How to Build a GraphRAG Pipeline with Neo4j and LightRAG in 2026
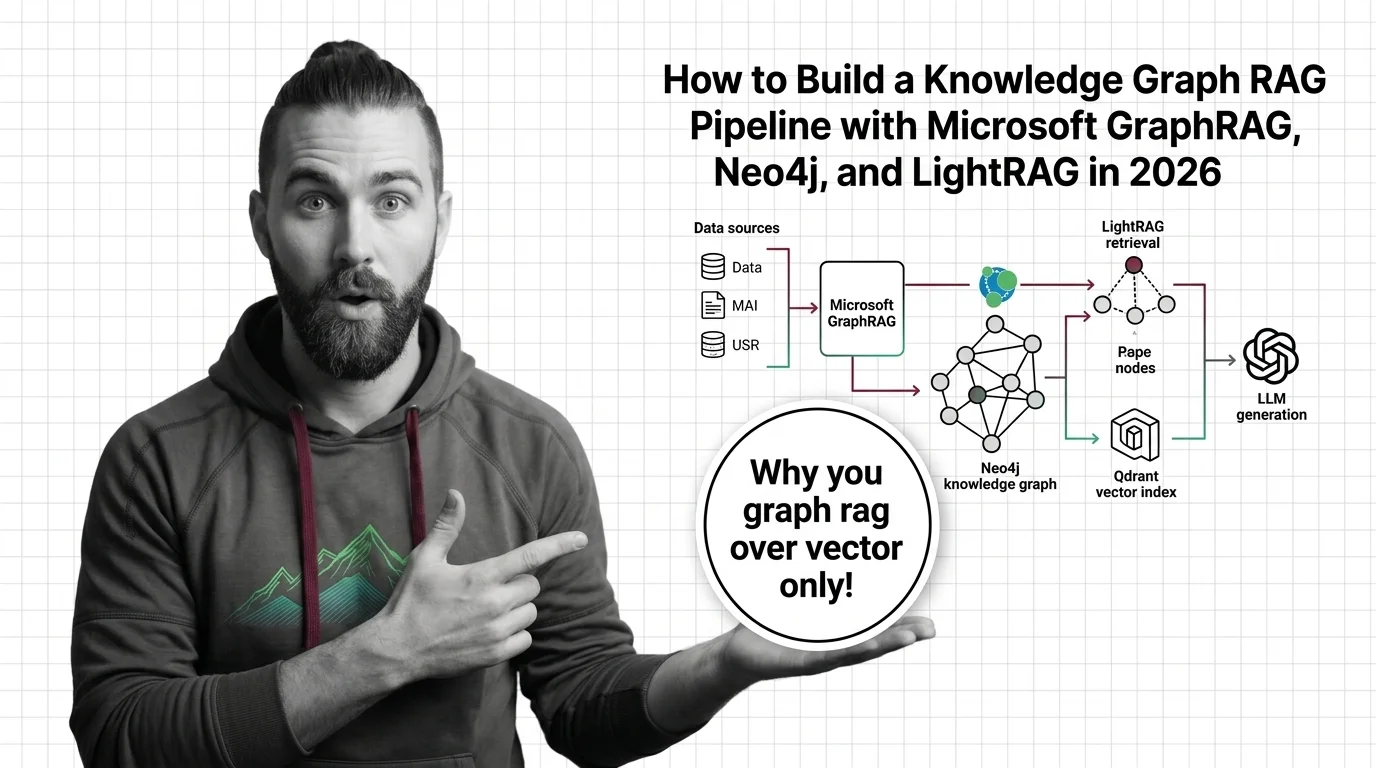
Table of Contents
TL;DR
- Vector RAG retrieves chunks. Knowledge Graphs For RAG retrieves chunks plus the relationships between them — that’s the only reason to take on the extra moving parts.
- Treat the pipeline as five separable contracts: ingest, extraction, dual storage (graph + vector), retrieval, and synthesis. Specify each one before you let the AI write a single line.
- Microsoft GraphRAG, Neo4j, LightRAG, and Qdrant are not interchangeable boxes. Pick by query pattern and budget — global summarization, multi-hop QA, or low-cost incremental ingest each prefer a different stack.
A bank’s compliance team wires standard vector RAG over five years of policy documents. They ask: “Which counterparties of Subsidiary X are also exposed to Sanctioned Entity Y through any chain of ownership?” The system returns the three chunks that contain the most semantically similar sentences. None of them have the answer, because the answer lives in the edges between documents, not in any single chunk. That’s the failure mode you’re here to fix.
Before You Start
You’ll need:
- An AI coding tool — Claude Code, Cursor, or Codex
- Working knowledge of Entity Extraction and Multi-Hop Reasoning
- A real corpus you want to query — not a toy dataset, because graph value only shows on connected data
- An LLM provider account (the indexing step is LLM-heavy)
This guide teaches you: how to decompose a Knowledge Graph RAG pipeline into five contracts so your AI tool can build each piece without guessing the interfaces.
Vector Search Doesn’t Walk Edges
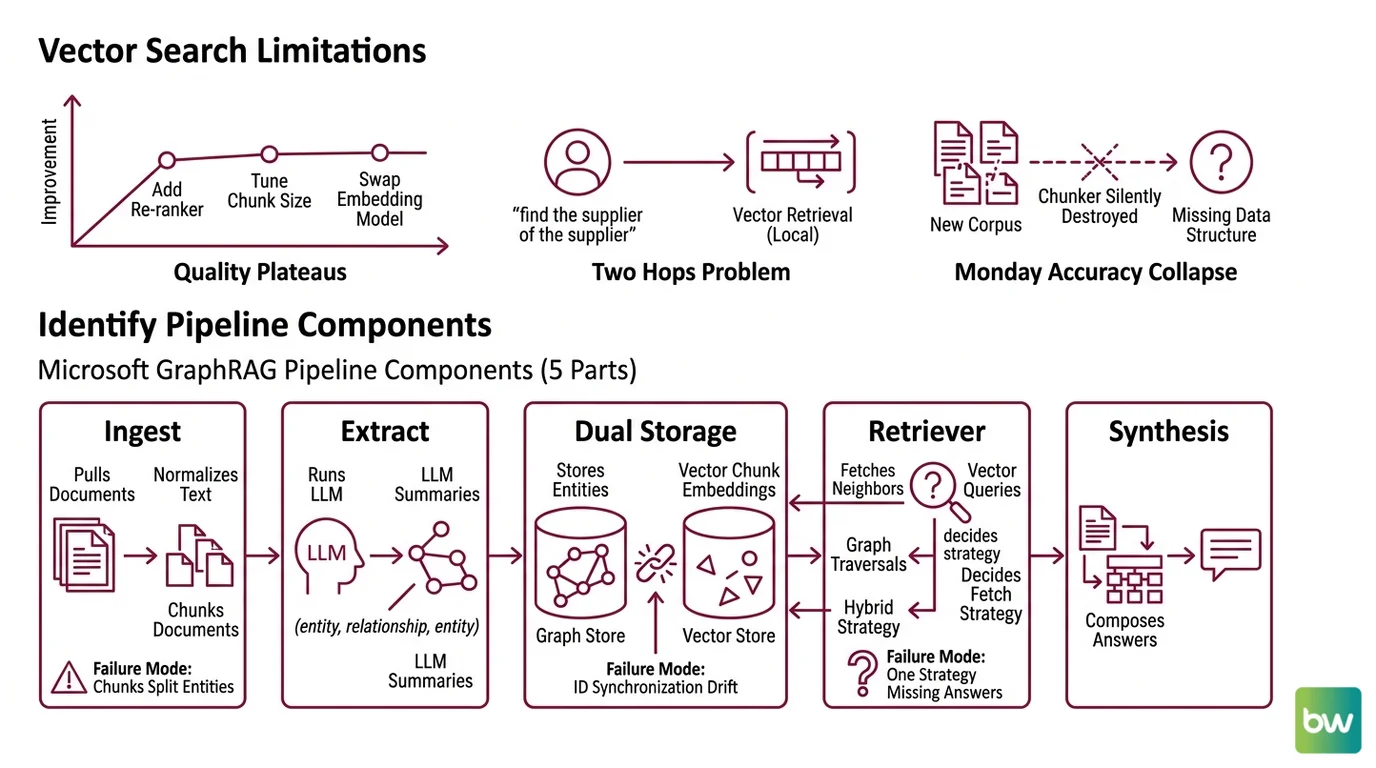
Here’s what I see every quarter. A team ships a working vector RAG. Quality plateaus. They add a re-ranker. They tune chunk size. They swap the embedding model. The chart barely moves.
Then someone asks a question that needs two hops — “find the supplier of the supplier” — and the whole system goes blank. That’s not a tuning problem. That’s a missing data structure.
It worked on Friday. On Monday, accuracy collapsed because the new corpus contained relationships the chunker silently destroyed.
Vector retrieval is local. Graph retrieval is structural. You don’t fix one with more of the other — you compose them. And if you skip the decomposition, your AI tool will dump everything into one orchestrator class and you’ll be debugging it for a week.
Step 1: Identify the Pipeline Components
A Microsoft GraphRAG pipeline is not one system. It’s five, and each one fails differently.
Your system has these parts:
- Ingest — pulls source documents, normalizes text, chunks them. Owns: document IDs, chunk boundaries, source metadata. Failure mode: chunks split entities across boundaries, killing extraction recall.
- Entity & Relationship Extraction — runs an LLM over chunks to pull
(entity, relationship, entity)triples and short summaries. Owns: schema of entity types, relationship types, summary length. This is where most of your token spend goes. - Dual Storage — a graph store for entities and edges, a vector store for the embeddings of chunks (and optionally entity summaries). Owns: ID synchronization between the two. Failure mode: drift between the graph node ID and the vector point ID, and your retriever returns orphans.
- Retriever — given a query, decides what to fetch: vector neighbors, graph traversals, or a hybrid. Owns: search strategy per query type (local, global, drift, hybrid). Failure mode: one strategy used for all questions; some answers go missing.
- Synthesis — composes the retrieved context into the LLM prompt and produces the final answer. Owns: token budget, citation format, hallucination guards.
The reason this decomposition matters: the same five parts appear whether you use Microsoft GraphRAG, the neo4j-graphrag library, or
LightRAG. The boundaries are stable. The implementations swap.
The Architect’s Rule: If you can’t draw the data flow on a napkin in five labelled boxes, the AI can’t build it either.
Step 2: Lock Down the Contract
This is where most pipelines die. The AI generates plausible-looking glue code that pins the wrong vector dimension, or uses a deprecated package, or assumes consumption-priced infrastructure when you booked capacity.
Context checklist — every item must be specified before any code is written:
- Graph database choice and version —
Neo4j 2026.01+ if you want the new Cypher
SEARCHclause for vector queries (Neo4j Cypher Manual). Olderdb.index.vector.queryNodessyntax still works but is no longer the recommended pattern. - Graph driver package —
neo4j-graphragv1.15.0, released April 23, 2026 (neo4j-graphrag on PyPI). The olderneo4j-genaipackage is deprecated and will not be maintained — pin the new one or migrate before you start. - Vector store and dimension — Neo4j’s native vector index caps at 4096 dimensions per index (Neo4j Cypher Manual). If your embedding model exceeds that, you need a separate vector store like Qdrant.
- Hybrid wiring contract — if you split graph and vectors across two databases, write the cross-reference rule explicitly: every Qdrant point ID equals the corresponding Neo4j node ID. The official Qdrant + Neo4j recipe uses
QdrantNeo4jRetrieverfor exactly this (Qdrant Docs). - Extraction LLM and budget cap — name the model and the per-document ceiling. Indexing dollar cost varies by roughly 10× between GPT-4o and GPT-4o-mini for the same corpus, per the market scan.
- Query types you actually need — local lookup, global summarization, multi-hop traversal, or all three. The retriever spec follows from this; don’t let the AI guess.
- Hosting capacity — Neo4j AuraDB Free covers 200,000 nodes and 400,000 relationships (Neo4j’s pricing page). AuraDB Professional starts at $65 per GB / month and AuraDB Business Critical at $146 per GB / month, both capacity-based on reserved RAM, not per-query.
The Spec Test: If your context file doesn’t pin the vector dimension and the graph driver package version, the AI will pick whatever showed up most in its training set — and that is almost certainly the deprecated
neo4j-genai, with a 1536-dimension assumption that breaks when you swap embedding models.
Step 3: Wire the Components in the Right Order
The build order matters because each layer depends on the contract of the previous one. Skip the order, and you debug a stack of half-built pieces instead of one piece at a time.
Build order:
- Ingest first — chunking, document IDs, source metadata. No dependencies. Validate by counting chunks and spot-checking that no entity (a person name, a contract number) is split across a chunk boundary.
- Extraction next — feeds on the ingest output. Lock the entity-type whitelist before running. Extraction drift is the silent killer: if you don’t constrain the schema, a second indexing run will produce different node types from the same data and your graph becomes inconsistent.
- Storage layer — graph store and vector store written in the same transaction-like step. Both write keyed by the chunk ID and entity ID from Step 2. If you split this into two separate runs, you get drift.
- Retriever — built last, because it depends on what’s actually in the stores. Pick the search strategy per query type. Microsoft GraphRAG uses local search for entity-centric questions and global search for Community Detection-summarized questions; the official docs split the Indexer and Query packages for this reason (Microsoft GraphRAG Docs).
- Synthesis — wraps the retriever. This is the only layer that talks to the user. Token budget and citation rules belong here, not in the retriever.
For each component, your context must specify:
- What it receives (input shape, IDs, types)
- What it returns (output shape, persisted IDs, error envelope)
- What it must NOT do (no swallowing extraction failures silently, no ID generation outside the ingest layer)
- How to handle failure (retry policy, partial-success semantics, dead-letter for malformed chunks)
If you’re cost-constrained, this is also the layer where you choose between full GraphRAG and LightRAG. LightRAG (HKUDS, EMNLP 2025; v1.4.10 released Feb 27, 2026, per the LightRAG GitHub repository) does incremental graph updates without a full rebuild and uses a simpler dual-level retrieval. The LightRAG paper reports roughly 100 tokens per query versus roughly 610,000 tokens per query for GraphRAG on the UltraDomain benchmark — about 6,000× lower — and an average 80 ms response versus 120 ms for baseline RAG (LightRAG paper, ACL Anthology). Treat both numbers as author-reported on their own benchmark, not independent verification.
Step 4: Prove It Walks the Edges
Vector RAG validation is “did we find the right chunk?” Graph RAG validation has to test what the graph adds — the multi-hop and global queries vector alone can’t answer.
Validation checklist:
- Single-hop sanity — failure looks like: questions about one entity return wrong or missing facts. Means your extraction missed entities or the vector index is broken. Fix extraction before the graph.
- Multi-hop traversal — failure looks like: “find X connected to Y through Z” returns nothing. Means the relationship type wasn’t in your extraction schema, or the retriever isn’t doing graph traversal. Inspect the Cypher generated by your retriever.
- Global summarization — failure looks like: “what are the main themes in the corpus?” returns three random chunks. Means you skipped the community-detection step during indexing. That is the step that lets GraphRAG answer corpus-level questions.
- ID drift between stores — failure looks like: retriever returns a graph node with no associated chunk text, or a vector hit with no graph context. Means your dual-storage write step is split. Pull a sample, join by ID, count the orphans.
- Cost-per-query ceiling — failure looks like: indexing one document costs more than your monthly budget for the whole corpus. Switch to LazyGraphRAG (currently shipped inside Microsoft Discovery and Azure Local public preview; mainline
microsoft/graphragintegration is pending as of Q2 2026) or to LightRAG.
For production scale reference: Lettria reported running over 100M embeddings on the Qdrant + Neo4j hybrid with sub-200 ms latency and a 20–25% accuracy uplift versus traditional RAG (Neo4j Blog). That’s a real-world ceiling, not a theoretical one — and it works only because the team owned all five contracts above.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| One-shot “build me a GraphRAG pipeline” | AI dumps ingest, extraction, and retrieval into one class | Decompose into five contracts before prompting |
| Didn’t pin the graph driver | AI picks the deprecated neo4j-genai package | Specify neo4j-graphrag 1.15.0+ in your context |
| Used 1536-dim embeddings without checking the index | Neo4j vector index works, until you try a model that exceeds 4096 dims | Pin embedding model and dimension; add Qdrant if you exceed the cap |
| Skipped the entity-type whitelist | Re-indexing produces different node types, graph drifts | Lock entity and relationship types in the extraction prompt |
| Mixed local and global queries through one retriever | Global questions return three random chunks | Split retriever by query type — local search vs. community-summary search |
| Treated GraphRAG OSS as “Microsoft-supported” | Production team blocked on a bug with no SLA | The OSS repo is explicitly tagged a demonstration, not a supported Microsoft product (Microsoft GraphRAG Docs); use Azure offerings for SLAs |
Pro Tip
Every contract you lock down before generation saves a day of debugging after. The five contracts in Step 2 are not optional documentation. They are the specification the AI is reading from. Vague specs produce vague pipelines, and a vague pipeline always becomes a rewrite.
Security & compatibility notes:
neo4j-genaideprecated: Migrate toneo4j-graphragv1.15.0+. The old package will not receive maintenance updates. Action: pinneo4j-graphrag>=1.15.0,<2.0.0.- Microsoft GraphRAG config refresh: Run
graphrag init --root [path] --forcebetween minor version bumps; major bumps may need a migration notebook to avoid full re-indexing. Action: add the init step to your version-bump checklist.- LazyGraphRAG OSS gap: LazyGraphRAG ships inside Microsoft Discovery and Azure Local public preview, but the mainline
microsoft/graphragrepo has not absorbed it as of Q2 2026 (Microsoft GraphRAG Discussions). Action: if you need the lazy variant outside Azure, plan a custom integration.- Microsoft GraphRAG OSS support status: Tagged as a demonstration, not a supported Microsoft product. Action: do not assume enterprise SLAs from the OSS lib alone.
Frequently Asked Questions
Q: When should you choose GraphRAG over vector-only RAG for enterprise knowledge bases?
A: Choose GraphRAG when real questions need multi-hop traversal or corpus-wide summarization — answers vector retrieval cannot reach because the data lives in relationships. Pilot with twenty real questions; if more than a third need two or more hops, build the graph.
Q: Which use cases benefit most from knowledge graph RAG: legal discovery, medical Q&A, or financial compliance?
A: Financial compliance wins biggest because ownership chains are explicitly graph-shaped. Legal discovery benefits from entity-centric local search across case law. Medical Q&A is the trickiest — clinical relationships are graph-rich, but extraction errors carry patient-safety risk; add a human review step.
Q: How do you build a GraphRAG pipeline step by step using Microsoft GraphRAG, Neo4j, and a hybrid Qdrant vector layer in 2026?
A: Follow the five-contract decomposition: ingest, extraction, dual storage, retriever, synthesis. Use microsoft/graphrag for the indexer, neo4j-graphrag 1.15.0+ for the driver, and Qdrant when embeddings exceed Neo4j’s 4096-dimension cap. Wire the two via QdrantNeo4jRetriever with shared IDs.
Your Spec Artifact
By the end of this guide, you should have:
- A five-component map of your pipeline — ingest, extraction, dual storage, retriever, synthesis — with the inputs, outputs, and forbidden behaviors for each.
- A locked contract document covering graph database version, driver package, embedding dimension, hybrid wiring rule, extraction LLM and budget cap, query types, and hosting capacity tier.
- A validation checklist with at least one test per failure mode in Step 4 — single-hop, multi-hop, global, ID drift, and cost ceiling.
Your Implementation Prompt
Paste this into Claude Code, Cursor, or Codex when you’re ready to scaffold. It mirrors the five contracts from Step 1 and the constraint categories from Step 2. Fill the brackets with your actual values — every bracket is a decision you owe the AI before it writes code.
You are building a knowledge-graph RAG pipeline. Follow this specification exactly.
Do not invent components, packages, or interfaces beyond what is listed.
COMPONENTS (build in this order, no shortcuts):
1. Ingest — input: [source location]; output: chunks with stable IDs and metadata.
2. Entity & Relationship Extraction — input: chunks; output: triples + summaries.
Entity types allowed: [list]. Relationship types allowed: [list].
3. Dual Storage — write graph nodes/edges and vector points in one step,
keyed by shared chunk and entity IDs.
4. Retriever — implement these search strategies: [local | global | hybrid].
5. Synthesis — token budget [N], citation format [format], refusal rule on empty context.
CONTRACT (do not deviate):
- Graph DB: Neo4j [version, e.g. 2026.01]; use the SEARCH Cypher clause for vectors.
- Graph driver: neo4j-graphrag [>=1.15.0]. Do NOT use neo4j-genai (deprecated).
- Vector store: [Neo4j native if dim <= 4096, else Qdrant].
- Embedding model: [name]; dimension: [N].
- Hybrid wiring (if split): every Qdrant point ID == matching Neo4j node ID.
- Extraction LLM: [model]; per-document budget cap: [USD].
- Query types in scope: [list].
- Hosting tier: [AuraDB Free | Professional | Business Critical] sized for [N nodes, N relationships].
BUILD ORDER: ingest → extraction → storage → retriever → synthesis.
Do not start a layer until the previous layer's contract is testable.
VALIDATION (must pass before merge):
- Single-hop: [N] sample questions return correct facts.
- Multi-hop: [N] sample questions traverse [K] hops and return correct chains.
- ID drift: zero orphan graph nodes and zero orphan vector points on a [N]-row sample.
- Cost-per-doc indexing: under [USD].
OUTPUT: code per component, with the contract restated as a docstring. No more.
Ship It
You now have a way to think about KG-RAG that doesn’t collapse the second a stakeholder asks a multi-hop question. Five contracts. One build order. One validation checklist. The next time someone says “let’s add a knowledge graph to our RAG,” you can answer with a spec instead of a shrug — and the AI tool can build to that spec instead of guessing.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors