipeline writes memory while the agent is busy answering. Zep, built on the open-source Graphiti temporal knowledge graph (Zep’s GitHub repository), sits in between — the agent emits messages, the platform builds a temporal graph in the background.
That choice is more consequential than the storage backend. It determines who pays the latency cost, who decides what is worth remembering, and who you blame when memory is wrong.
The Architect’s Rule: If you cannot say which surface a fact belongs in, you cannot say when it should be forgotten.
Step 2: Specify What Counts as a Memory
This is the step everyone skips, and it is the step every memory bug traces back to. Before you install any SDK, write the contract.
Context checklist:
- Definition of a memory. Is a memory a raw turn, an extracted fact, a summary, or all three? Mem0 stores extracted facts by default. Letta stores raw recall plus an LLM-curated archive. Zep stores temporal episodes plus an evolving knowledge graph. Each definition implies a different downstream surface area.
- Identity scope. Is memory keyed by
user_id, byagent_id, by(user_id, workspace_id), or by something else? Cross-contamination between scopes is the second-most-common bug after stale data. - Source of truth. When the extractor and the user disagree, who wins? “User said their address is X” versus “user later corrected to Y” must have a deterministic resolution rule. Zep’s graph encodes contradictions as edges; Mem0 updates facts in place. Pick the model that matches your risk tolerance.
- Recall trigger. Pull memories on every turn, only when the LLM asks, or via a heuristic? Letta gives the model function calls and lets it decide. Mem0 expects you to call
search()before the prompt. The choice changes your latency profile by hundreds of milliseconds. - Forgetting policy. TTL per memory type. Preferences live longer than tickets. Tickets live longer than tool errors. Without a policy, the recall step degrades faster than your eval set can detect.
- Privacy and deletion path. A user asks to be forgotten. Can you delete every record across episodic, semantic, and procedural surfaces in one call? If not, document the gap before you ship.
The Spec Test: If two engineers on your team would extract a different memory from the same user turn, your memory layer will be inconsistent in exactly that way. Write the extraction rule down before you wire the SDK.
Step 3: Pick the Stack and Wire in Order
The vendor choice is downstream of Step 1 and Step 2. Once you know which surfaces you need and who writes them, the field narrows fast.
Pick by deployment posture, not benchmark:
- Mem0 — managed extraction layer on top of your own LLM. Fastest path to a working memory layer if you already have an agent and just want recall. The Hobby tier is $0/mo with 10,000 add requests and 1,000 retrieval requests per month; Pro is $249/mo and unlocks graph memory and multi-project support (Mem0’s pricing page). Self-host via OpenMemory if you need on-prem, but you lose the managed extraction engine and graph memory in that mode (Mem0 Blog).
- Letta — full stateful-agent framework, not just a memory store. Pick this if you want the LLM itself to manage its memory through function calls and you are building the whole agent on Letta’s runtime. Pro is $20/mo for personal use; the API plan for teams is $20/mo base plus $0.10 per active agent per month and metered tool execution (Letta’s pricing page). Self-hosting is free on your own infrastructure (Letta Docs). Letta V1, released in 2026, is the recommended runtime for frontier reasoning models — older MemGPT-pattern code targeting the classic API may need updates (Letta Blog).
- Zep — enterprise-positioned temporal knowledge graph. Pick this when contradictions, audit, and time-aware recall matter more than per-request cost. The Free tier is $0/mo with 1,000 credits and no rollover; Flex is $125/mo for 50,000 credits; Flex Plus is $375/mo for 200,000 credits, where one credit covers a 350-byte episode (Zep’s pricing page). Enterprise adds SOC 2 Type II, HIPAA BAA, and BYOK/BYOM/BYOC deployment options.
- Byterover — local-first CLI for individual developers. Markdown context-tree architecture, no vector DB needed (Byterover Docs). Useful as a side option if your “agent” is your IDE, not a deployed system.
Build order:
- Identity scope first. Decide and lock the key —
user_id,(user_id, agent_id), or whatever shape you need. Hard-code it into every write and read. Changing this later means a migration. - Write path second. Wire the extractor or the LLM-managed memory function. Log every write to a flat file for the first week so you can audit what is being stored before you trust it.
- Recall path third. Inject memories into the prompt. Start with top-k similarity; add temporal filters or graph traversal only when similarity alone fails on your eval set.
- Forgetting last. Apply TTLs and contradiction resolution after you have real data to look at. Forgetting policy designed against zero memories is always wrong.
For each layer, your context must specify:
- Inputs: what artifact the layer consumes (user turn, tool result, system event)
- Outputs: what it produces (memory record, embedding, graph edge)
- Failure mode: what happens when the layer errors — pass through, drop the turn, fail the request — pick one and document it
- Cost ceiling: writes are usually cheap; recall on every turn is the hidden bill. Budget per-request latency and per-month credits before you turn it on.
Step 4: Prove It Actually Remembers
A memory system you never test is a feature flag with extra steps. The validation step is where you prove the surfaces from Step 1 actually behave the way Step 2 said they would.
Validation checklist:
- Long-horizon recall test — run your agent through a multi-session conversation where the answer to a later question depends on a fact stated three sessions earlier. The LongMemEval dataset is built for exactly this — 500 curated questions across long chat histories, evaluating five abilities including multi-session reasoning and knowledge updates (LongMemEval project page). Failure looks like: the agent answers from training data instead of from memory, which means recall did not fire.
- Contradiction handling — feed two contradictory facts about the same entity in different turns. Verify the system either resolves to the latest fact, flags both, or asks the user — whichever your Step 2 spec said. Failure looks like: both facts coexist in recall and the LLM picks one at random.
- Forgetting test — store a fact with a 24-hour TTL, advance the clock, query again. Failure looks like: the fact is still there, which means your TTL is documentation, not behavior.
- Cross-user isolation — query as User B for a memory written by User A. Failure looks like: any leakage at all. This is a privacy bug, not a quality bug.
- Custom micro-eval — pick 30 representative interactions from your domain, write expected memory state after each, and grade your stack against your own truth. Vendor benchmarks are useful directionally; your eval is what tells you whether to ship.
Compatibility & freshness notes:
- Letta V1 vs MemGPT classic: Both are still supported, but Letta V1 is the recommended runtime for GPT-5 and Claude 4.5 Sonnet. Tutorials and code targeting the classic MemGPT agent API may need updates (Letta Blog).
- Mem0 graph memory paywall: Graph memory — entities and relationships across conversations — is Pro-tier only, $249/mo and up (Mem0’s pricing page). Older blog posts that show graph memory on the free tier are out of date.
- Zep credit-based pricing: As of 2026, Zep charges per processed episode (350 bytes per credit), not per message. Older “per-message” pricing references are stale (Zep’s pricing page).
- Locomo Benchmark numbers are vendor-disputed. Mem0, Zep, Letta, and Supermemory all publish self-reported scores using different methodologies. Treat any single ranking as directional, not definitive — and run your own eval before deciding.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Picked the tool with the highest LOCOMO score | Vendors publish self-reported scores with different methodologies — the ranking does not reproduce on your data | Run your own micro-eval on representative interactions; treat vendor numbers as directional |
| Stored every turn as a memory | The recall step starts pulling tool errors and small talk into the prompt, drowning the useful facts | Define what counts as a memory in Step 2; let the extractor reject the rest |
| No TTL on extracted facts | Stale preferences and outdated policies stay in recall forever, then surface confidently months later | Set a per-surface TTL — preferences long, tickets short, tool errors shortest |
| Ignored cross-user scope on the storage key | One user’s fact recalled in another user’s session — privacy incident, not a quality bug | Lock identity scope first in the build order; assert it in every read and write |
| Treated Mem0, Letta, and Zep as interchangeable | They solve different shapes — extractor service, full agent runtime, temporal graph platform | Pick by deployment posture and writer model, then check pricing fits your traffic |
| Skipped a deletion path | A user asks to be forgotten and you cannot do it in one call across all surfaces | Add a delete_user(user_id) operation that walks every surface; test it before you need it |
Pro Tip
Write the memory eval set before you pick the SDK. Thirty interactions with expected memory state — what should be stored, what should be forgotten, what should be retrievable in three turns — outlasts every vendor migration. Tools come and go. Mem0 just paywalled graph memory. Letta rebuilt its agent loop into V1. Zep moved to credit-based pricing. The thirty examples that define what memory means for your product survive all of it. Treat them as the spec, not the test.
Frequently Asked Questions
Q: How to implement agent memory step by step in 2026? A: Decompose into four surfaces (working, episodic, semantic, procedural), specify what counts as a memory and how it expires, then wire identity → write → recall → forget in that order. The watch-out: pick the writer model (LLM-managed function calls versus a separate extractor) before the storage backend — that decision is harder to reverse than swapping vector stores.
Q: How to use Mem0 to add long-term memory to an AI agent?
A: Wrap your existing agent loop with Mem0’s add() after each turn and search() before each prompt; the managed extraction pipeline writes facts asynchronously. The watch-out: Mem0’s graph memory — entities and relationships across conversations — is Pro-tier and above only at $249/mo (Mem0’s pricing page), so plan-tier plain vector recall is what the free and Starter tiers actually deliver.
Q: When should you use Letta vs Zep for agent memory? A: Pick Letta when the LLM itself should manage its memory via function calls and you are building the whole agent on a single runtime; pick Zep when you need temporal reasoning, contradiction handling, and enterprise compliance (SOC 2, HIPAA BAA) on top of an existing agent. The watch-out: Zep’s open-source Graphiti engine is not the same product as the managed Zep platform — do not benchmark one and deploy the other (Zep’s GitHub repository).
Your Spec Artifact
By the end of this guide, you should have:
- A memory surface map naming which of episodic, semantic, procedural, and working you actually need
- A memory contract specifying definition, identity scope, source of truth, recall trigger, forgetting policy, and deletion path
- A validation plan with one explicit test per surface and a documented failure symptom for each
Your Implementation Prompt
Paste the prompt below into Claude Code, Cursor, or Codex when you are ready to wire memory into your agent. The bracketed placeholders are the decisions you made in Step 2 — fill them in before sending.
You are wiring a persistent memory layer into an existing AI agent.
Follow this spec exactly. Do not invent surfaces.
## Stack
- Memory provider: [mem0 | letta | zep — pick one based on Step 3]
- Vector store: [provider's default | byok — specify which]
- LLM: [your model] — used by the agent loop, not for extraction unless letta
## Surfaces (only the ones we need)
- Episodic: [yes | no] — append-only event journal
- Semantic: [yes | no] — extracted facts about the user/workspace
- Procedural: [yes | no] — workflow patterns the agent has used
## Memory contract (from Step 2)
- A memory is: [extracted fact | raw turn | summary | combination]
- Identity scope: [user_id | (user_id, workspace_id) | other]
- Source of truth on conflict: [latest wins | flag both | ask user]
- Recall trigger: [every turn | LLM-decided function call | heuristic]
- TTL per surface: episodic=[days], semantic=[days], procedural=[days]
- Deletion path: a single delete_user(user_id) call walks every surface
## Build order (do not reorder)
1. Lock the identity-scope key in storage; assert it in every read/write
2. Wire the write path; log every memory written to a flat audit file
3. Wire the recall path; inject top-k results into the system prompt
4. Apply TTLs and contradiction resolution last, against real data
## Constraints
- Do not modify the existing agent prompt logic; only wrap it
- All memory operations must be togglable via env var (MEMORY_ENABLED)
- Add one integration test per surface using the Validation Checklist
in Step 4 (long-horizon recall, contradiction, forgetting, cross-user)
## Validation
- Run the long-horizon recall test from Step 4 and confirm the agent
recalls a fact stated three sessions earlier
- Run the cross-user isolation test and confirm zero leakage
- Run the forgetting test by setting a 24-hour TTL and advancing the clock
Ship It
You now have a way to talk about agent memory as four distinct surfaces with four different rules, and a way to pick a vendor by what they actually do rather than by the leaderboard slot they paid to claim. The spec — surfaces, contract, build order, validation — is the part that will outlast the next round of mergers and version bumps. The next time someone says their framework “solves agent memory,” you will know which of the four surfaces they mean and which three they forgot.
Pricing note: Tier prices and credit allocations cited above are current as of writing (May 2026). Always check the provider’s pricing page before encoding a cost ceiling into your spec.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors