Add Reranking to Your RAG Pipeline: Cohere, Voyage, Zerank-2 in 2026
TL;DR
- A reranker is a precision pass between hybrid retrieval and the LLM — it can fix the order, never the recall
- Three managed APIs now ship 32K-token contexts; one of them — Zerank-2 — has a CC-BY-NC license that quietly blocks commercial use
- Self-hosting BGE Reranker v2-m3 or mxbai-rerank-large-v2 only pays off when you have measured retrieval quality and a serving budget
Here’s the failure I keep seeing in 2026 RAG builds. Vector search returns the right document — at rank 7. The LLM only reads the top 3. The user gets “I don’t have that information.” The team blames the embedding model. The embedding model is fine. The pipeline skipped the Reranking stage.
Before You Start
You’ll need:
- A working Retrieval Augmented Generation pipeline with a measurable retrieval baseline (Recall@20 and Recall@50)
- Hybrid Search retrieval already wired up — BM25 + dense, fused with RRF
- A budget decision: are you token-pricing reranks or running GPUs?
- Familiarity with Cross-Encoder architecture and why it differs from the bi-encoder retrievers you already deployed
This guide teaches you: how to decide WHEN reranking earns its latency budget, WHICH API or open-weight model fits your constraints, and HOW to specify the retrieve→rerank→generate contract so an AI coding tool can wire it without hallucinating endpoints.
The Reranker That Reordered Documents Nobody Wanted
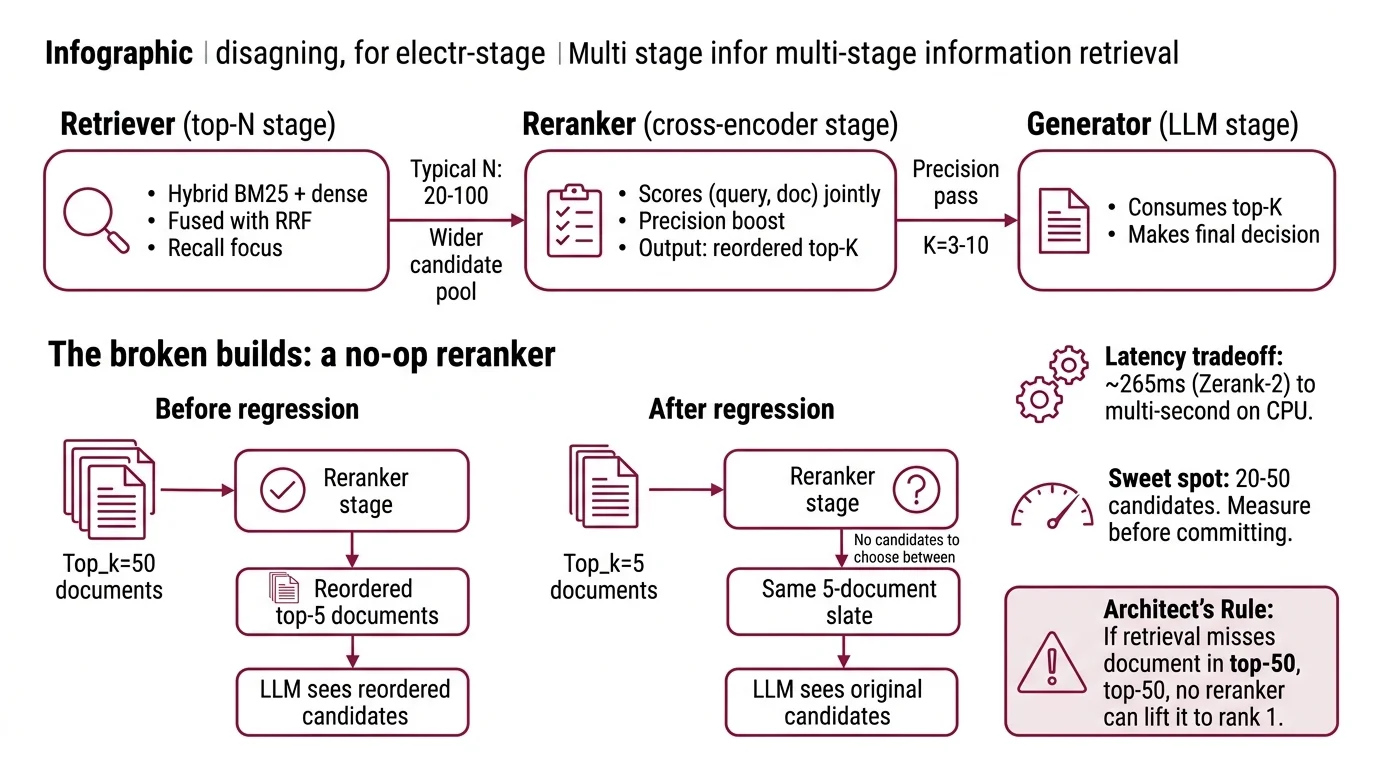
Three months ago a team I worked with shipped a reranker on top of a top-5 retrieval. They reordered five documents. Their relevance metrics didn’t move. Why would they? The reranker wasn’t choosing between candidates — there were no real candidates to choose between. They paid token cost, added 600ms of latency, and reordered the same five-document slate the LLM was going to see anyway.
It worked on Friday. On Monday, search quality regressed because someone changed retrieval from top_k=50 to top_k=5 to “save tokens” — and silently turned the reranker into a no-op.
A reranker is a precision pass over a wider candidate pool. If your candidate pool is already small, you have a retrieval problem, not a ranking problem.
Step 1: Identify the Three-Stage Pipeline
A 2026 reranker stage sits between two boundaries. Both boundaries matter more than the model you pick.
Your system has these parts:
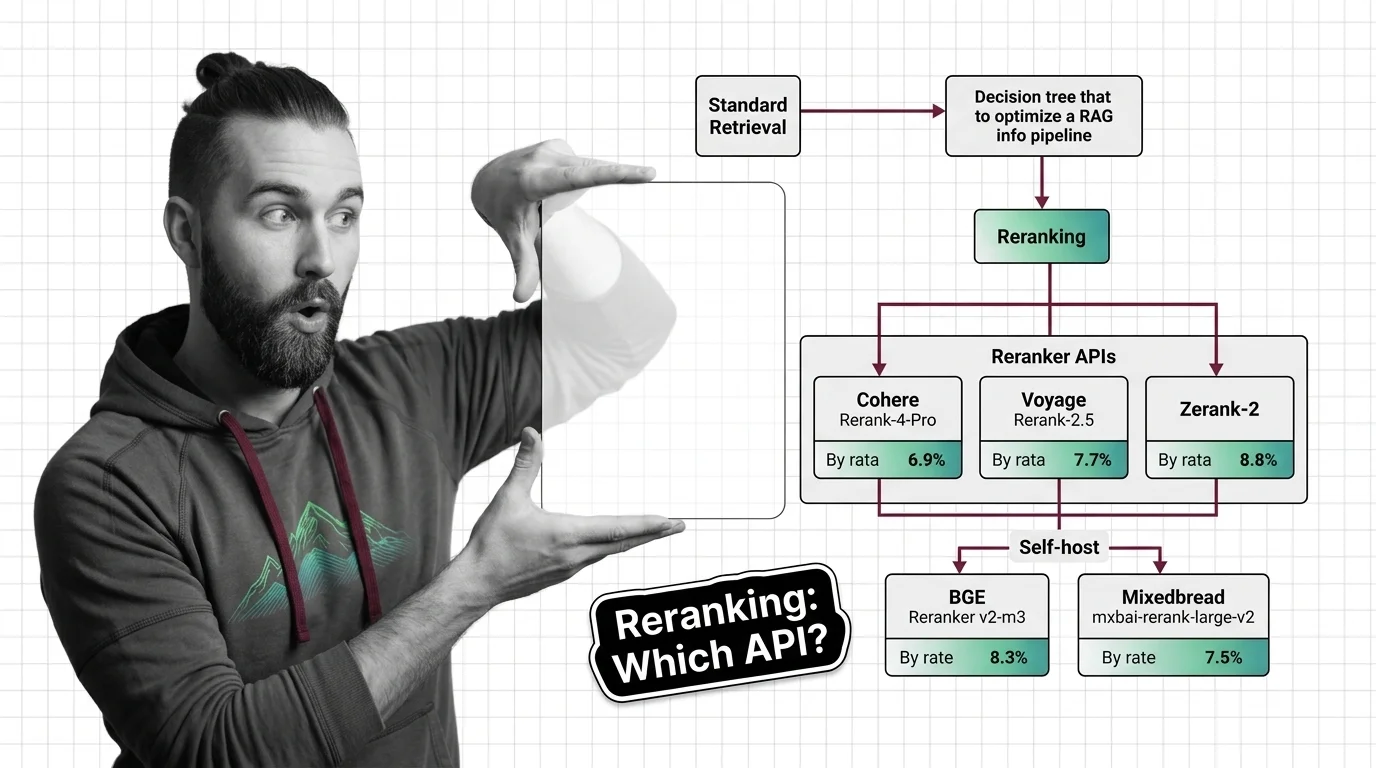
- Retriever (top-N stage) — hybrid BM25 + dense, fused with Reciprocal Rank Fusion. Typical N is 20-100. This is where recall lives. The reranker boosts precision but cannot recover documents the retriever missed (Superlinked VectorHub).
- Reranker (cross-encoder stage) — a cross-encoder that scores every (query, document) pair jointly. Output: a reordered top-K, where K is 3-10. Latency ranges from ~265ms (Zerank-2 on the Agentset leaderboard) to multi-second on open weights served on CPU.
- Generator (LLM stage) — consumes top-K. The whole point of reranking is to make sure the right document is inside K, not at K+1.
The Architect’s Rule: If your retrieval doesn’t put the right document anywhere in the top-50, no reranker on earth will lift it to rank 1.
The boundary that breaks builds is the candidate pool size. Too small (5-10) and the reranker has nothing to choose. Too large (200+) and you blow the latency budget. Twenty to fifty is the sweet spot — measure before you commit.
Step 2: Lock Down the Reranker Contract
Before you call any rerank endpoint, pin the spec. Every reranker in this cluster differs on one of these axes — and the difference becomes a production incident if it’s not in your context.
Context checklist:
- Model identifier and version —
rerank-v4.0-provsrerank-v4.0-fast(Cohere);rerank-2.5vsrerank-2.5-lite( Voyage Rerank family);zerank-2vszerank-1-small(ZeroEntropy) - Token-counting formula — Voyage uses
(query_tokens × num_documents) + sum(document_tokens), per Voyage Docs. Cohere migrated from per-search billing ($2 per 1,000 searches on Rerank 3.5) to per-token on Rerank 4 — cost re-estimation is required when migrating. - Context window per (query, document) pair — Cohere Rerank 4, Voyage Rerank-2.5, and Zerank-2 all ship 32K tokens. BGE Reranker v2-m3 is capped at 8K — a major constraint for long-document RAG.
- License gate — Zerank (Zerank-2) and Jina Reranker (Jina Reranker v3) ship CC-BY-NC-4.0 weights, per Hugging Face. Pulling either weight into a paid product without a commercial SKU is a license violation.
- Failure mode — what does the system do if the reranker times out at 7 seconds? Fall back to retrieval order, or fail the request?
- Multilingual scope — every model in this cluster is multilingual on paper. Validate on your actual languages before betting on it.
The Spec Test: If your context file doesn’t list the license SKU you intend to use, the AI tool will copy the most-cited HuggingFace example into your code. That example will almost certainly be a CC-BY-NC weight. You will discover this in legal review, not in production.
Step 3: Sequence the Three Decisions
Build the spec in this order. Skip steps and you’ll rip out the integration twice.
Decision order:
- License gate first — because it eliminates options instantly. Commercial use? Cohere Rerank 4 (any cloud), Voyage Rerank-2.5 (Voyage API or MongoDB Atlas bundle), BGE v2-m3 (Apache 2.0), or Mixedbread Rerank mxbai-rerank-large-v2 (Apache 2.0). Non-commercial / research only? Zerank-2 weights, Jina Reranker v3 weights — or pay for their commercial APIs.
- Hosting model second — because it sets your operational ceiling. Token-priced API: zero ops, predictable latency, per-call cost. Self-host: GPU budget, throughput tuning, and a serving stack like vLLM or Text Embeddings Inference (TEI).
- Quality vs latency vs cost — only now does the actual model choice matter. Once 1 and 2 are pinned, you have at most three candidates left. This is where you measure on your data, not on a vendor blog post.
For the integration spec, your context must specify:
- Receives — query string, candidate list (chunk text + metadata), desired top-K
- Returns — reordered list with
relevance_scoreper item, NOT a binary keep/drop - Must NOT — call the LLM, mutate metadata, merge documents, log text outside the existing trust boundary
- Failure handling — timeout fallback, rate-limit backoff, license-violation guard at the dependency layer
Build the contract before the call site. The reranker should be swappable in one config change — because by Q4 2026, half this leaderboard will have moved.
Step 4: Validate Before You Trust the Numbers
Vendor benchmarks are the loudest signal in this market. Treat them as marketing claims until you measure on your own data. Voyage’s own benchmarks report +7.94% over Cohere Rerank v3.5 on standard datasets, per Voyage Docs. ZeroEntropy claims Zerank-2 wins against Cohere Rerank 3.5 and Voyage rerank-2/2.5 on instruction-following. Cohere positions Rerank 4 Pro as their state-of-the-art quality tier. All three are vendor-self-reported.
The Agentset Reranker Leaderboard is closer to neutral. As of its 15 February 2026 snapshot, it puts Zerank-2 first on head-to-head ELO at 1638, Cohere Rerank 4 Pro second at 1629, and Voyage Rerank-2.5 fourth at 1544 (Agentset Reranker Leaderboard). Treat this as a snapshot, not a constant — leaderboards in this cluster move with each model release.
Validation checklist:
- Baseline retrieval quality — failure: turning on the reranker shifts metrics by noise-level 2-3%. The reranker isn’t the bottleneck.
- Candidate pool size sweep — failure: top_k=5, 20, and 50 all produce identical reranked top-3. The reranker is doing nothing.
- License compliance scan — failure: a
huggingface.co/zeroentropy/zerank-2import in production code without a paid SKU. - Latency P95 under realistic load — failure: a vendor benchmark used 5 documents and your traffic passes 50.
- Token cost per call (worst case) — failure: a billing surprise. Voyage’s formula multiplies query tokens by document count.
- Swap-test runbook — failure: no procedure for swapping vendors in a sprint when commercial pricing changes.
Pricing & migration notes:
- Cohere token-rate verification: Cohere migrated from per-search ($2 per 1,000 searches on Rerank 3.5) to per-token on Rerank 4. The token rate is not on Cohere’s public pricing page at the time of writing — that page currently lists Model Vault dedicated SKUs ($5/hr Medium, $10/hr Large for Pro tier, per Cohere’s pricing page). Pin pricing as a config var and consult cohere.com/pricing on integration day.
- Cohere Rerank 3.5 deprecation (WARNING): Tutorials referencing
rerank-v3.5are outdated. New builds should pinrerank-v4.0-proorrerank-v4.0-fast. The API now requires themodelparameter;max_chunks_per_docwas replaced bymax_tokens_per_doc(Cohere Docs).- Zerank-2 / Jina Reranker v3 license (WARNING): HuggingFace weights ship CC-BY-NC-4.0. Commercial deployment requires the ZeroEntropy paid contract / AWS or Azure Marketplace SKU for Zerank-2, or Jina’s paid API for Jina Reranker v3.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Reranked a top-5 retrieval | The reranker has nothing to compare against | Sweep candidate pool 20→50 and measure the delta |
| Compared BEIR scores to Agentset ELO | Different benchmarks, different test sets, not directly comparable | Quote each on its own table; never mix in one comparison |
| Pasted Zerank-2 weights into a SaaS product | CC-BY-NC license blocks commercial use | Use ZeroEntropy paid API or AWS/Azure Marketplace SKU |
| Locked the rate to a vendor blog post number | Token rates change; some are not on the public pricing page | Make pricing a config var; budget against the live pricing page |
| Trusted vendor SOTA claims at face value | Every vendor reports SOTA against the same competitors | Use neutral leaderboards plus your own eval set |
Pro Tip
Treat the reranker as a swappable interface, not a vendor commitment. Define the input/output contract once — query string, candidate list with chunk text and metadata, top-K, returned relevance_score. Wire your code to the contract. The reranker behind the contract should be a single config line. Zerank-2 shipped in November 2025. Cohere Rerank 4 in December 2025. The next leader will probably ship before this article is six months old. By the time
Agentic RAG workflows make reranking a per-step decision rather than a single pipeline stage, your spec should already be portable.
Frequently Asked Questions
Q: When should you add a reranker to a RAG pipeline? A: Add a reranker when your retrieval Recall@50 is meaningfully better than your Recall@5 — that gap is the precision headroom a reranker can capture. Skip it for top-5 retrievals or factoid lookups with one obvious answer. Reranking solves precision, not recall — fix the retriever first.
Q: Cohere Rerank vs Voyage Rerank vs Zerank: which reranking API should you choose in 2026? A: Default to Cohere Rerank 4 Pro for commercial multi-cloud builds (AWS Bedrock, Azure, OCI). Pick Voyage Rerank-2.5 to burn down the 200M-token free tier or if you’re on MongoDB Atlas. Pick Zerank-2 only with a paid contract — the open weights are CC-BY-NC, per Hugging Face.
Q: How to integrate a reranker into a vector search pipeline step by step? A: Retrieve top-N (N=20-50) from hybrid search with RRF fusion, send (query, candidate_list) to the rerank endpoint, take the returned top-K (K=3-10), pass to the LLM. Wrap the rerank call in a timeout-fallback that returns retrieval order on failure. Pipeline shape per Superlinked VectorHub.
Q: How to self-host BGE Reranker v2-m3 or Mixedbread mxbai-rerank-large-v2 for production reranking? A: Both are Apache 2.0. BGE v2-m3 is 0.6B params with 8K context — deploy via FlagEmbedding or sentence-transformers. mxbai-rerank-large-v2 is 1.5B params with BEIR-13 average nDCG@10 of 57.49 (Mixedbread Blog). Run either behind vLLM or Text Embeddings Inference. The 8K cap on BGE is the gotcha for long-document RAG.
Your Spec Artifact
By the end of this guide, you should have:
- A retrieval-quality baseline — Recall@20 and Recall@50 on your eval set, with the gap quantified. Without this, the reranker is theater.
- A reranker selection contract — license gate (commercial vs. non-commercial), hosting model (token-priced API vs. self-hosted), and the candidate pool size you’re committing to (typical: top-50 → top-5)
- A validation runbook — license-compliance scan, candidate-pool sweep, P95 latency measurement under realistic load, and a swap path so the reranker is a one-config change
Your Implementation Prompt
Drop this into Claude Code, Cursor, or Codex once your retrieval baseline is measured. Replace the bracketed placeholders with values from your Step 2 context checklist. The prompt mirrors the four-step framework — license gate, hosting decision, integration contract, validation criteria.
Build a reranker stage for our RAG pipeline. Follow this specification exactly.
## Pipeline shape
- Upstream: hybrid retrieval (BM25 + dense, RRF fusion) returning top-[CANDIDATE_POOL_SIZE, e.g., 50]
- This stage: cross-encoder reranker, returns top-[FINAL_K, e.g., 5]
- Downstream: LLM call (do NOT generate the LLM call in this stage)
## Reranker selection (license-first)
- Commercial use required: [YES / NO]
- Selected model: [e.g., rerank-v4.0-pro / rerank-2.5 / mxbai-rerank-large-v2]
- License: [e.g., Cohere Terms / Voyage Terms / Apache 2.0]
- Hard constraint: NEVER import a CC-BY-NC weight (Zerank-2 HF, Jina Reranker v3 HF) without a paid commercial SKU.
## Hosting
- Mode: [token-priced API / self-hosted]
- Endpoint or serving stack: [e.g., https://api.cohere.com/v2/rerank / vLLM / Text Embeddings Inference]
- Auth: [API key env var name / mTLS / none]
## Integration contract
- Input: { query: string, documents: [{ id, text, metadata }], top_k: int }
- Output: [{ id, relevance_score: float, original_rank: int, new_rank: int }]
- Must NOT: call the LLM, mutate document metadata, merge documents, log document text outside the existing trust boundary
- Timeout: [e.g., 1500ms]
- Failure behavior: on timeout/5xx, return original retrieval order with relevance_score = null and a structured warning
## Token-cost guard (token-priced APIs only)
- Compute estimated tokens per call using the vendor formula:
Voyage: (query_tokens × num_documents) + sum(document_tokens)
Cohere: per-token; see cohere.com/pricing for the current rate
- Reject calls where estimated cost > [BUDGET_PER_CALL_USD]
## Validation (must pass before merging)
- Unit: rerank({trivial query, 3 docs}) returns 3 results, scores in [0,1]
- Integration: feed eval set, compute Recall@K_final, must beat retrieval baseline by [MIN_DELTA, e.g., 5%]
- License scan: grep dependency tree for non-commercial weight URLs and fail the build if found
- Latency: P95 under [N_CONCURRENT, e.g., 20] concurrent calls is below [P95_BUDGET_MS]
- Swap test: switch model from selected to a fallback in one config line; tests still pass
Output: integration code + tests + a short markdown runbook with the swap procedure. No vendor lock-in beyond the config layer.
Ship It
You now have a mental model: reranking is a precision pass on a candidate pool the retriever already nailed. License first, hosting second, model third — in that order. Treat the API as a swappable interface and the next reranker that ships in Q3 2026 is a config change, not a refactor.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors