Why AI Upscalers Hallucinate Faces and Tile Seams at 4K and 8K

ELI5
AI upscalers don’t read your image — they redraw it from a learned prior. On faces, text, and logos that prior overrides identity, and tile-by-tile processing fractures the global view that would otherwise hold the picture together.
The mental model most people start with: feed a 1024px photo to an upscaler, and the model adds the missing pixels. More resolution from less data, like a forensic enhance from a TV crime drama. It feels reasonable, and it’s how the marketing copy reads. The mental model is also wrong, and the way it’s wrong explains every failure mode you’ll meet at 4K and 8K.
How an Upscaler Decides What’s “There”
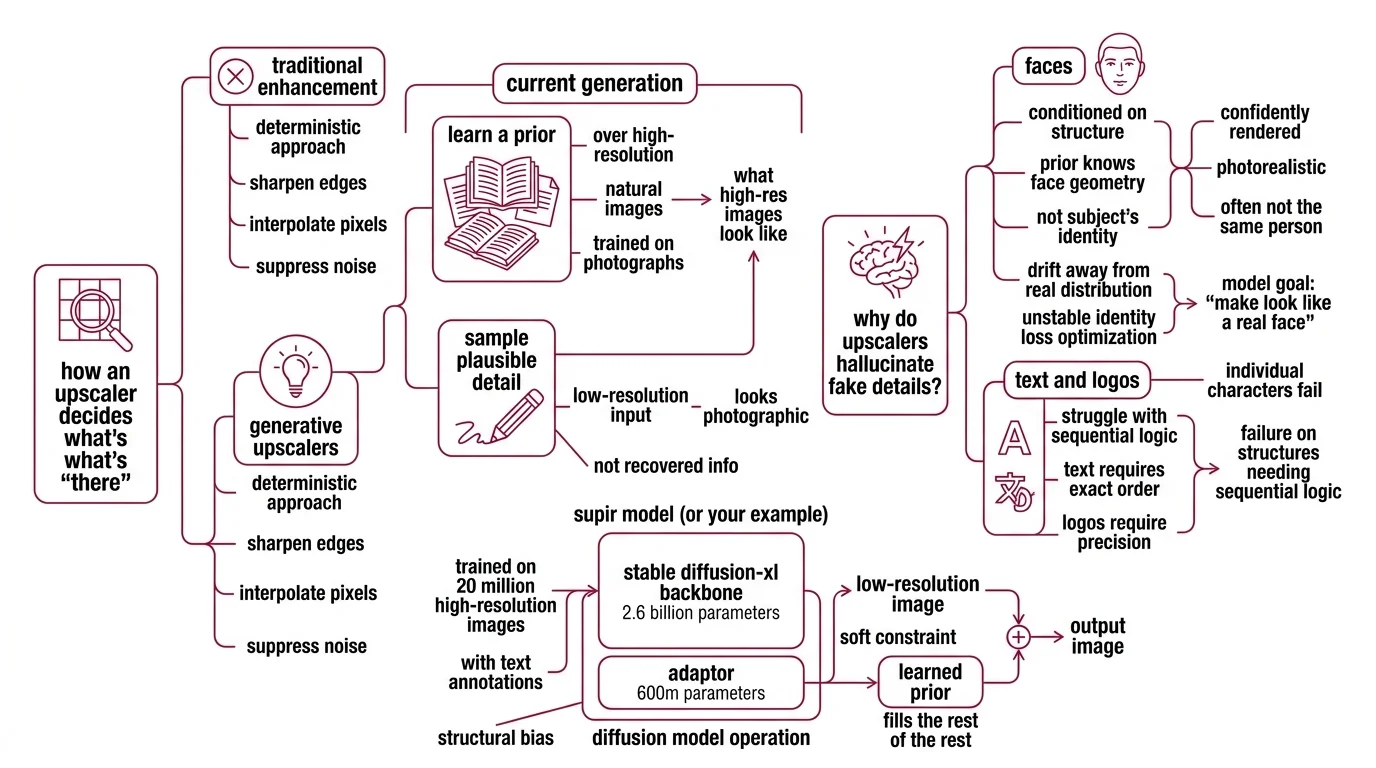
Image Upscaling began as a deterministic enhancement problem — sharpen edges, interpolate pixels, suppress noise. The current generation of generative upscalers solved the problem differently. They learned a prior over high-resolution natural images and use it to sample plausible detail given a low-resolution input. The output looks photographic because the prior was trained on photographs, not because the model recovered information that was already there.
Why do diffusion upscalers hallucinate fake details on faces, text, and logos?
A Diffusion Models-based upscaler operates in two registers at once. The low-resolution image acts as a soft constraint; the learned prior fills the rest. Supir — published at CVPR 2024 (SUPIR paper) — makes the architecture explicit: a Stable Diffusion-XL backbone with 2.6 billion parameters, plus a 600M-parameter adaptor, trained on 20 million high-resolution images with text annotations. That’s an enormous well of “what high-resolution images tend to look like.” It is also, structurally, a bias.
When the input is a face, the prior knows what faces look like — eyes, skin texture, cheek geometry, micro-shadows — but it does not know what your subject’s face looks like. It samples from the manifold of plausible faces conditioned on the low-frequency structure it can see. The result is photorealistic and confidently rendered. It is also, often, not the same person. The Edge & Identity Preserving Network paper documents the underlying issue: during training, the super-resolved image distribution drifts away from the real high-quality face distribution, and identity loss is unstable to optimize. Translation: the model has no reliable gradient that says “preserve who this is” — only “make it look like a real face.”
Text and logos fail in a different but related way. The Local Generation Bias paper shows that diffusion models render individual glyphs correctly while assembling them into nonsensical strings — a “G,” a “u,” and an “i” emerge cleanly, then combine into something that isn’t a word. Each region samples from a locally plausible distribution, but no operator enforces global word-level consistency. The model is competent at letters and incompetent at words, because letters are local features and words are global ones.
This is the recurring shape of the failure. The prior is local; identity is global.
What the Architecture Quietly Assumes
A common defense — that with a stronger model and a tighter prompt the artifacts will disappear — misses what the architecture is doing. SUPIR’s own mitigation strategy is informative. The SUPIR paper introduces negative-quality prompts and restoration-guided sampling to suppress fidelity drift. Both are guardrails on a sampling process that is, by construction, generative. They narrow the distribution; they do not eliminate it.
Some pipelines stack a LoRA for Image Generation on top of the base prior to nudge style or subject, but a LoRA is still a learned distribution — it tightens the manifold the model samples from, it doesn’t pin the model to your specific subject. ESRGAN and Real-ESRGAN, the GAN-based predecessors, suffer less from face hallucination because their priors are weaker — they sharpen edges and recover texture but rarely invent a different person — at the cost of less impressive perceived detail. The trade-off is not “good vs bad upscaler.” It is weaker prior with smaller hallucination and less perceived detail, against stronger prior with bigger hallucination and sharper output.
Magnific introduced a Precision mode in mid-2025 that explicitly capped output at 2x and tuned the sampling to suppress invented detail (MyArchitectAI). The cap is the giveaway. Faithful (non-hallucinating) outputs and aggressive (high-magnification) outputs sit at opposite ends of the same axis. Choose one.
When You Tile the Image, You Tile the Brain
VRAM is the second wall. A diffusion upscaler operating directly on a 4K or 8K canvas needs to hold the full latent representation, the U-Net activations, and the attention maps in memory simultaneously. On consumer GPUs, this is generally infeasible. The standard workaround is to split the image into tiles, upscale each tile independently, and stitch them together. The workaround is also where the second class of failures lives.
What causes tiling artifacts and seam mismatch in large image upscaling pipelines?
The Tiled Diffusion wiki names the mechanism precisely: in the U-Net VAE, global-aware operators — self-attention layers and GroupNorm in ResNet blocks — compute statistics across the entire input. When you process tiles independently, those operators see only a local subset, and their statistics drift between tiles. GroupNorm normalizes activation channels using means and variances computed over each tile’s content; two adjacent tiles with different content produce different normalization statistics, which is exactly the kind of mismatch that surfaces as a visible seam.
Two main tiling algorithms exist in the open ComfyUI stack, and the difference between them is a clean diagnostic of what’s actually happening. MultiDiffusion averages overlapping regions linearly. Mixture of Diffusers applies a Gaussian weighting kernel to the overlap, which shifts more mass to the tile center and less to the edge — and as the Tiled Diffusion wiki notes, that lets Mixture get away with less overlap before seams become visible. Both algorithms are working around the same root cause: there is no global pooling step that would unify the tiles.
Overlap is the standard mitigation. ComfyUI tiled workflows commonly use 64 pixels as a default — adjacent tiles share that many pixels, and the upscaler runs the diffusion process across the union, hoping the shared region pulls the tiles into agreement. It often does. It does not always. ComfyUI’s Ultimate SD Upscale exposes four progressively aggressive seam-fix passes — None, Band Pass, Half Tile, and Half Tile + Intersections — and the existence of four post-hoc seam-repair modes is the most honest acknowledgment that the underlying mismatch survives the first pass.
A subtle consequence: stronger denoising — pushing the diffusion process harder per tile to extract more detail — amplifies seam visibility. More denoise means more local generative freedom, which means more divergence between adjacent tiles’ interpretations of what should be there. The detail you wanted and the seam you didn’t want come from the same operator.
Why 4K and 8K Specifically
Below ~1080p, modern consumer GPUs have enough VRAM to run a generative upscaler whole-canvas; tiling is optional, and the local-prior failures stay subclinical. At 4K and especially 8K, tiling becomes effectively mandatory for any model with a non-trivial latent representation, and the local-prior failures and seam mismatches stack on top of each other. The “hard limit” framing here is not a published spec — the Local Generation Bias paper, the Edge & Identity paper, and the Tiled Diffusion wiki each describe the underlying mechanism qualitatively, and there is no single benchmark that quantifies it as a unified rate. But the mechanism is well-supported, and the practical regime where the failures become unavoidable lives at exactly the resolutions this article names.
What the Failure Surface Tells You
The mechanism is not a bug list. It is a small set of structural constraints, and each one rules out a class of fix. Run the predictions:
- If your input image contains a recognizable person and you upscale at high magnification with a strong diffusion prior, expect identity drift. The prior dominates the constraint at the resolutions where it has the most freedom to invent.
- If you tile a 4K canvas with low overlap and high denoise, expect visible seams in textured regions — fabric, foliage, hair. These are the regions where the per-tile prior has the most degrees of freedom and the GroupNorm statistics diverge most strongly between adjacent tiles.
- If you push past 4x with any unconstrained generative upscaler, expect text and logos to render as plausible-looking gibberish. There is no global word-level operator to enforce coherence.
- If you switch from a diffusion-prior upscaler to a GAN-based upscaler (ESRGAN, Real-ESRGAN), expect cleaner identity preservation and less perceived sharpness. You bought one and sold the other.
Rule of thumb: Match the prior strength to the failure cost. For a portrait where identity matters more than apparent sharpness, bias toward a weaker prior and a faithful mode. For a textured landscape where invented detail is acceptable, a stronger prior pays off.
When it breaks: No upscaler currently available eliminates both failure modes at once at 4K and 8K — the architectural choices that strengthen the prior are the same choices that worsen identity drift, and the tiling required by VRAM constraints fractures the global operators that would otherwise smooth seams. A future weights release does not patch this. A different architecture would.
Tool & licensing notes (as of early 2026):
- Topaz Gigapixel: Topaz Labs ended new perpetual-license sales in late 2025 (CG Channel); the product is now subscription-only, with Standard at $29/month or $149/year and Pro at $499/year.
- Magnific: Pro is approximately $39/month with around 500 credits and no rollover; Premium runs about $99/month, Business about $299/month (MyArchitectAI). Precision mode is the faithful (non-hallucinating) option but is capped at 2x.
- SUPIR: Open-source diffusion-prior upscaler; the architecture and mitigation strategies are public (SUPIR paper).
A Connection Worth Naming
Both failure modes — prior hallucination and tile drift — are the same problem at different scales. In each case, a local generative process is doing something that requires global coordination, and the global operator that would coordinate it has been removed. For face hallucination, the missing operator is identity preservation, which has no reliable training signal and never quite locks in. For tile seams, the missing operators are attention and GroupNorm at full-canvas scale, which get dropped to fit in VRAM.
The lesson is not that diffusion upscalers are bad tools. It is that any time a generative process must produce a coherent global object out of local samples, there must be a global coordination mechanism — or the incoherence will surface exactly where the global structure mattered. Faces have global structure. Words have global structure. Continuous textures across tile boundaries have global structure. When you remove the global operator, those are the failures you will see, in roughly that order. AI Image Editing pipelines built on the same diffusion backbone inherit the same constraint — it is a property of the family of models, not of any single tool.
The Data Says
Hallucinated faces and tile seams are not engineering bugs awaiting a patch. They are direct consequences of upscaling-as-sampling-from-a-prior, plus tile-local processing forced by VRAM, and the architectures that mitigate one tend to worsen the other. At 4K and 8K, the failure modes become unavoidable in production unless you accept a smaller magnification, a weaker prior, or a faithful mode that caps the upscale factor.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors