Build a Contextual Retrieval Pipeline: Anthropic + Voyage + ColBERT
TL;DR
- Contextual retrieval is a chunking + indexing spec, not a single tool. Decompose it into context generation, embedding, lexical index, fusion, and reranking before you pick libraries.
- The Anthropic recipe (Claude Haiku 4.5 prefixing every chunk) and voyage-context-3 (jointly-trained encoder) solve the same problem at different layers. Pick one for context. Add ColBERT only if your queries demand token-level matching.
- Validate with retrieval failure rate at top-20, not vibes. Anthropic’s own ablation shows context plus contextual BM25 plus reranking reduces top-20 failure by 67% — your job is to reproduce that on your own corpus.
A team I reviewed last month had three retrieval issues open in the same week. Their Retrieval Augmented Generation stack worked fine for “what is our refund policy” and fell over on “what changed between v3.2 and v3.4.” They had already swapped embedding models twice. The bug was not in the embeddings. The bug was that every chunk in their index had been stripped of its document title, section heading, and the sentence that explained what version was being discussed. The retriever was doing exactly what the spec said. The spec was wrong.
Before You Start
You’ll need:
- Contextual Retrieval as a concept, not just as a vendor feature
- An LLM with prompt caching (Claude Haiku 4.5 is the canonical choice — Anthropic Pricing) or a contextualized embedding API like voyage-context-3
- A vector store that supports both dense and sparse indexes, or two stores you control the fusion layer for
- A Reranking model you trust as a final filter
- A held-out evaluation set with ground-truth relevant chunks per query
This guide teaches you: how to decompose contextual retrieval into five independent specs — context, embedding, lexical, fusion, rerank — so you can swap any layer without breaking the others. The result is a Hybrid Search architecture you can debug stage-by-stage, rather than a black-box retriever you have to rebuild every time the failure rate moves.
Why “Add Reranking and Hope” Is Not a Pipeline
Contextual retrieval is not “use voyage-context-3” or “run the Anthropic cookbook.” It is a five-stage pipeline where each stage has its own contract. Skip the contract and you ship a system you cannot debug.
Here is the failure mode I see weekly. A team takes the Anthropic recipe at face value, runs it once on Friday, and on Monday someone asks why the new ingestion job is producing chunks without context. It is because the prompt-cache TTL expired between batches and nobody specified what to do when the cache cold-starts. Same prompt. Same model. Different cost profile. The pipeline still “works” — but the unit economics changed by an order of magnitude and nobody noticed until the bill arrived.
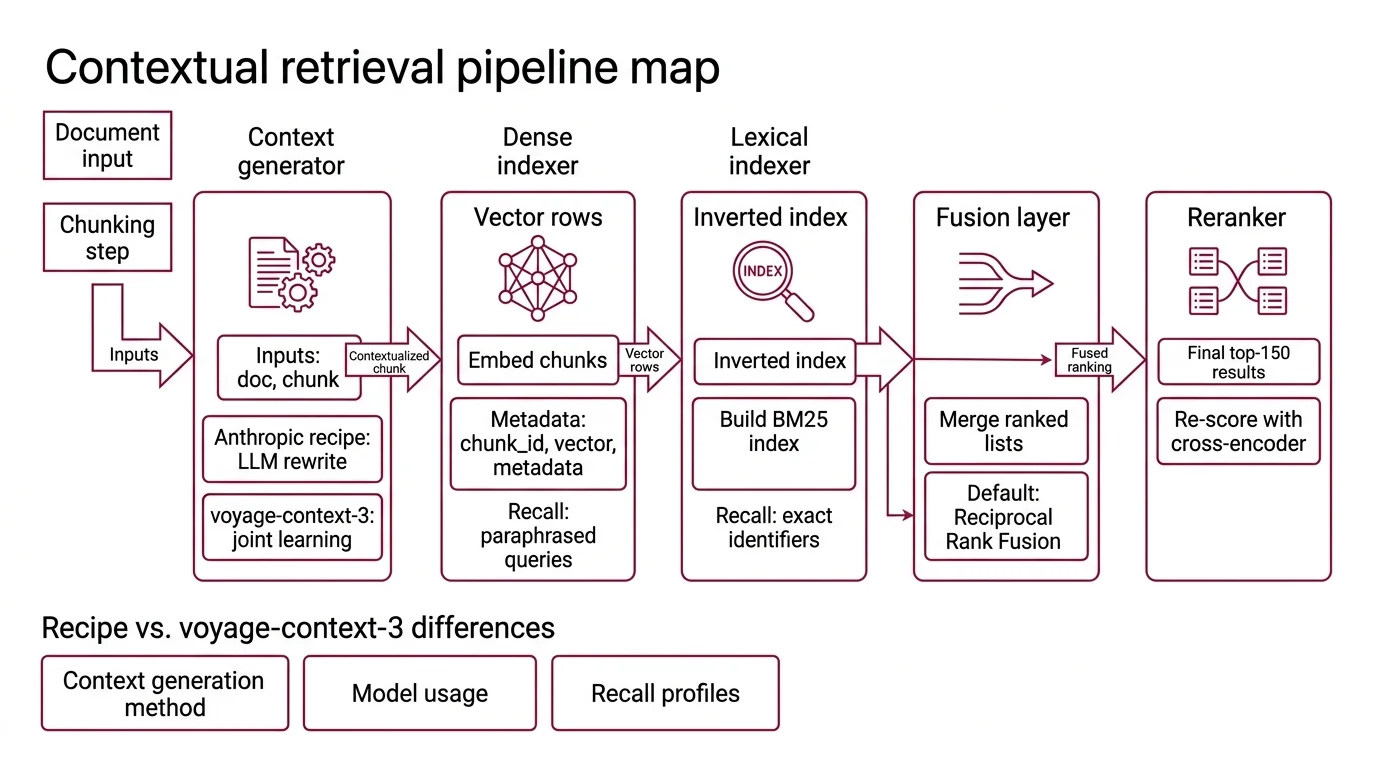
Step 1: Map the Five Stages of the Pipeline
Before any code, name the five stages and the contract between each pair. If you cannot draw the diagram, you cannot specify the system.
Your pipeline has these parts:
- Context generator — turns each chunk into
chunk + 50-100 tokens of context that situates it in the parent document(Anthropic Blog). Inputs: full document, chunk. Output: contextualized chunk text. This stage is where the Anthropic recipe and voyage-context-3 differ — the recipe runs an LLM rewrite, voyage-context-3 learns context jointly inside the encoder. - Dense indexer — embeds contextualized chunks into a vector store. Output:
(chunk_id, vector, metadata)rows. This stage decides recall on paraphrased queries. - Lexical indexer — builds a contextual BM25 index over the same contextualized chunks. Output: an inverted index. This stage decides recall on exact identifiers — error codes, version numbers, function names.
- Fusion layer — takes ranked lists from the dense and lexical retrievers and merges them into one ranking. Reciprocal Rank Fusion is the default. Output: a single ranked list, typically top-150.
- Reranker — re-scores the fused list with a cross-encoder and returns the final top-20. Anthropic Blog reports top-20 is the inflection point — going to top-5 or top-10 leaves recall on the table.
The Architect’s Rule: If you cannot tell me which of those five stages owns a given retrieval failure, you do not have a pipeline — you have a black box with five components inside it.
This is also where you decide whether you need this pipeline at all. Anthropic’s own guidance is that for knowledge bases under roughly 200,000 tokens — about 500 pages — you skip retrieval entirely and stuff the whole corpus into the model’s context (Anthropic Blog). Build the pipeline only when your corpus refuses to fit. And before you reach for Agentic RAG on top of this — multiple retrieval calls orchestrated by an LLM — get the single-pass version of the five stages right. Agentic loops amplify whatever your base pipeline does, including its mistakes.
Step 2: Lock Down the Contract for Each Stage
Each stage gets its own context spec. The whole point of decomposition is that you can swap implementations without touching the others.
Context generator spec:
- Model and version pinned (e.g.,
claude-haiku-4.5). - Prompt cache strategy specified — the document goes in the cached block, the per-chunk instruction goes in the uncached suffix.
- Cacheable block size meets the minimum — Haiku 4.5 requires at least 4,096 tokens to cache (Anthropic Docs). Documents shorter than that do not benefit; either batch them or accept the uncached cost.
- Output length capped at 50-100 tokens per chunk to match the Anthropic spec.
- Workspace boundary documented — as of Feb 5, 2026, prompt caches are workspace-isolated rather than org-wide (Anthropic Docs). Shared caches across teams are no longer assumed.
Dense indexer spec:
- Embedding model and version pinned.
- Vector dimension chosen explicitly — voyage-context-3 supports 256, 512, 1024 (default), and 2048 via Matryoshka quantization (Voyage AI Docs). Pick once. Re-embedding costs money and breaks index compatibility.
- Quantization strategy — voyage-context-3 outputs
float,int8,uint8,binary, orubinary(Voyage AI Docs). Decide based on storage budget and latency requirements before you index, not after. - Per-call payload limits respected — voyage-context-3 caps each request at 1,000 inputs, 120,000 total tokens, and 16,000 total chunks (Voyage AI Docs). Your batcher must enforce all three.
Lexical indexer spec:
- BM25 parameters (
k1,b) chosen and documented. - Tokenizer matched to the dense side — if your contextualized text is being normalized differently between BM25 and the embedder, you will fight phantom mismatches forever.
- “Contextual BM25” means BM25 over the same contextualized text, not the original chunks. This is the difference between a 35% and a 49% top-20 failure-rate reduction in Anthropic’s ablation (Anthropic Blog).
Fusion layer spec:
- Algorithm named (Reciprocal Rank Fusion is the default). The
kconstant is documented. - Top-N from each retriever before fusion is specified. Top-150 fused → top-20 final is the shape Anthropic uses.
Reranker spec:
- Model named and version-pinned.
- Latency budget per query documented. Reranking is where you spend most of your retrieval latency — measure it before you ship.
- Behavior on reranker timeout specified. Falling back to the fused-but-unreranked list is usually the right answer; failing the whole query is rarely the right answer.
The Spec Test: If your context generator’s prompt-cache strategy is not in your repo as text, you do not have a spec — you have a working prototype that one person remembers. Pin the cache plan or pay the difference between $1.25 cache write and $0.10 cache read on every cold start (Anthropic Pricing).
Step 3: Build in Order, Validate Each Layer Before the Next
Build one stage. Prove it works. Then build the next. The order matters because each stage depends on the contract of the one before it.
Build order:
- Context generator first. It produces the artifact every other stage consumes. If your contextualized chunks are wrong, no downstream tuning saves you. Anthropic’s reference recipe runs Claude Haiku (originally Haiku 3, now Haiku 4.5 in the cookbook — Claude Cookbook) over the document with prompt caching so the document stays cached while the per-chunk instruction varies. The reported amortized cost is roughly $1.02 per million document tokens — that figure is from the original 2024 Haiku 3 + caching benchmark, and Anthropic has not republished it for Haiku 4.5; with current Haiku 4.5 pricing ($1.00/MTok input, $0.10/MTok cache read — Anthropic Pricing) the order of magnitude holds, but verify against your own usage before forecasting.
- Dense indexer next. Two real options for 2026. The Anthropic recipe pairs contextualized chunks with any embedding model you already trust. voyage-context-3, released July 23, 2025, takes the opposite bet — the encoder learns chunk-level and document-level context jointly, producing one embedding per chunk that already carries document context (Voyage AI Blog). Voyage’s own benchmarks show +6.76% chunk-retrieval improvement over the vanilla Anthropic recipe, but those numbers are vendor-published — treat them as directional, not as independent confirmation.
- Lexical indexer in parallel with the dense build. It uses the same contextualized chunks. The contract is just “BM25 index over the output of stage 1,” so building it after stage 1 is mostly a scheduling question — and a reminder that contextual BM25 is what unlocks the next ablation tier.
- Fusion layer fourth. Cannot be built until both retrievers exist. Output: a single ranked list. Verify the ranking is stable across reruns before adding rerank on top.
- Reranker last. It is the highest-leverage stage and the most expensive to misconfigure. Anthropic’s ablation shows reranking pushes the top-20 failure-rate reduction from 49% to 67% over the no-context baseline (Anthropic Blog). That delta is the reason it is worth building — and the reason you want every earlier stage clean before you measure it.
For each stage, your context spec must specify:
- What it receives (inputs and their schema)
- What it returns (outputs and their schema)
- What it must NOT do (e.g., context generator must not summarize or paraphrase the chunk itself — only prefix it)
- How to handle failure (cache miss, API timeout, malformed output)
Step 4: Prove It Works with Retrieval Failure Rate at Top-20
You cannot eyeball this. The only honest validation is failure rate on a held-out evaluation set. Anthropic measures it as: percentage of queries where the ground-truth relevant chunk is not in the top-20 retrieved chunks. Lower is better.
Validation checklist:
- Baseline measurement — failure looks like: you cannot tell if the pipeline is improving because you never measured the no-context baseline first. Build the eval set before you build stage 1.
- Stage-by-stage ablation — failure looks like: you turn on context, fusion, and rerank simultaneously and have no idea which one moved the number. Add stages one at a time. Anthropic’s published ablation shows context-only at 35% reduction, context + contextual BM25 at 49%, and the full stack with reranking at 67% (Anthropic Blog). Reproduce that shape on your data, not just the headline number.
- Cost ceiling — failure looks like: retrieval works great, the bill is unsustainable, and nobody can explain where the cost is going. Track per-query token cost across the context generator, the embedder, and the reranker as a single SLO.
- Latency budget — failure looks like: top-20 failure rate dropped, p95 latency tripled, and the product team is the one who notices. Measure both before declaring victory.
- Cache hit rate (Anthropic recipe) — failure looks like: $1.25/MTok cache writes on every batch because your batcher resets the cache between documents. Your spec should state expected cache-hit ratio and alert when it drops.
Security & compatibility notes:
- RAGatouille (ColBERT entry-point): Maintenance is transitioning to the PyLate backend, and integration crashes have been reported when wiring it into RAG pipelines (LangChain issue tracker). Action: pin RAGatouille v0.0.9 (Feb 11, 2025 — RAGatouille GitHub) for stability and plan a PyLate migration path; PyLate (LightOn, arXiv 2508.03555 — PyLate paper) is the modern training and retrieval backend.
- Anthropic prompt cache: Workspace-level cache isolation is in effect as of Feb 5, 2026 (was org-level). Caches no longer span workspaces; treat each workspace as its own cost-and-cache boundary.
- API costs: Prices shown are indicative and may vary. Always check the provider’s current pricing before locking cost numbers into a specification.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Indexed raw chunks, then “added rerank” | The retriever has no document context to rank against | Add stage 1 (context generator) before tuning later stages |
| Ran BM25 on original chunks while embedding contextualized chunks | Lexical and dense layers see different documents — fusion is meaningless | Run “contextual BM25” — BM25 over the same contextualized text |
| Picked voyage-context-3 and the Anthropic LLM-rewrite recipe | Two different “context” mechanisms competing for the same job | Pick one context strategy per pipeline; do not stack them |
Tuned top_k = 5 to save tokens | You truncated below the recall plateau | Retrieve top-20 chunks; let the reranker filter (Anthropic Blog) |
| Built RAG for a 100-page corpus | Pipeline cost more than just stuffing the docs | Skip retrieval if your corpus fits — Anthropic’s threshold is ~200K tokens / ~500 pages |
Pro Tip
The single biggest unlock in any contextual retrieval pipeline is treating the contextualized chunk text as a versioned artifact. Pin its schema, log its hash, and re-run downstream stages only when the artifact changes. Most retrieval regressions come from someone tweaking the context-generation prompt and silently invalidating both indexes — the embeddings and the BM25 — without re-indexing. Make the artifact the contract, not the prompt.
Frequently Asked Questions
Q: How to implement contextual retrieval step by step in 2026? A: Build the five stages in order: context generator (Anthropic recipe with Haiku 4.5 or voyage-context-3), dense index, contextual BM25 index, RRF fusion, reranker. The non-obvious step most teams skip is verifying that your BM25 index runs on the contextualized text, not the raw chunks — that single change moves Anthropic’s ablation from 35% to 49% failure-rate reduction.
Q: How to use Anthropic Contextual Retrieval recipe with Claude Haiku and prompt caching? A: Put the full document in the cached prompt block, the per-chunk instruction in the uncached suffix, and target 50-100 output tokens per chunk. Watch the minimum cacheable block size — Haiku 4.5 requires at least 4,096 tokens (Anthropic Docs), so very short documents either need batching or accept paying uncached input rates.
Q: When should you use voyage-context-3 vs ColBERT late interaction for retrieval? A: Use voyage-context-3 when you want one dense vector per chunk that already carries document context — it is a drop-in replacement for standard embeddings (Voyage AI Blog). Use ColBERTv2 (via RAGatouille or PyLate) when your queries demand token-level matching — code identifiers, error messages, named entities — because MaxSim scores per-token vectors instead of compressing the chunk to one vector. They are not competitors; ColBERT is most often a reranker over a dense first-stage retrieval.
Your Spec Artifact
By the end of this guide, you should have:
- A five-stage pipeline diagram with one input/output contract per stage — context generator, dense indexer, lexical indexer, fusion, reranker.
- A constraint sheet per stage covering model + version, payload limits, cache strategy, quantization, fallback behavior, and the artifact each stage produces.
- A retrieval failure rate eval harness that measures top-20 recall on a held-out set, broken out per ablation tier so you can see which stage moved the number.
- A Query Transformation contract documenting whether queries are rewritten, expanded, or passed through verbatim before retrieval — the upstream stage that silently changes everything downstream.
Your Implementation Prompt
Use this prompt with Claude Code, Cursor, or your AI coding tool of choice when scaffolding the pipeline. Replace every bracketed placeholder with the value from your Step 2 spec — none of the brackets are decorative, each one maps to a specific contract you must own.
You are scaffolding a contextual retrieval pipeline. Implement five stages, each with its own module and tests. Do not couple stages — each one consumes only the artifact produced by the previous stage.
STAGE 1 — Context generator
- Model: [pinned LLM, e.g., claude-haiku-4.5]
- Strategy: [anthropic-recipe | voyage-context-3] (pick exactly one)
- Output length per chunk: [50-100 tokens]
- Prompt cache: document in cached block, per-chunk instruction uncached
- Minimum cacheable block: [4096] tokens; below that, [batch | skip caching]
- On cache miss: [behavior, e.g., proceed and log]
- Failure mode: [behavior on API error]
STAGE 2 — Dense indexer
- Embedding model + version: [e.g., voyage-context-3]
- Vector dimension: [256 | 512 | 1024 | 2048]
- Quantization: [float | int8 | uint8 | binary | ubinary]
- Per-call limits: [1000 inputs, 120000 tokens, 16000 chunks] for voyage-context-3
- Vector store: [name + version]
STAGE 3 — Lexical indexer (contextual BM25)
- BM25 params: k1=[value], b=[value]
- Tokenizer: [name] — must match Stage 2 normalization
- Indexes the same contextualized text as Stage 2 (not raw chunks)
STAGE 4 — Fusion layer
- Algorithm: Reciprocal Rank Fusion, k=[value]
- Top-N per retriever before fusion: [150]
- Output: single ranked list, top-[150]
STAGE 5 — Reranker
- Model + version: [e.g., a Tier-1 cross-encoder]
- Final top-K: [20]
- Latency budget per query: [ms]
- Timeout fallback: return fused-but-unreranked list
VALIDATION
- Build a held-out eval set with ground-truth chunks per query before any other code.
- Measure top-20 retrieval failure rate at each ablation tier:
(a) no context, (b) +context, (c) +contextual BM25, (d) +rerank.
- Track per-query token cost and p95 latency as SLOs alongside failure rate.
CONSTRAINTS
- Do NOT introduce both Anthropic-recipe context AND voyage-context-3 — choose one.
- Do NOT call retrieval if the corpus fits in the model's context (~200K tokens).
- Every stage's artifact must be content-hashed; downstream stages re-run only when their input hash changes.
Ship It
You now have a pipeline you can debug stage-by-stage instead of a black box that “feels worse this week.” When the failure rate moves, you know which contract to look at. When the bill moves, you know whether it is the context generator, the embedder, or the reranker that drifted. That is the difference between a retrieval system you operate and one that operates you.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors