Multimodal Pipeline 2026: LLaVA, Llama 3.2 Vision & Gemini 3.1 Pro
TL;DR
- Every Multimodal Architecture system is three layers: vision encoder, connector, LLM backbone. Spec each one or the whole thing fails at the boundary.
- Hosted vs open-source is not a cost decision. It is a control decision — who owns the encoder, the tokenizer, and the failure modes.
- Validate at every seam: image-in, embedding-out, token-in, text-out. If any boundary is silent, you are shipping a black box.
You pick a vision-language model because a benchmark screenshot looked good. You drop it behind your existing chat stack. Monday morning a user uploads a high-resolution product diagram and the model answers like it is reading tea leaves. Nothing crashed. Everything is wrong.
The model is fine. Your pipeline is not. And this guide is going to fix it.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex) for specification-assisted implementation
- Working knowledge of Vision Transformer encoders and standard text-only LLM serving
- A concrete use case — document Q&A, product search, visual RAG, or agent screenshot reasoning
This guide teaches you: how to decompose any multimodal system into three specifiable layers, so the model you pick is a consequence of the pipeline — not the starting point.
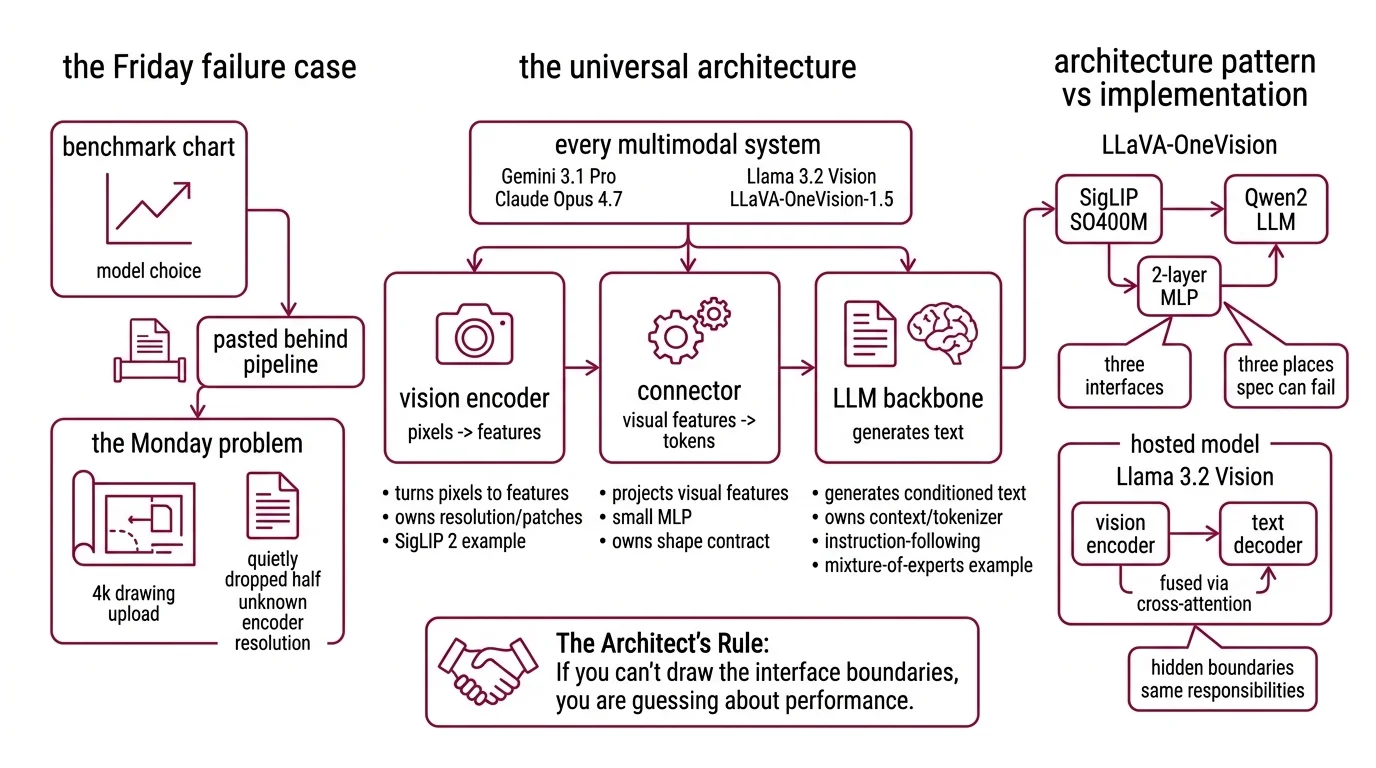
The Pipeline That Looked Fine on Friday
Teams pick a vision-language model because of a benchmark chart. They paste it behind an existing text pipeline. Nobody specifies which resolution the encoder handles, how images get tokenized, or how the connector passes features into the LLM. The first few demos look great. Then production hits.
It worked on Friday. On Monday, a customer uploaded a 4K architectural drawing and the model quietly dropped half the page — because the encoder’s resolution contract was never written down.
Step 1: Identify the Three Layers in Every Multimodal Stack
Every modern multimodal system — Gemini 3.1 Pro, Claude Opus 4.7, Llama 3.2 Vision, LLaVA-OneVision-1.5 — is the same three-layer pattern. The models differ in which layer they optimize. Your spec has to name all three, or you cannot reason about failure.
Your system has these parts:
- Vision encoder — turns pixels into features. Typically a frozen ViT like SigLIP 2. Owns resolution, patch size, and how images get split for high-res input.
- Connector — projects visual features into the LLM’s token space. Usually a small MLP. Owns the shape contract between vision features and language tokens.
- LLM backbone — generates text conditioned on the connector’s output. Owns context window, tokenizer, and instruction-following. Many hosted flagships use Mixture Of Experts routing underneath the API.
The LLaVA-OneVision architecture makes the pattern explicit: a SigLIP SO400M vision encoder feeds a 2-layer MLP connector, which feeds a Qwen2 LLM backbone (LLaVA-OneVision paper). Three components. Three interfaces. Three places the spec can go wrong.
Hosted models hide these boundaries behind one API, but the layers are still there. Llama 3.2 Vision uses a vision encoder feeding a text decoder with visual information fused via cross-attention (Hugging Face model card) — a different wiring, same three responsibilities.
The Architect’s Rule: If you can’t draw the pipeline in three boxes, the AI cannot route a single token through it.
Step 2: Lock Down the Contract for Each Layer
This is where vibe-coded multimodal builds fall apart. You specify the LLM backbone — context window, pricing, latency — and you leave the vision side as “images go in.” The coding tool fills the gap with assumptions from whatever example it saw last.
Context checklist:
- Vision encoder version and patch behavior. SigLIP 2, CLIP, or the vendor’s proprietary encoder? At what max resolution? Does it split into patches — LLaVA-OneVision uses AnyRes-9, cutting a high-res image into 9 patches (LLaVA-OneVision paper) — or downscale aggressively?
- Connector shape contract. How many features per image? For video, how are frames pooled — LLaVA-OneVision pools to 196 tokens per frame (LLaVA-OneVision paper). A 10-minute clip either blows the context window or degrades gracefully, depending on what the spec says.
- LLM tokenizer behavior. This is the silent one. Claude Opus 4.7 ships a new tokenizer that can produce up to 35% more tokens for the same text compared to Opus 4.6 (ALM Corp). Same prompt. Bigger bill. If your cost spec ignores the tokenizer, your ceiling ignores reality.
- Context-window regime. Gemini 3.1 Pro carries 2M tokens and prices differently past 200k (OpenRouter). Llama 3.2 Vision 90B stops at 128K (Hugging Face model card). Your spec names which regime you live in — or the bill writes it for you.
- Language coverage. Llama 3.2 Vision officially supports English, French, German, Hindi, Italian, Portuguese, and Spanish (Hugging Face model card). If your product takes input outside that list, the spec says so — and says what to do when it happens.
The Spec Test: Trace a 20-megapixel photo uploaded in Vietnamese through all three layers. If the path is not covered end-to-end, the contract is incomplete.
Step 3: Wire the Layers in the Right Order
Build order matters because each layer’s output is the next layer’s input contract. If you start from the LLM backbone and work backward, you over-fit the encoder to the backbone’s taste and box yourself out of swapping either one.
Build order:
- Vision encoder first — pick and lock before you pick the LLM. It constrains the hardest physical dimensions: max resolution, patch strategy, embedding size. Frozen SigLIP 2 is the 2026 default for a reason. It trains with sigmoid loss that is batch-size independent, so fine-tuning does not need the 32K+ batch sizes CLIP’s softmax contrastive loss demands (Hugging Face SigLIP 2 blog).
- Connector second — its only job is translating between the encoder’s embedding space and the LLM’s token space. Keep it thin. A 2-layer MLP is a good default. This is the component you will iterate on, so do not couple it to business logic.
- LLM backbone last — because it is the easiest to swap. Qwen3 today, an OLMo3 variant tomorrow, a Llama successor next quarter. If layers 1 and 2 are clean, the backbone becomes an evaluation variable, not a rewrite.
For each component, your context must specify:
- What it receives (inputs — image tensor shape, dtype, color space, or for the LLM, the token stream and visual prefix)
- What it returns (outputs — feature dimension for the encoder, token-space projection for the connector, generation for the LLM)
- What it must NOT do (no PII in logs, no silent resolution downsampling, no cross-modal mixing inside the encoder)
- How to handle failure (corrupted image, unsupported language, context overflow, connector shape mismatch)
A note on State Space Model alternatives: Mamba-style vision backbones keep appearing on benchmarks, but as of April 2026 the dominant open-weights pipelines still rely on transformer-based ViT encoders like SigLIP. Your spec can leave the door open. It should not bet the product on an SSM encoder yet.
Step 4: Prove the Pipeline End-to-End
You do not validate a multimodal pipeline by staring at a few outputs and nodding. You validate by testing each boundary, and the composition of boundaries. Assertions at every seam. No exceptions.
Validation checklist:
- Encoder resolution contract — failure looks like: uploads above the spec’d resolution silently downsampled. Small text in diagrams becomes illegible in the output and nobody sees why.
- Connector shape contract — failure looks like: dimension-mismatch exceptions at integration time, or worse, silently wrong feature fusion that degrades answers without throwing.
- Tokenizer cost drift — failure looks like: billing doubles overnight when the provider updates a tokenizer. Assert tokens-per-sample on a golden set. Alert on drift.
- Context-window regime — failure looks like: queries crossing the 200k boundary on Gemini 3.1 Pro start costing $4 input and $18 output per 1M tokens instead of $2 and $12 (OpenRouter). Log context length per request. Flag requests that cross the tier.
- Cross-modal consistency — failure looks like: the same semantic question asked text-only vs image-plus-text returns contradictory answers. Run a metamorphic test set where text and image describe the same fact.
Security & compatibility notes:
- Gemini 3 Pro Preview deprecated. Shut down March 9, 2026. Migrate to Gemini 3.1 Pro Preview (Google AI for Developers).
- Claude Opus 4.7 tokenizer drift. New tokenizer may produce up to 35% more tokens for the same text vs Opus 4.6. Re-measure tokens-per-request before trusting rate-card math (ALM Corp).
- LLaVA-NeXT deprecation signal. Still functional, but superseded by LLaVA-OneVision-1.5 (Dec 2025) as the open-source frontier. Pin LLaVA-NeXT only if you already validated it; start new projects on LLaVA-OneVision-1.5.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| “Use Gemini for images” | No spec for context regime — bill crosses the 200k tier silently | Name the context-window regime and alert on boundary crossings |
| Picked vision model from a benchmark screenshot | Benchmarks measured on a different resolution and language mix | Spec your own eval set at your resolution, in your languages |
| Treated the connector as “glue code” | AI generated an adapter that loses spatial information | Spec connector input shape, output shape, and what must NOT be dropped |
| Deployed an open-source model without pinning | Upstream repo refactors break your loader | Pin model hash + processor version in the spec, not just the model name |
Pro Tip
Write your pipeline spec as three independent contracts — encoder, connector, backbone — and treat the choice of model as an implementation detail inside each contract. Teams that bake “Gemini 3.1 Pro” into the architecture doc lock themselves into one vendor’s quirks. Teams that write “a vision encoder that accepts up to N megapixels and emits M-dim features” can swap providers when pricing shifts, benchmarks flip, or a new open-weights release changes the math. The spec outlives the model.
Frequently Asked Questions
Q: How to choose between GPT-5.4, Gemini 3.1 Pro, and Claude Opus 4.7 for multimodal applications? A: Gemini 3.1 Pro wins on long context — 2M tokens, tiered pricing at the 200k boundary (OpenRouter). Claude Opus 4.7 wins on high-resolution fidelity, supporting 3.75MP inputs with a 98.5% visual-acuity score (ALM Corp). GPT-5.4 wins on ecosystem depth and broad tool reach. Watch Opus 4.7’s tokenizer — it can produce more tokens than 4.6 for the same text.
Q: When should I use an open-source multimodal model like LLaVA-NeXT or Llama 3.2 Vision? A: Llama 3.2 Vision (128K context, seven official languages per Hugging Face model card) is the production-proven baseline for on-prem or EU-residency work. LLaVA-NeXT is superseded — start new projects on LLaVA-OneVision-1.5, trained on a $16,000 compute budget (LLaVA-OneVision-1.5 paper). Llama for stability, LLaVA-OneVision-1.5 for tuneability.
Q: How to build a multimodal pipeline with a vision encoder, connector, and LLM backbone in 2026? A: Default stack: frozen SigLIP 2 encoder, 2-layer MLP connector, Qwen3 or OLMo3 LLM backbone. Lock each layer’s contract before writing integration code. For hosted APIs (Gemini, GPT, Claude), spec the same three contracts even though they hide behind one endpoint — your validation still runs at every boundary.
Your Spec Artifact
By the end of this guide, you should have:
- A three-layer pipeline map naming your vision encoder, connector, and LLM backbone with explicit interfaces between them
- A per-layer contract list — inputs, outputs, constraints, failure modes — for each component
- A validation checklist with assertions at every seam: resolution, shape, tokenizer cost, context regime, cross-modal consistency
Your Implementation Prompt
Paste the prompt below into Claude Code, Cursor, or Codex when you are ready to scaffold the pipeline. Fill each bracketed value from the contracts you wrote in Steps 1-4. Do not run it with placeholders still in place — the whole point of this guide is that the blanks are where failures come from.
You are building a production multimodal pipeline. Follow the three-layer
architecture: vision encoder -> connector -> LLM backbone. Do not deviate.
LAYER 1 - VISION ENCODER
- Encoder: [e.g., SigLIP 2 SO400M, frozen]
- Max input resolution: [e.g., 1024x1024]
- Patch strategy: [e.g., AnyRes-9 for images; 196 tokens/frame for video]
- Output feature dimension: [e.g., 1152]
- MUST NOT: silently downsample above resolution cap; log raw images to disk
LAYER 2 - CONNECTOR
- Architecture: [e.g., 2-layer MLP]
- Input shape: [must match Layer 1 output]
- Output shape: [must match LLM token embedding dim]
- MUST NOT: mix modalities inside projection; add learned positional bias beyond spec
LAYER 3 - LLM BACKBONE
- Model: [e.g., Gemini 3.1 Pro / Llama 3.2 Vision 90B / Qwen3]
- Context-window regime: [under 200k | above 200k]
- Tokenizer note: [measure tokens-per-sample on golden set; alert on drift]
- Supported languages: [explicit list]
VALIDATION (emit assertions, not just runtime code)
- Assert encoder input resolution within bounds
- Assert connector input/output shapes
- Assert tokenizer cost on golden set within +/- [N]% of baseline
- Assert cross-modal consistency on [N] paired text/image test cases
ERROR HANDLING
- Corrupted image -> [defined fallback]
- Unsupported language -> [defined fallback]
- Context overflow -> [defined fallback]
- Connector shape mismatch -> [defined fallback]
Generate the pipeline module, the assertion suite, and a one-page README
explaining how to swap any single layer without touching the other two.
Ship It
You now have a pipeline spec that survives model churn. When the next Gemini ships, when the next Llama drops, when LLaVA-OneVision-2 lands — you swap one layer, re-run the assertions, and the rest of the system does not move. Vendor names change. The three-layer contract does not.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors