How to Build a Decoder-Only Transformer and Select the Right Pretrained Model in 2026
Table of Contents
TL;DR
- A decoder-only transformer is three contracts: embedding, masked attention, and token prediction — specify each separately or the AI conflates them
- The causal mask is the single most consequential specification — one wrong index and training loss lies to you
- Model selection in 2026 splits on one question: do you need to fine-tune, or not
Last week a developer showed me a Decoder Only Architecture with a validation perplexity of 1.3. Beautiful number. The model generated the word “the” two hundred times in a row during inference. The Causal Masking had an off-by-one error. Training saw future tokens. Inference didn’t. The loss was a lie. That’s what happens when you don’t spec the mask.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex)
- Working knowledge of Transformer Architecture and the Attention Mechanism
- PyTorch 2.10+ installed
- A clear picture of your sequence task (text generation, code completion, dialogue)
This guide teaches you: How to decompose a decoder-only transformer into five specifiable components, validate each one independently, and select the right pretrained model when building from scratch isn’t the answer.
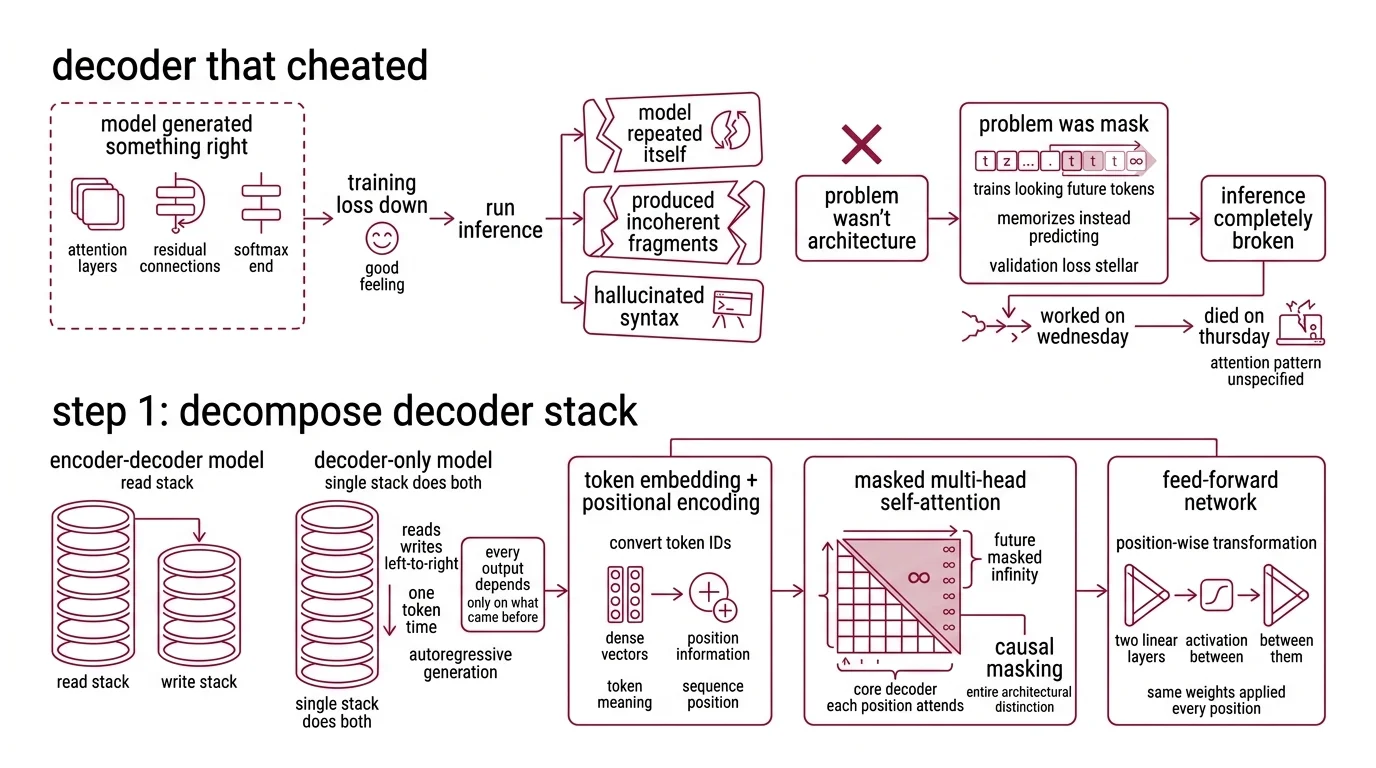
The Decoder That Cheated on Its Own Exam
You told the AI to build you a decoder-only transformer. It generated something that looked right — attention layers, residual connections, a softmax at the end. Training loss went down. You felt good.
Then you ran inference. The model repeated itself, produced incoherent fragments, or hallucinated syntax from a language it was never trained on.
The problem wasn’t the architecture. The problem was the mask. Without a correct causal mask, the model trains by looking at future tokens. It memorizes instead of predicting. Validation loss looks stellar. Inference is completely broken.
It worked in the notebook on Wednesday. It died in production on Thursday because the attention pattern was never specified.
Step 1: Decompose the Decoder-Only Stack
A decoder-only transformer has five components. Not four. Not “some layers.” Five, with strict data-flow boundaries between them.
Before you spec any component, understand what separates this from an Encoder Decoder Architecture. An encoder-decoder model has two stacks — one to read, one to write. A decoder-only model does both jobs with a single stack. It reads and writes left-to-right, one token at a time, using Autoregressive Generation. Every output depends only on what came before it.
Your system has these parts:
- Token embedding + positional encoding — converts input token IDs into dense vectors with position information. This is where the model learns what a token means and where it sits in the sequence.
- Masked multi-head self-attention — the core of the decoder. Each position attends to itself and all previous positions. Future positions are masked with negative infinity. This is causal masking, and it is the entire architectural distinction.
- Feed-forward network — position-wise transformation. Two linear layers with an activation function between them. Same weights applied independently to every position.
- Layer normalization + residual connections — stabilization plumbing. Pre-norm or post-norm — pick one and specify it. The AI will default to whichever appeared more often in its training data.
- Output projection — maps the final hidden state back to vocabulary size. This is where Next Token Prediction happens.
The Architect’s Rule: If you can’t draw these five boxes on a whiteboard with arrows between them, you’re not ready to spec the build.
Step 2: Lock Down Every Mask and Dimension
This is where most specs fail. You told the AI “build a transformer” but didn’t tell it the numbers. It guessed. It guessed wrong.
Context checklist:
- Vocabulary size — your tokenizer determines this, not the model
- Maximum sequence length — caps your positional encoding and causal mask dimensions
- Embedding dimension (
d_model) — must be divisible by the number of attention heads - Number of attention heads —
d_model / n_headsgives you the head dimension. If this isn’t an integer, nothing works - Number of decoder layers — more layers means more capacity, more memory, slower inference
- Feed-forward hidden dimension — typically 4x
d_model, but specify it explicitly - Dropout rate — training regularization, set to 0.0 for inference
- Causal mask construction — upper triangular matrix filled with negative infinity. Size:
[seq_len, seq_len]. Position(i, j)is masked whenj > i. Non-negotiable.
The KV Cache is the other spec most people skip. During inference, attention recomputes key-value pairs for every previous token at every generation step. A KV-cache stores and reuses them. Without it, generation time scales quadratically with sequence length. With it, linearly. Specify whether your build includes one.
The Spec Test: If your context doesn’t define the causal mask as a
[seq_len, seq_len]upper triangular matrix, the AI may use PyTorch’sis_causalflag — which has known issues in certain configurations (PyTorch Docs). Specify an explicit mask tensor instead.
Step 3: Wire Embedding to Logits in Build Order
Order matters. Each component depends on the previous one’s output shape. Get the sequence wrong and the AI will invent an adapter layer you never asked for.
Build order:
- Token embedding + positional encoding first — because every subsequent layer receives this output. Input:
[batch, seq_len]of integer IDs. Output:[batch, seq_len, d_model]of float vectors. - One decoder block next — attention + FFN + norms + residuals. Get one block right before you stack N of them. Input and output shapes are identical:
[batch, seq_len, d_model]. - Output projection last — linear layer from
d_modeltovocab_size. Input:[batch, seq_len, d_model]. Output:[batch, seq_len, vocab_size].
For each component, your context must specify:
- What it receives (tensor shape and dtype)
- What it returns (tensor shape and dtype)
- What it must NOT do (no future token access in attention)
- How to handle failure (NaN detection, gradient clipping boundaries)
PyTorch 2.10 includes TransformerDecoderLayer as a reference building block (PyTorch Docs), but production decoder-only models typically use custom implementations. Spec the components. Let the AI decide whether to wrap the built-in or write custom layers.
Step 4: Prove the Causal Mask Before Anything Else
You don’t validate a decoder-only transformer by watching loss curves. You validate it by inspecting attention patterns. If the mask is wrong, every metric becomes fiction.
Validation checklist:
- Attention weight inspection — for any layer, attention weights at position
imust be zero for all positionsj > i. Non-zero future attention means the mask is broken. Failure looks like: low training loss, garbage inference. - Single-token generation test — feed a prompt, generate one token. Feed the same prompt plus that token, generate the next. The model should produce the same first token both times. Failure looks like: different tokens (cache inconsistency or mask leak).
- Causal mask shape — print the mask tensor. It should be upper triangular with
-infabove the diagonal and0on and below. Failure looks like: a mask of all zeros (no masking) or wrong diagonal offset. - Gradient flow — loss for token at position
ishould have no gradient contributions from tokens at positions> i. Failure looks like: suspiciously low loss early in training.
Picking Your Pretrained Decoder in 2026
Sometimes the right move isn’t building from scratch. As of early 2026, three families dominate production decoder-only work. Your choice depends on fine-tuning needs, context budget, and whether you can self-host.
GPT-5 offers a 400K token context window with 128K max output at $1.25 input / $10 output per MTok (OpenAI Docs). GPT-5.4 pushes context to 1,050,000 tokens at $2.50 / $15 per MTok (OpenAI Docs). Neither supports fine-tuning. If your task fits the base model, this is the fastest path to production. If you need domain adaptation, look elsewhere.
LLaMA 4 Scout runs 17B active parameters from a 109B MoE total with 16 experts and 10M token context (Meta AI Blog). Open-source, LoRA fine-tunable via Unsloth or Hugging Face PEFT. Maverick scales to 400B total with 128 experts and 512K context. Behemoth is still in training and not available for production.
DeepSeek V3.2 fields 685B total / 37B active in an MoE architecture with 128K context via API (DeepSeek API Docs). Cost: $0.28 input / $0.42 output per MTok at cache miss (DeepSeek Pricing). MIT-licensed, open-source weights. Self-hosted LoRA means adapter matrices for 256 experts per MoE layer — Fireworks QAT is the practical fine-tuning route.
The decision tree:
- No fine-tuning needed, budget exists — GPT-5 or GPT-5.4
- Fine-tuning required, can self-host — LLaMA 4 Scout or Maverick
- Cost-sensitive, massive context — DeepSeek V3.2 via API
- Fine-tuning + cost-sensitive — DeepSeek V3.2 via Fireworks QAT
Compatibility notes:
- Hugging Face Transformers v5: TensorFlow and JAX support removed. Python 3.10 minimum required.
use_auth_tokendeprecated — usetokeninstead.TRANSFORMERS_CACHEenv var replaced byHF_HOME.- PyTorch
nn.Transformer: Theis_causalparameter has known issues in some configurations. Build explicit causal masks instead of relying on the flag.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| “Build me a transformer” | AI generated an encoder-decoder, not decoder-only | Specify “decoder-only” and include the causal mask requirement |
| Didn’t specify mask construction | AI used is_causal=True which has known issues | Provide explicit upper-triangular mask spec with dimensions |
No d_model / n_heads constraint | Embedding dimension not divisible by head count | State both values and verify divisibility in the spec |
| Skipped KV-cache spec | Inference runs quadratically slow on long sequences | Add KV-cache as a required inference-time optimization |
| Used encoder-decoder loss function | Cross-entropy computed on wrong token positions | Specify loss on shifted next-token targets only |
Pro Tip
Every decoder-only transformer — from a 50-line teaching build to GPT-5 — follows the same five-component decomposition. The dimensions change. The mask doesn’t. When you spec a new build, start from the causal mask and work outward. The mask is the contract. Everything else is plumbing.
Frequently Asked Questions
Q: How to implement a minimal decoder-only transformer with causal masking in PyTorch?
A: Spec three components: an embedding layer, a single TransformerDecoderLayer block with an explicit upper-triangular causal mask, and a linear output projection. Feed dummy sequences and inspect attention weights to confirm zero values at future positions before stacking layers.
Q: How to choose between GPT-5, LLaMA 4, and DeepSeek V3 for production decoder-only applications in 2026? A: Split on fine-tuning. GPT-5 offers no fine-tuning — use it for prompt-only workflows with budget. LLaMA 4 Scout supports LoRA and self-hosting. DeepSeek V3.2 wins on cost per token but needs Fireworks QAT for practical fine-tuning.
Q: How to fine-tune a decoder-only model for domain-specific tasks without catastrophic forgetting? A: Use LoRA or QLoRA to freeze base weights and train low-rank adapters on domain data. Keep a validation set from the original distribution and monitor original-task accuracy. If it drops past your threshold, reduce adapter rank or increase regularization.
Your Spec Artifact
By the end of this guide, you should have:
- A five-component decomposition of your decoder-only transformer (embedding, attention, FFN, norms, projection) with data-flow boundaries
- A constraint checklist covering every dimension, mask specification, and build-order dependency
- A validation protocol that catches causal mask failures before training begins
Your Implementation Prompt
Paste this into Claude Code, Cursor, or your AI coding tool. Fill the bracketed values from your constraint checklist in Step 2. Every placeholder maps to a specific checklist item — no guessing.
Build a decoder-only transformer in PyTorch with these specifications:
ARCHITECTURE:
- Vocabulary size: [your tokenizer vocab size]
- Max sequence length: [your max seq_len]
- Embedding dimension (d_model): [your d_model, must be divisible by n_heads]
- Attention heads: [your n_heads]
- Decoder layers: [your layer count]
- FFN hidden dimension: [your ffn_dim, typically 4x d_model]
- Dropout: [your training dropout rate]
- Normalization: [pre-norm or post-norm]
CAUSAL MASK (non-negotiable):
- Build an explicit upper-triangular mask of shape [seq_len, seq_len]
- Mask values: -inf above diagonal, 0 on and below
- Do NOT use the is_causal flag — use the explicit mask tensor
COMPONENTS (build in this order):
1. Token embedding + positional encoding -> output shape [batch, seq_len, d_model]
2. Single decoder block (masked attention + FFN + layer norm + residual) -> same shape
3. Stack [your layer count] decoder blocks
4. Output projection -> [batch, seq_len, vocab_size]
KV-CACHE:
- [Include / Exclude] inference-time KV-cache
- If included: cache shape [batch, n_heads, seq_len, head_dim] per layer
VALIDATION (run before training):
- Print attention weights for layer 0, verify zero values at all future positions
- Feed identical prompt twice, confirm identical logits
- Print causal mask tensor, verify upper-triangular structure
- Run one forward pass, check for NaN in output
Ship It
You now have a decomposition framework that works for any decoder-only transformer — from a teaching prototype to a production model. The five components don’t change. The causal mask doesn’t change. What changes is the numbers you plug in and whether you build it yourself or pick a pretrained model that already made those decisions for you. Either way, you spec it first.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors