How to Audit ML Models for Bias Using AI Fairness 360, Fairlearn, and What-If Tool in 2026
Table of Contents
TL;DR
- Map protected attributes and pick metrics before touching any toolkit — the wrong metric makes a passing audit meaningless
- Chain three tools: AIF360 for metric breadth, Fairlearn for constrained mitigation, What-If Tool for visual probing
- Define pass/fail thresholds tied to legal standards before running a single computation
Your hiring model scores 94% accuracy. Legal flags it six weeks after deployment. The model predicts correctly — just not equally. Two protected groups see rejection rates that violate the Four Fifths Rule, and nobody caught it because the audit spec never defined what “fair” means for this model. That gap between accuracy and fairness is where this guide lives.
Before You Start
You’ll need:
- Python 3.9-3.11 (AIF360 supports 3.8-3.11; Fairlearn requires >=3.9)
- A trained classification model with predictions on a held-out test set
- Access to Protected Attribute labels in your dataset (race, gender, age, or whatever your domain requires)
- Understanding of Bias And Fairness Metrics — what they measure and why they conflict
This guide teaches you: how to specify a fairness audit as a system — protected groups, metrics, legal thresholds, and toolkit chain — so your AI coding tool generates the right pipeline, not just the right syntax.
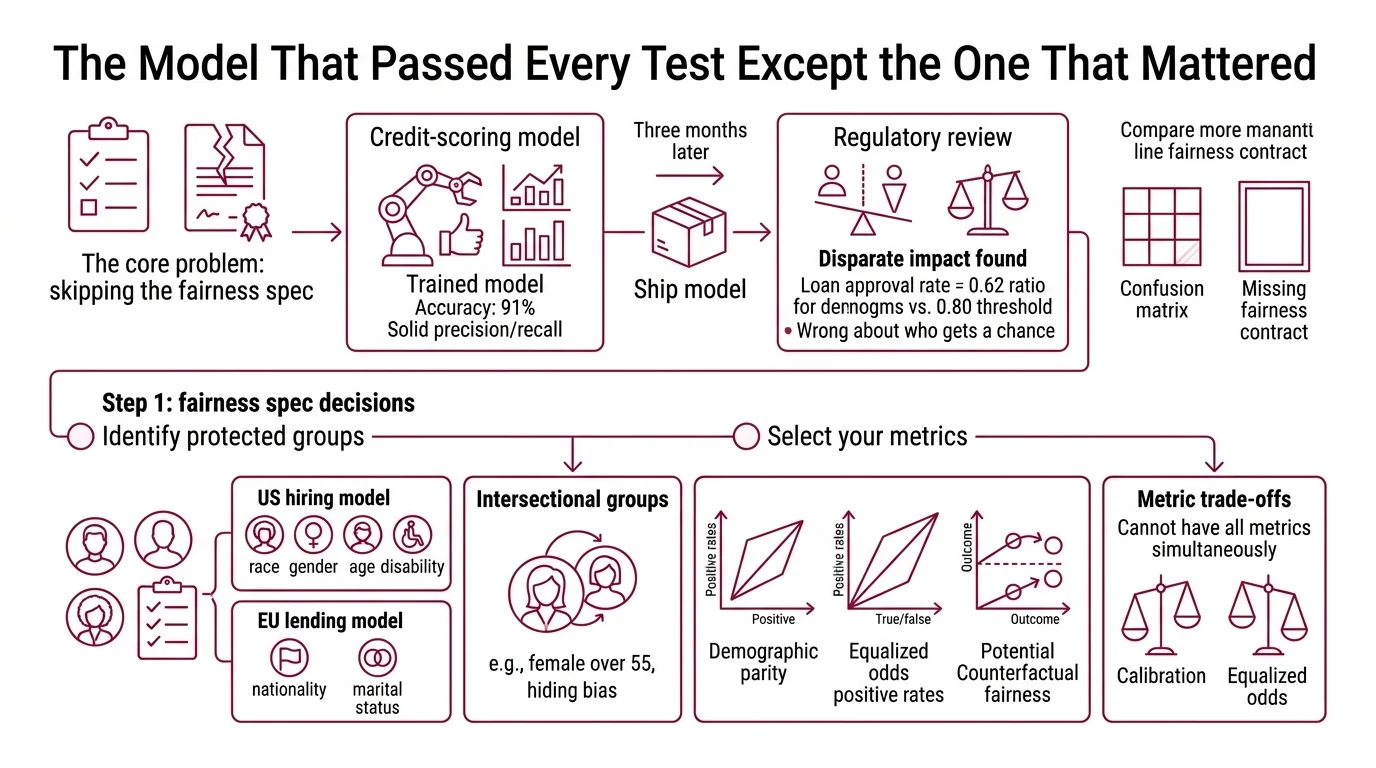
The Model That Passed Every Test Except the One That Mattered
Here is what happens when you skip the fairness spec.
A team trains a credit-scoring model. Accuracy: 91%. Precision and recall: solid. They ship it. Three months later, a regulatory review finds the model approves loans for one demographic at twice the rate of another — after controlling for creditworthiness. The Disparate Impact ratio sits at 0.62. The legal threshold is 0.80.
The model was never wrong about creditworthiness. It was wrong about who gets a chance.
They had a Confusion Matrix. They did not have a fairness contract.
Step 1: Identify Protected Groups and Select Your Metrics
Every fairness audit starts with two decisions: who are you protecting, and how do you define fair? Get these wrong and the rest of the pipeline produces numbers that mean nothing.
Protected groups
Your protected attributes depend on your domain and jurisdiction. A hiring model in the US needs to track race, gender, age, and disability status. A lending model under the EU AI Act adds nationality and marital status. List every attribute before you open a toolkit.
One constraint most teams miss: intersectional groups. “Female” is one group. “Female over 55” is another. The bias that hides in intersections is often worse than the bias in single attributes. Your spec must define which intersections to test.
Metrics — and why you cannot have them all
Demographic Parity asks: does each group get the same positive outcome rate? Equalized Odds asks: given the true label, does each group get the same true positive and false positive rates? Counterfactual Fairness asks: would the prediction change if the protected attribute were different?
These sound complementary. They are not. Calibration and equalized odds cannot hold simultaneously unless the model achieves perfect prediction or the base rates are equal across groups (Kleinberg et al.). That is a mathematical constraint, not a tooling limitation. Pick the metric that matches your legal and ethical obligation — do not try to optimize all of them at once.
For hiring and lending in the US, the four-fifths rule (disparate impact ratio >= 0.80) is the regulatory floor. Start there. Add equalized odds if your use case demands equal error rates across groups.
Step 2: Lock Down the Fairness Contract
Before you generate a single line of audit code, define the contract. This is the specification your AI coding tool needs. Skip any item and you hand the AI a spec with gaps. It will fill those gaps on its own — the same Hallucination behavior you see in any underspecified prompt, except here the invented values decide whether your model passes a regulatory audit.
Fairness contract checklist:
- Protected attributes listed (with intersections)
- Primary metric chosen (demographic parity, equalized odds, or disparate impact)
- Secondary metric chosen (if required by domain)
- Pass/fail threshold set (e.g., disparate impact ratio >= 0.80)
- Dataset split specified (audit runs on held-out test set, never training data)
- Baseline model identified (if comparing pre- and post-mitigation)
- Mitigation strategy selected (threshold adjustment, constrained optimization, or reweighting)
The Spec Test: If your fairness contract does not name the protected attributes, the toolkit will either audit the wrong groups or skip the audit entirely. AIF360 requires you to specify
privileged_groupsandunprivileged_groupsexplicitly — there is no auto-detection.
Step 3: Wire the Toolkit Chain
Three tools. Three jobs. Each one covers a gap the others leave open.
AI Fairness 360 — metric breadth
AIF360 ships 70+ fairness metrics and 15 debiasing algorithms (AIF360 Docs). It is the most extensive open-source fairness toolkit available as of 2026, now governed by the LF AI & Data Foundation. Use it for the initial diagnostic pass — compute every metric your contract requires in one run.
AIF360 v0.6.1 runs on Python 3.8-3.11. If your team has moved to Python 3.12+, expect compatibility issues — pin your audit environment to 3.11.
The toolkit operates on a BinaryLabelDataset or StandardDataset object. Your spec must define: which column is the label, which columns are protected attributes, and which values mark the privileged group. Miss any one of these and the metrics compute on garbage.
Fairlearn — constrained mitigation
Fairlearn v0.13.0 is the strongest open-source option for constrained optimization (Fairlearn PyPI). Where AIF360 tells you what is wrong, Fairlearn’s mitigation algorithms fix it under constraints you define.
MetricFrame is your starting point — it disaggregates any scikit-learn metric by group. Then ExponentiatedGradient retrains under a fairness constraint (e.g., equalized odds with a tolerance you specify). ThresholdOptimizer adjusts decision thresholds per group without retraining.
Your spec must define which mitigation path to use. Retraining is cleaner but slower. Threshold adjustment is faster but shifts the accuracy-fairness trade-off per group. Name the trade-off before you pick the path.
What-If Tool — visual probing
The What-If Tool runs inside TensorBoard, Jupyter, or Colab. It computes demographic parity, equal opportunity, and three additional fairness types through a visual interface — no code required for the exploration phase.
Use it for two things your scripts cannot do well: spotting patterns in individual predictions, and showing non-technical stakeholders what the bias looks like.
Compatibility note: The What-If Tool’s last PyPI release was v1.8.1 in October 2021 (WIT PyPI). It still functions but has not been updated in over four years. Test compatibility with your current TensorFlow and Jupyter versions before adding it to your audit spec. If it fails to load, use Fairlearn’s visualization utilities as a fallback.
Step 4: Prove the Audit Holds
Running the metrics is not the audit. Validating the metrics against your contract is the audit.
Validation checklist:
- Disparate impact ratio computed for every protected group — failure looks like: ratio below threshold but only checked for one group while another was ignored
- Equalized odds gap computed for true positive and false positive rates — failure looks like: TPR gap passes but FPR gap fails, and you only checked one
- Mitigation applied and re-evaluated — failure looks like: post-mitigation accuracy dropped below your minimum acceptable threshold, meaning you over-corrected
- Intersectional groups tested — failure looks like: single-attribute audit passes, but “female over 55” subgroup fails the four-fifths rule
Common Pitfalls
| What You Did | Why the Audit Failed | The Fix |
|---|---|---|
| Audited on training data | Metrics reflect what the model memorized, not how it generalizes | Always audit on a held-out test set |
| Picked one metric only | Passed demographic parity, failed equalized odds — regulator flagged it | Define primary AND secondary metrics in your contract |
| Skipped intersectional groups | Single-attribute audit passed; combined subgroup failed | List intersectional groups explicitly in your spec |
| Used AIF360 on Python 3.12 | Import errors, silent metric failures | Pin audit environment to Python 3.9-3.11 |
| Treated mitigation as one-shot | Post-mitigation model drifted; bias returned in three months | Add fairness metrics to your production monitoring |
Pro Tip
Your fairness contract is a living document. Models drift. Data distributions shift. The audit that passed in March may fail in September. Specify a re-audit cadence in your deployment contract — quarterly is the minimum for high-stakes models. Treat fairness metrics like latency metrics: monitor them continuously, alert on threshold violations, and re-run the full audit pipeline when the alert fires.
Frequently Asked Questions
Q: How to implement bias detection with AI Fairness 360 and Fairlearn step by step?
A: Define your fairness contract first — protected groups, metrics, thresholds. Use AIF360’s BinaryLabelDataset for baseline metrics, then Fairlearn’s MetricFrame for disaggregated analysis and ExponentiatedGradient for constrained mitigation. Edge case: if your model is a regressor, AIF360 assumes binary labels — bin your continuous output before running the audit.
Q: How to use fairness metrics to audit a hiring or lending model for discrimination?
A: For US hiring, compute the disparate impact ratio per protected group and flag anything below 0.80. For lending, add equalized odds to catch unequal error rates. Watch for intersectional failures — auditing gender and race separately often misses that a combined subgroup like “women over 50” fails the threshold alone.
Q: How to integrate bias monitoring into ML production pipelines with Credo AI and Fiddler in 2026?
A: Credo AI offers an AI registry with EU AI Act and NIST AI RMF compliance packs (Credo AI). Fiddler monitors disparate impact across SageMaker, Vertex AI, and Databricks in real time (Fiddler AI). Both use custom enterprise pricing — start the budget conversation before proof-of-concept.
Your Spec Artifact
By the end of this guide, you should have:
- A fairness contract: protected groups, primary and secondary metrics, pass/fail thresholds, and intersectional groups to test
- A toolkit chain spec: AIF360 for diagnostic metrics, Fairlearn for constrained mitigation, What-If Tool for visual probing (with fallback noted)
- A validation checklist: per-group metric thresholds, mitigation re-evaluation criteria, and a re-audit cadence
Your Implementation Prompt
Copy this into Claude Code, Cursor, or your AI coding tool. Replace the bracketed placeholders with values from your fairness contract.
Build a Python fairness audit pipeline for a [binary classification / regression] model using AIF360 and Fairlearn. Python 3.9-3.11.
PROTECTED ATTRIBUTES:
- [attribute_1, e.g., "gender"] with privileged value [value, e.g., "male"]
- [attribute_2, e.g., "race"] with privileged value [value, e.g., "white"]
- Intersectional group: [attribute_1 + attribute_2 combination to test]
METRICS CONTRACT:
- Primary metric: [demographic_parity / equalized_odds / disparate_impact]
- Secondary metric: [equalized_odds / calibration / none]
- Pass threshold: disparate impact ratio >= [0.80]
- Acceptable accuracy loss from mitigation: [max percentage drop, e.g., 3%]
PIPELINE STEPS:
1. Load held-out test set from [CSV path / DataFrame]. Label column: [column_name]. Protected columns: [column_names].
2. Create AIF360 BinaryLabelDataset. Compute: disparate impact ratio, statistical parity difference, equalized odds difference for each protected group.
3. Use Fairlearn MetricFrame to disaggregate [accuracy, precision, recall, selection_rate] by each protected group.
4. If any metric fails the pass threshold, apply mitigation:
- Strategy: [ExponentiatedGradient with equalized odds constraint / ThresholdOptimizer / Reweighting]
- Re-compute all metrics post-mitigation.
5. Output a summary table: group, metric, pre-mitigation value, post-mitigation value, pass/fail.
CONSTRAINTS:
- Do not use training data for the audit — held-out test set only.
- Handle [intersectional group] as a separate audit group.
- If post-mitigation accuracy drops more than [max percentage drop], flag the trade-off instead of silently accepting.
- Pin AIF360 to v0.6.1 and Fairlearn to v0.13.0 for reproducibility.
Ship It
You now have a specification framework for fairness audits — not just the tools, but the contract that tells them what to check, what thresholds to enforce, and what to do when mitigation costs accuracy. The decomposition works the same way whether you are auditing a hiring model, a credit scorer, or a content moderation system. Protected groups change. The specification pattern does not.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors