RAG Hallucination Detection with Ragas, TruLens & Guardrails (2026)
Table of Contents
TL;DR
- Faithfulness is a measurable property, not a vibe. If you cannot score it, you cannot fix it.
- One tool will not save you. You need an offline evaluator, a runtime tracer, and a response gate — three different jobs.
- The spec comes before the code. Decide what counts as “grounded” before you wire a single validator.
A retrieval-augmented chatbot ships on a Tuesday. By Thursday it is confidently telling a customer the refund window is 60 days. The docs say 30. The retriever pulled the right paragraph. The generator paraphrased it into something else. Nobody noticed because nobody was scoring whether the answer matched the source.
That is the failure mode this guide is built around — and it is the one a RAG Guardrails And Grounding stack is supposed to catch.
Before You Start
You’ll need:
- A working RAG pipeline (retriever + LLM call) you can instrument
- Familiarity with RAG Evaluation concepts — what an eval set is, how scoring loops work
- A clear definition of Hallucination for your domain (it is not the same in legal as in customer support)
- Python 3.10+ and the ability to add three new dependencies to your inference path
This guide teaches you: how to decompose hallucination control into three layers — offline evaluation, runtime observability, and response-time gating — and how to specify each layer so the AI tool you ask to wire it up actually wires it up correctly.
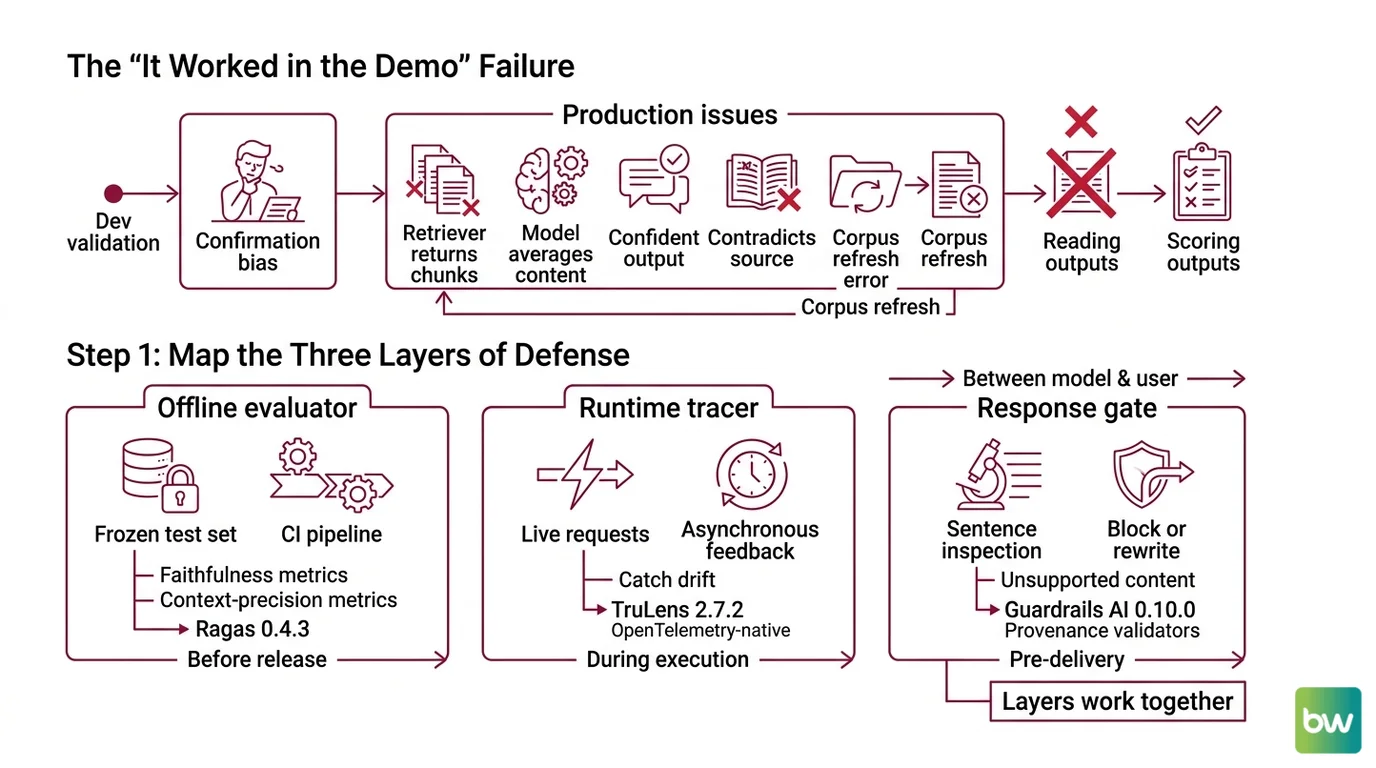
The “It Worked in the Demo” Failure
Most RAG pipelines are validated by the developer scrolling through a dozen Q&A pairs and nodding. That is not evaluation. That is confirmation bias with a notebook.
What goes wrong in production is consistent. The retriever returns chunks that contain the answer plus three unrelated chunks. The model averages them. The output sounds confident, cites nothing falsifiable, and contradicts the source on a detail nobody checks. It worked on Friday. On Monday, the corpus refresh added a marketing page with the wrong refund policy and the model started quoting it.
You will not catch this by reading outputs. You catch it by scoring them — automatically, on every release, and again at runtime.
Step 1: Map the Three Layers of Defense
Hallucination control is not one tool. It is three jobs running at three different times, and they fail differently. Decompose before you specify.
Your system has these parts:
- Offline evaluator — runs on a frozen test set in CI. Tells you whether a code change to the retriever or prompt made faithfulness go up or down. This is where Faithfulness and Context Precision metrics live. The tool of record here is Ragas — current version 0.4.3 (Ragas on PyPI).
- Runtime tracer — emits structured traces from every live request, with feedback functions that score each trace asynchronously. This is where you catch drift between your eval set and reality. TruLens 2.7.2 owns this slot, and as of TruLens 2.x the tracing backbone is OpenTelemetry-native (TruLens Docs).
- Response gate — sits between the model and the user, inspects the generated response sentence by sentence, and blocks or rewrites anything unsupported. This is the Guardrails layer. Guardrails AI 0.10.0 plays this role with its provenance validators (Guardrails AI on PyPI).
These layers do not replace each other. Offline evaluation tells you whether your system can be faithful. Runtime tracing tells you whether it is being faithful. The response gate is the seatbelt for the cases where the first two layers were wrong.
The Architect’s Rule: If you cannot say which layer caught a given hallucination, you do not have three layers. You have one tool with three logos.
Step 2: Lock Down What “Grounded” Means
Before you install anything, write the contract. The reason most teams bolt on Ragas, get a faithfulness score of 0.71, and then argue for two weeks about whether that is good is that they never specified what “grounded” means for their domain.
Context checklist:
- Definition of a claim. Is a claim every assertion, every numeric value, every sentence? Ragas faithfulness is the ratio of claims in the response supported by retrieved context (Ragas Docs). You inherit their decomposition unless you override it. Decide which.
- Source of truth. Is “supported” measured against retrieved chunks only, or against the whole corpus? The former is what Ragas faithfulness scores. The latter is a different problem and needs a different tool.
- Score threshold for shipping. If faithfulness drops below X on the eval set, the build fails. Pick X before you measure, not after.
- Score threshold for blocking at runtime. When the response gate fires, what does it do? Strip the unsupported sentence? Refuse the answer? Hand off to a human? Each is a different spec.
- What “context precision” should pressure. Context precision rewards relevant chunks ranked high (Ragas Docs) — it is a retriever metric, not a generator metric. Use it to tune chunking and reranking, not to judge the LLM.
The Spec Test: If two engineers on your team would mark the same response differently as “grounded” or “hallucinated,” your guardrail will be inconsistent in exactly that way. Resolve it now.
Step 3: Wire the Layers in Order
Build order matters because each layer needs the artifacts the previous one produces. Doing it backwards is how teams end up with a runtime gate that blocks responses they have never measured offline.
Build order:
- Offline evaluator first. You need a faithfulness baseline before anything else makes sense. Build a 100–500 example eval set with known-good answers. Wire Ragas in CI. Make it produce two numbers per build: faithfulness and context precision. Nothing else ships until this is green.
- Runtime tracer second. Once you trust the offline number, instrument live traffic with TruLens. The RAG Triad — context relevance, groundedness, and answer relevance (TruLens Docs) — is the right starter set. Sample your traffic; you do not need to score every request. The OpenTelemetry-native architecture means TruLens slots into existing observability stacks without forcing a new sidecar.
- Response gate last. Only after you have eval and runtime visibility should you put a blocking validator in the inference path. Guardrails AI’s
ProvenanceLLMandProvenanceEmbeddingsvalidators inspect each sentence for claims unsupported by source text (Guardrails AI’s GitHub repository). Wire the validator in shadow mode for the first week — log what it would have blocked, compare to your eval signal, then turn enforcement on.
For each layer, your context must specify:
- Inputs: what artifact the layer consumes (eval CSV, OTel trace, generated response)
- Outputs: what it produces (CI score, dashboard event, blocked response or rewrite)
- Failure mode: what happens when the layer itself errors (skip vs. block — pick one and document it)
- Cost ceiling: offline runs are free time; runtime scoring is per-request latency. Budget it.
If you are choosing a hallucination judge rather than a framework, the two open options worth knowing are
Vectara HHEM and
Patronus Lynx. Vectara HHEM-2.3 is the commercial scorer — multilingual across 11 languages, returned with every Vectara query (Vectara Docs); HHEM-2.1-Open is the open-weights fallback on Hugging Face and Kaggle (Vectara Blog). Patronus Lynx ships in 8B and 70B variants (Patronus AI Blog) and remains a useful local judge — but the latest checkpoint is Llama-3-Patronus-Lynx-8B-v1.1 from 2024, with no public release since (Patronus AI Announcement). Treat it as stable rather than current, and benchmark against a newer judge before making it your primary signal.
For the harder enterprise case — where you also need topic safety, jailbreak detection, and tool-call gating — Nemo Guardrails v0.20.0 wraps the response gate plus an I/O rail engine that runs content-safety, topic-safety, and jailbreak detection in parallel (NVIDIA NeMo Guardrails Docs). Its server is OpenAI-compatible and ships as a microservice container for Kubernetes (NVIDIA NeMo Guardrails). Spec it in if you need policy beyond grounding; skip it if faithfulness is your only target.
Step 4: Validate That the Layers Actually Catch Things
A guardrail you never test is decoration. The validation step is where you prove each layer does what its spec says.
Validation checklist:
- Offline regression test — push a known-bad prompt change (one that produces hallucinated output) and verify Ragas faithfulness drops below your threshold and CI fails. Failure looks like: the score does not move, which means your eval set is too easy.
- Runtime trace audit — pull a day of TruLens traces and manually grade 50 sampled responses. Compare your grades to the RAG Triad scores. Failure looks like: groundedness scores correlate poorly with your manual grades, which means your judge prompt needs work.
- Response-gate red team — feed the gate ten responses you handcrafted to be hallucinations grounded in nothing. Verify each one is blocked or rewritten. Failure looks like: the gate misses sentences that contradict the retrieved context, which usually means the source-of-truth chunk was not passed to the validator.
- End-to-end smoke — put a prompt into the live system that has no answer in the corpus and confirm the user sees a refusal, not an invented answer. Failure looks like: a confident wrong answer reaches the user, which means the layers are not wired in series.
Compatibility & freshness notes:
- Ragas legacy metrics API: Deprecated in 0.4, scheduled for removal in 1.0. Migrate imports from
ragas.metrics(legacy paths) to the newragas.metrics.collectionsAPI before upgrading past 0.4.x (Ragas Docs).- Patronus Lynx: No public model release since v1.1 in 2024 — about 22 months stale by May 2026. If you adopt it, run a side-by-side comparison against a newer judge (e.g., Vectara’s FaithJudge) on your own corpus before making it primary.
- Vectara hallucination leaderboard: Methodology shifted from HHEM-only scoring to FaithJudge with human annotation on a new 32K-token dataset. Old leaderboard rankings are not directly comparable to the new ones (Vectara Blog) — do not pick a model purely on the historical ranking.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Used Ragas faithfulness as your only metric | A response can be faithful to retrieved chunks that are themselves wrong | Add context precision and a corpus-level audit, not just chunk-level scoring |
| Put Guardrails AI in blocking mode on day one | The validator threshold was untuned, blocked correct answers, users complained | Run the gate in shadow mode for a week, tune on real traffic, then enforce |
| Adopted the Vectara hallucination leaderboard ranking as the model decision | The 2025 leaderboard refresh changed scoring methodology — old rankings are not comparable to new ones | Re-run the benchmark on your own corpus with FaithJudge before deciding |
| Bolted on TruLens without sampling | Per-request scoring doubled inference cost in production | Sample 5–10% of traffic, score asynchronously, raise the rate only when investigating an incident |
| Treated “guardrail installed” as “hallucinations solved” | Industry-reported reductions of 71–89% (per a SwiftFlutter survey) come from layered systems, not single tools | Specify and measure each layer separately; do not credit the bundle |
Pro Tip
Write the eval set before you pick the tools. The eval set is the spec. It tells you what “good” looks like in your domain, and it survives every framework migration. Tools come and go — Ragas was on a different metrics API a year ago, TruLens just rebuilt on OpenTelemetry, and Guardrails Hub keeps adding validators. The 200 examples that define faithfulness for your product outlast all of them.
Frequently Asked Questions
Q: How to use Ragas to measure faithfulness and context precision in a RAG pipeline?
A: Build an eval dataset with question, ground-truth answer, and the retrieved context per row, then run the Faithfulness and ContextPrecision metrics from Ragas’s collections API in CI. The watch-out: if you are still on the legacy ragas.metrics import paths, plan the migration now — they are deprecated in 0.4 and will be removed in 1.0 (Ragas Docs).
Q: How to integrate Vectara HHEM or Patronus Lynx for hallucination scoring in production? A: HHEM-2.3 ships with every Vectara query response (Vectara Docs), so if you use Vectara as your retriever you get the score for free; otherwise, use HHEM-2.1-Open from Hugging Face as a local judge. Patronus Lynx 8B runs locally for cost-sensitive setups — but the v1.1 checkpoint is from 2024, so benchmark it on your data before relying on it as primary (Patronus AI Announcement).
Q: How to build a RAG guardrails pipeline step by step with TruLens and Guardrails AI in 2026?
A: Wire TruLens RAG Triad feedback functions (TruLens Docs) onto your live inference path for tracing, then layer Guardrails AI’s ProvenanceLLM validator in shadow mode for a week before turning enforcement on. Specific gotcha: Guardrails Hub historically required an API key even for local validators — verify against current install docs to avoid a surprise at deploy time.
Your Spec Artifact
By the end of this guide, you should have:
- A three-layer architecture map naming which tool owns offline eval, runtime tracing, and response gating
- A grounding contract that defines a claim, a source of truth, a CI threshold, and a runtime block action
- A validation plan with one explicit test per layer and a documented failure symptom for each
Your Implementation Prompt
Paste the prompt below into Claude Code, Cursor, or Codex when you are ready to wire the layers into your repo. The bracketed placeholders are the decisions you made in Step 2 — fill them in before sending.
You are wiring a three-layer hallucination-detection stack into an existing
RAG pipeline. Follow this spec exactly. Do not invent layers.
## Layer 1 — Offline evaluator (Ragas 0.4.3)
- Eval set: [path to your eval CSV with question, ground_truth, contexts columns]
- Metrics: faithfulness, context_precision (use ragas.metrics.collections, NOT legacy paths)
- CI threshold: faithfulness >= [your number, e.g., 0.85]; build fails below
- Output: write scores to [path/to/ci_artifacts/]
## Layer 2 — Runtime tracer (TruLens 2.7.2, OpenTelemetry-native)
- Wrap the existing RAG chain in a TruLens app
- Feedback functions: RAG Triad (context relevance, groundedness, answer relevance)
- Sampling: [your rate, e.g., 10%] of production requests
- Failure mode: tracer errors are logged, never block the response
## Layer 3 — Response gate (Guardrails AI 0.10.0)
- Validator: ProvenanceLLM with the retrieved chunks as the source corpus
- Mode: shadow for the first [N] days (log only), then enforcing
- On unsupported sentence: [strip | refuse | rewrite — pick one]
- Failure mode: validator errors fall back to [pass | block — pick one]
## Constraints
- Do not modify the retriever or generator code — only wrap them
- All three layers must be independently togglable via env var
- Add one integration test per layer using the Validation Checklist in Step 4
## Validation
- After wiring, run the offline eval and confirm CI artifacts appear
- Send one corpus-absent question and confirm the response gate blocks it
- Pull one TruLens trace and confirm all three RAG Triad scores are populated
Ship It
You now have a way to talk about hallucination as something with a number next to it, and a way to decide which layer to fix when the number moves. The spec — three layers, three jobs, three failure modes — is the part that will outlast every tool version in this article. The next time someone tells you the new RAG framework “solves hallucinations,” you will know which of the three layers they mean and which two they forgot.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors