HarmBench, ToxiGen, and MLCommons Taxonomy: The Datasets and Standards Behind AI Safety Testing

Table of Contents
ELI5
AI safety testing uses specialized datasets and benchmarks — like HarmBench, ToxiGen, and MLCommons AILuminate — to measure whether models produce harmful or toxic outputs. Different benchmarks test different risks.
A model passes one safety benchmark and fails another. Same weights, same inference pipeline — opposite verdicts. That isn’t a flaw in the model. It’s a measurement problem: the benchmarks themselves disagree on what “harmful” means, because they were built to measure fundamentally different failure modes.
Understanding Toxicity And Safety Evaluation starts here — not with the scores, but with the instruments that produce them.
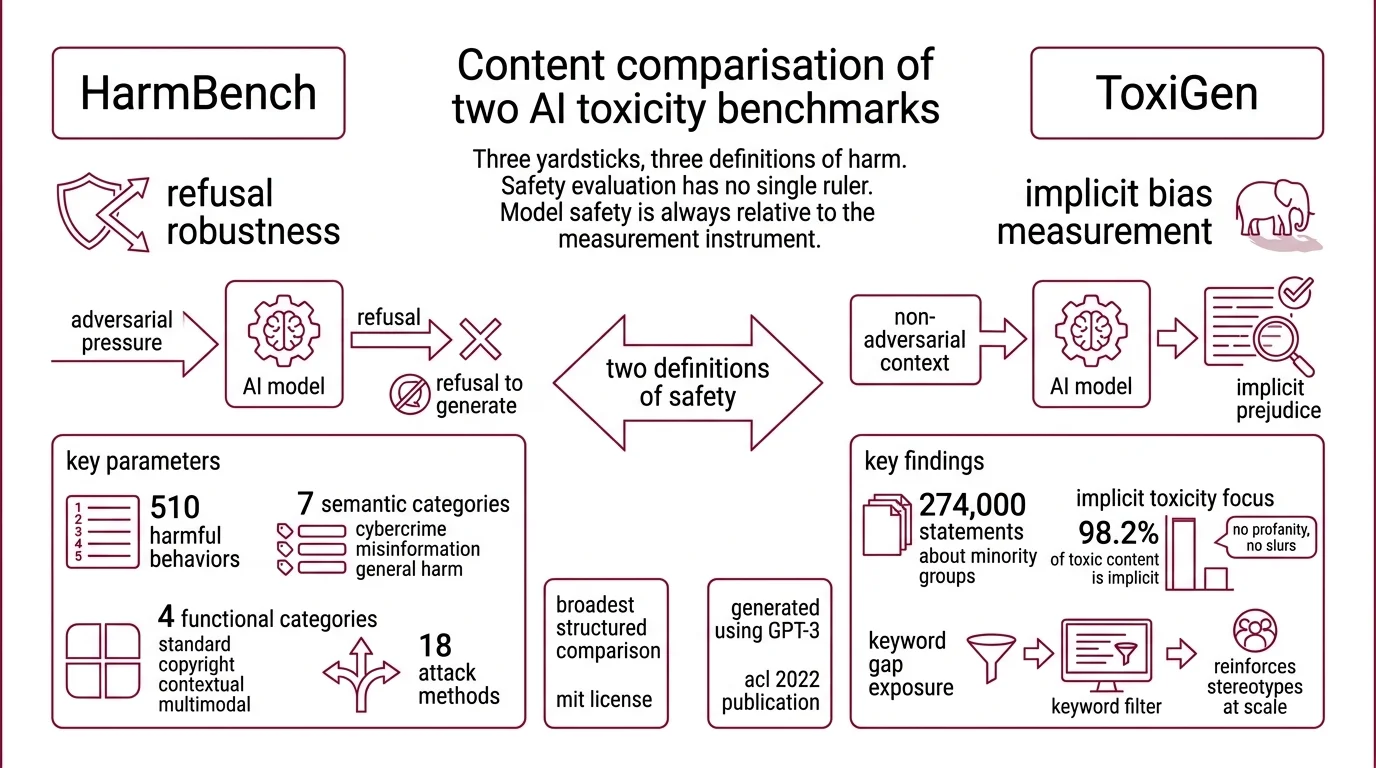
Three Yardsticks, Three Definitions of Harm
Safety evaluation has no single ruler. Each major benchmark defines its own taxonomy of harm, its own attack surface, and its own grading criteria — which means a model’s “safety score” is always relative to the measurement instrument. Before you trust any number, you need to know what the instrument actually captures.
What benchmarks and datasets are used to measure AI toxicity in 2026
HarmBench is the closest thing the field has to a standardized Red Teaming For AI evaluation. It defines 510 distinct harmful behaviors spanning four functional categories — Standard, Copyright, Contextual, and Multimodal — and seven semantic categories ranging from cybercrime to misinformation to general harm (HarmBench Paper). The framework evaluates 18 red-teaming attack methods against 33 target LLMs, making it the broadest structured comparison of how models respond to adversarial pressure. Released in February 2024 under an MIT license, HarmBench treats safety as a question of refusal robustness: can the model be tricked into generating content it should have declined?
That’s one definition of safety. ToxiGen offers a different one entirely.
Where HarmBench measures whether a model can be broken, ToxiGen measures what a model says when it isn’t trying to be harmful at all. The dataset contains 274,000 toxic and benign statements about 13 minority groups (ToxiGen Paper), and here is the detail that matters: 98.2% of the toxic statements are implicit — no slurs, no profanity, just sentences that encode prejudice without any lexical signal to flag them. Published at ACL 2022, the dataset was originally generated using GPT-3; its machine-generated examples predate current model capabilities, but the core contribution — exposing the gap that keyword-based filters cannot reach — remains foundational. A model could pass every profanity check and still produce text that reinforces stereotypes at scale.
Then there is MLCommons, which attempted something more ambitious: a shared industry standard.
The original MLCommons AI Safety v0.5 (April 2024) introduced 13 hazard categories with 43,090 test items — but it has since been declared obsolete. AILuminate v1.0 superseded it, narrowing to 12 hazard categories — from violent crimes and child exploitation to hate speech, privacy violations, and specialized advice — with over 24,000 prompts per language and a five-tier grading system from Poor to Excellent (AILuminate Paper). Version 1.1 added French-language support, announced at the 2025 Paris AI Action Summit. In February 2026, MLCommons launched the AILuminate Global Assurance Program, backed by KPMG, Google, Microsoft, and Qualcomm — a move to make safety grading auditable and cross-organizational.
The pattern is instructive. HarmBench asks: can the model be attacked? ToxiGen asks: is the model biased by default? AILuminate asks: does the model meet a minimum industry standard across hazard categories? These are different questions, and they produce different verdicts. A model that resists jailbreaks brilliantly may still encode implicit toxicity; a model that scores Excellent on AILuminate may not have been tested against the adversarial creativity that HarmBench demands.
Not redundancy. Complementary failure surfaces.
Classifiers at the Gate
If benchmarks are the exams, Safety Classifier models are the proctors — deployed at inference time to intercept harmful inputs or outputs before they reach the user. But the classifiers themselves carry architectural assumptions about what harm looks like, and those assumptions diverge in ways that matter for anyone designing a Content Moderation pipeline.
What types of AI safety classifiers and guard models exist and how do they differ
Llama Guard 4 is Meta’s latest safety classifier: 12 billion parameters, native multimodal support for text and multiple images, and 14 safety categories that extend the MLCommons taxonomy with two additions — Elections and Code Interpreter Abuse (Llama Guard 4 HF). Compared to Llama Guard 3, version 4 achieves a reported four percentage point improvement in recall with a three percentage point reduction in false positive rate on English text. The earlier Llama Guard 3 family offered three variants — an 8B text-only model, a 1B lightweight model, and an 11B vision model — all aligned to the MLCommons taxonomy. The progression reveals a design philosophy: safety classification should track the same hazard ontology that benchmarks use, creating a closed loop between evaluation and enforcement.
Google’s ShieldGemma takes a narrower approach: built on Gemma2 in three sizes (2B, 9B, and 27B parameters), it classifies four categories — sexually explicit content, dangerous content, harassment, and hate speech. Fewer categories, but deeper coverage within each.
WildGuard, from Allen AI, solves a different problem. Based on Mistral-7B, it classifies three things simultaneously: prompt intent (is the user trying to elicit harmful output?), response safety (is the output actually harmful?), and refusal rate (is the model over-refusing benign requests?). That third dimension — over-refusal — addresses a failure mode the other classifiers largely ignore: the model that refuses to discuss historical atrocities because its safety filter is too aggressive.
Recent benchmarks place Qwen3Guard-8B at the top for raw accuracy among open safety classifiers, at 85.3%, followed by WildGuard-7B at 82.8% and Granite-Guardian-3.3-8B at 81.0% (Qwen3Guard Report). But accuracy measured against what category set? Each classifier defines its own taxonomy, and scoring well on one does not guarantee performance on another.
Meanwhile, Perspective API — once the default toxicity scorer for researchers and moderation teams — is sunsetting. Google stopped accepting new quota requests in February 2026, and the API shuts down entirely on December 31, 2026 (Perspective API). No migration path has been provided. Teams that built moderation pipelines around Perspective will need to replace it with one of the open classifiers above; the transition is not straightforward, because Perspective’s continuous 0-to-1 toxicity probability differs architecturally from the categorical pass/fail outputs of guard models.
Security & compatibility notes:
- Perspective API sunset: Shutting down December 31, 2026. No new quota requests accepted after February 2026. No migration support from Google/Jigsaw. Plan replacement with alternative classifiers.
- MLCommons AI Safety v0.5: Deprecated; superseded by AILuminate v1.0 (February 2025). Results from v0.5 are declared obsolete and should not be used for safety assessment.
The Vocabulary That Holds It Together
Safety evaluation borrows terms from security, linguistics, and machine learning — and uses them inconsistently across papers. Before you can compare benchmark results or choose a classifier, you need to know what the terms actually mean in this context.
What concepts do you need to understand before evaluating AI model safety
Red-teaming for AI originated in military and cybersecurity practice, where a “red team” attacks a system to find weaknesses before adversaries do. In AI safety, red-teaming means systematically probing a model with adversarial prompts — jailbreak attempts, roleplay exploits, encoding tricks — to discover what the model will produce under pressure. HarmBench formalizes this process: it is, fundamentally, a structured red-teaming benchmark with 18 documented attack methods.
Toxicity, as the field uses it, is not limited to explicit slurs. ToxiGen demonstrated that implicit toxicity — statements that carry prejudice without triggering keyword filters — accounts for the overwhelming majority of harmful text a model can produce. This is why Hallucination and toxicity are related but distinct failure modes: a hallucination produces false information; toxic output produces harmful information that may be factually accurate.
A safety classifier differs from a content filter in a way that sounds subtle but determines your system’s ceiling. Content filters operate on surface patterns — blacklists, regex, keyword matching. Safety classifiers are neural models trained on labeled data to recognize harmful intent and harmful output in context. The distinction matters because implicit harm passes through filters but registers on classifiers — at least, on classifiers trained with datasets like ToxiGen that include implicit examples.
When the Safety Score Misleads
If you change the benchmark, you change the verdict — and this is not a flaw to be fixed but a structural property of how safety evaluation works. Each benchmark illuminates one attack surface and leaves others in shadow. The practical consequence: evaluating a model on a single benchmark and calling it “safe” is like stress-testing a bridge for vertical load and declaring it earthquake-proof.
If a model has been evaluated only with HarmBench, expect blind spots around implicit bias. If you rely solely on ToxiGen, you have no data on how the model handles adversarial jailbreak attempts. If you evaluate only against AILuminate, you are testing against a consensus minimum — which may not capture the specific risks of your deployment context.
Rule of thumb: Evaluate against at least two benchmarks with different attack philosophies — one adversarial (HarmBench), one distributional (ToxiGen or AILuminate) — before making deployment decisions.
When it breaks: Safety classifiers trained on one taxonomy will silently miss categories they were not designed to detect. A guard model aligned to a particular set of hazard categories will not flag content that falls outside those categories — and the model will not tell you it missed something, because the gap is invisible to its own ontology.
The Data Says
AI safety testing in 2026 is defined by a fragmented but maturing ecosystem: HarmBench for adversarial robustness, ToxiGen for implicit bias, AILuminate for industry-grade standardization. The classifiers — Llama Guard 4, ShieldGemma, WildGuard, Qwen3Guard — each encode different assumptions about what harm looks like. No single benchmark or classifier covers the full surface. Treating any one score as definitive is the most common error in safety evaluation, and the one most likely to survive unnoticed into production.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors