How to Build a Neural Network Language Model from Scratch with PyTorch in 2026

Table of Contents
TL;DR
- A neural network language model has four components — embedding, hidden layers, output projection, and training loop. Specify each one separately.
- Your AI coding tool needs exact tensor shapes, optimizer choice, and loss function before it writes a single line.
- Validation means watching the loss curve and checking that gradients flow — not just confirming it runs.
You asked your AI coding tool to build a character-level language model in PyTorch. It produced something that compiled, ran for 50 epochs, and predicted the letter “e” for every input. The architecture looked reasonable. The training loop executed without errors. But the model never learned a thing — because your specification never defined what “learning” should look like.
Before You Start
You’ll need:
- An AI coding tool — Claude Code, Cursor, or Codex
- Working knowledge of Neural Network Basics for LLMs and how Backpropagation updates weights
- PyTorch 2.11.0 installed with Python 3.10 or higher
- A plain text file as your training corpus — Shakespeare, server logs, anything with repeating patterns
This guide teaches you: how to decompose a neural network language model into four specification layers so your AI tool generates an implementation that actually learns — not one that merely runs.
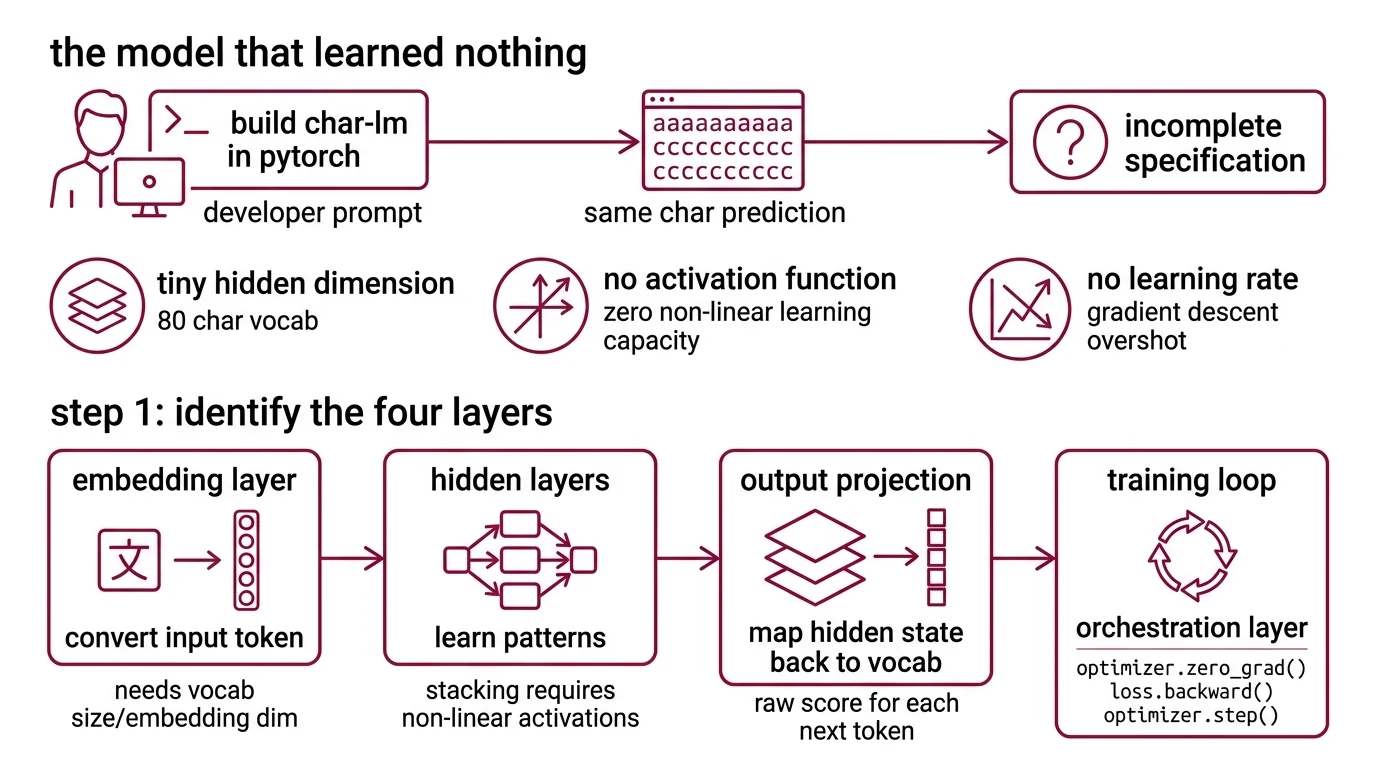
The Model That Learned Nothing
A developer prompted their AI tool: “Build me a character-level language model in PyTorch.” The tool delivered. Clean class structure. Readable code. It even ran.
Fifty epochs later, every prediction was the same character. The model converged on the most frequent token and stayed there.
The code wasn’t broken. The specification was incomplete. No hidden dimension specified — the AI picked a tiny layer for a vocabulary of 80 characters. No Activation Function specified — the network was a stack of linear transformations with zero capacity to learn non-linear patterns. No learning rate named — Gradient Descent overshot on every update.
Three missing constraints. One useless model.
Step 1: Identify the Four Layers
Every neural network language model — from a toy character predictor to the architecture underneath GPT — decomposes into the same four concerns. Your spec needs to treat each one as a separate build target.
Your system has these parts:
- Embedding layer — converts each input token (character or word) into a dense vector. This is where raw text becomes something the math can operate on. The AI needs your vocabulary size and embedding dimension to build it correctly.
- Hidden layers — where the model learns patterns. These transform embedded inputs through weighted connections and non-linear activations. Without activation functions between layers, stacking does nothing — it is still a single linear operation, no matter how many layers you add.
- Output projection — maps the hidden state back to vocabulary size. The output is a raw score for every possible next token. These scores become a prediction after softmax.
- Training loop — the orchestration layer. Feeds data in, computes loss, runs backpropagation, updates weights. Every training loop in PyTorch follows the same three-call sequence:
optimizer.zero_grad(),loss.backward(),optimizer.step()(PyTorch Docs).
The Architect’s Rule: If you can’t describe each layer’s input shape, output shape, and failure mode — your AI tool will guess. And it will guess wrong.
Step 2: Specify Every Constraint the AI Won’t Guess
This is where most specifications fall apart. The developer describes what to build but not the constraints that determine whether it works.
Context checklist for your AI tool:
- Vocabulary size — count unique tokens in your corpus. Character-level models typically have a small vocabulary. Word-level models have a large one. This number sets the embedding input dimension and the output layer width.
- Embedding dimension — the vector size the hidden layers will work with. Start small and scale up as needed.
- Hidden dimension — too small and the model can’t represent the patterns in your data. Too large and training becomes unstable on limited hardware. Start moderate and adjust based on loss behavior.
- Number of hidden layers — begin with one or two. Each additional layer increases capacity but risks the Vanishing Gradient problem unless you specify a modern activation. Sigmoid’s maximum derivative is 0.25 — gradients decay exponentially through deep layer stacks.
- Activation function — specify ReLU for hidden layers. It keeps gradients alive during backpropagation by passing positive values unchanged. Without this line in your spec, the AI might default to sigmoid or skip activation entirely.
- Loss function —
Cross Entropy Loss is the right pick for language modeling. In PyTorch,
nn.CrossEntropyLosscombines LogSoftmax and NLLLoss in one operation (PyTorch Docs). Do not add a separate softmax to your output layer — the loss function handles it internally. - Optimizer — Adam Optimizer with decoupled weight decay (AdamW) is the default for virtually every transformer and most neural network training in 2026 (Let’s Data Science). Default hyperparameters: lr=0.001, betas=(0.9, 0.999), weight_decay=0.01 (PyTorch Docs). The decoupled weight decay design separates regularization from the gradient update — a distinction that matters once your model grows past toy scale (Loshchilov & Hutter).
- Sequence length — how many tokens of context the model sees at once. Pick a window that captures the patterns in your data without exceeding your memory budget.
The Spec Test: If your context doesn’t name the activation function, the AI might skip it. A network with no activation between layers is an expensive linear regression — it will never learn the character sequences in your text.
Step 3: Wire Embedding to Output
Order matters. Each component depends on the one before it. Tell your AI tool to build in this sequence.
Build order:
- Embedding layer first — no dependencies. Takes vocabulary size and embedding dimension. This is the foundation everything else reads from.
- Hidden layers second — take the embedding dimension as input. Specify the activation function between each pair of layers. Name the non-linearity explicitly.
- Output projection third — maps hidden dimension to vocabulary size. Do not add softmax here — CrossEntropyLoss handles it internally.
- Training loop last — wires everything together. Specify the optimizer, learning rate, number of epochs, and batch size.
For each component, your specification must include:
- What tensor shape it receives
- What tensor shape it returns
- What it must NOT do (e.g., output layer must not apply softmax)
- How to handle shape mismatches (fail loud — no silent reshaping)
Compatibility notes:
- TorchScript: Deprecated in PyTorch 2.10+. If your AI tool generates TorchScript export code, reject it. Use
torch.exportfor model deployment instead.- torch.load: The
weights_onlydefault parameter changed in recent PyTorch releases for security. Specifyweights_only=Trueexplicitly when loading saved models.
Step 4: Prove the Model Learned
Running without errors is not validation. Your model needs to demonstrate that it learned patterns from the data.
Validation checklist:
- Loss decreasing over epochs — plot the training loss. It should drop steeply early, then flatten. If it stays flat from epoch one, the learning rate is wrong or gradients aren’t flowing. Failure looks like: loss stuck at the same value after the first batch.
- Gradient norms are non-zero — check every layer after
.backward(). Zero gradients in early layers means vanishing gradients are active. Failure looks like: first-layer gradient norm at or near zero. - Sample outputs show variety — generate text every few epochs. Early outputs will be random — that’s fine. They should be different randomness. If every sample produces the same character string, the model collapsed to the most common token. Failure looks like: “eeeeeee” on repeat.
- Overfitting on tiny data works — feed the model a small fragment of your corpus and train for many epochs. It should memorize that fragment perfectly. If it can’t overfit tiny data, the architecture has a bug. This is your sanity check before scaling up.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| “Build me a language model” | Too many unspecified concerns — AI guessed every hyperparameter | Decompose into four layers, specify each separately |
| No activation function named | AI generated linear-only layers with no capacity for non-linear patterns | State “ReLU activation between hidden layers” explicitly |
| Softmax in output layer + CrossEntropyLoss | Double softmax collapses gradients to near-zero | Specify raw logits as output — CrossEntropyLoss applies softmax internally |
| No learning rate given | Default may be too aggressive or too conservative for your architecture | Specify lr=0.001 for AdamW as starting point, adjust based on loss curve |
Pro Tip
Every neural network you specify follows this same decomposition: embedding, transformation, projection, training loop. The vocabulary changes. The layer types change. The loss function might change. But the four-layer specification pattern stays constant. Master it once and you have a reusable framework for every architecture — from character predictors to sequence-to-sequence systems.
Frequently Asked Questions
Q: How to build a simple neural network for language modeling in PyTorch step by step? A: Decompose into four layers — embedding, hidden, output projection, training loop — and specify constraints for each before your AI tool writes code. Start character-level with a small corpus. Name ReLU, CrossEntropyLoss, and AdamW explicitly. The step most skip: tensor shapes at every layer boundary so dimensions align.
Q: How to train a character-level language model with PyTorch in 2026?
A: Use PyTorch 2.11 with torch.compile for a training speedup of 20-50% on supported hardware (PyTorch Blog). Feed text as character indices and predict the next character each step. Key detail not covered above: shuffle training sequences between epochs — otherwise the model memorizes input order instead of learning character-level patterns.
Q: How to choose between SGD, Adam, and AdamW optimizers for neural network training? A: Default to AdamW — it decouples weight decay from gradient updates for more stable training. SGD with momentum can generalize better on narrow tasks but demands careful learning rate scheduling. Original Adam couples regularization with adaptive rates. For production-grade neural network training in 2026, AdamW is the standard starting point.
Your Spec Artifact
By the end of this guide, you should have:
- Architecture map — four layers with tensor shapes, activation functions, and dependencies documented
- Constraint checklist — vocabulary size, dimensions, optimizer, loss function, hyperparameters specified
- Validation criteria — loss curve behavior, gradient norms, sample output diversity, tiny-data overfitting test
Your Implementation Prompt
Copy this into Claude Code, Cursor, or your AI tool. Replace the bracketed values with your constraints from Step 2.
Build a character-level neural network language model in PyTorch 2.11 with these specifications:
DATA:
- Training corpus: [path to your text file]
- Vocabulary: all unique characters in the corpus
- Sequence length: [your context window size]
ARCHITECTURE (build in this order):
1. Embedding layer: vocab_size -> [your embedding dimension]
2. Hidden layers: [number of layers] layers, [your hidden dimension] neurons each, ReLU activation between layers
3. Output projection: hidden_dim -> vocab_size (raw logits, NO softmax)
TRAINING:
- Loss: nn.CrossEntropyLoss (handles softmax internally)
- Optimizer: AdamW with lr=[your learning rate], weight_decay=[your decay value]
- Epochs: [your epoch count]
- Batch size: [your batch size]
- Use torch.compile for training speedup
VALIDATION (implement all four):
1. Print training loss every epoch — must decrease over time
2. Print gradient norms for each layer periodically — must be non-zero
3. Generate a sample text periodically — must show increasing variety
4. Include a flag to test overfitting on a small text fragment
CONSTRAINTS:
- Do NOT add softmax to the output layer
- Do NOT use TorchScript — use torch.export if export is needed
- Fail loudly on tensor shape mismatches — no silent reshaping
- Use weights_only=True for any torch.load calls
Ship It
You now have a four-layer decomposition for any neural network language model. Embedding, hidden layers, output projection, training loop — each specified with exact shapes and constraints. The AI tool stops guessing. The model starts learning. That’s the difference between code that runs and code that works.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors