GPT-5 at 92.5% and MMLU-Pro's Rise: How Benchmark Saturation Is Reshaping LLM Rankings in 2026
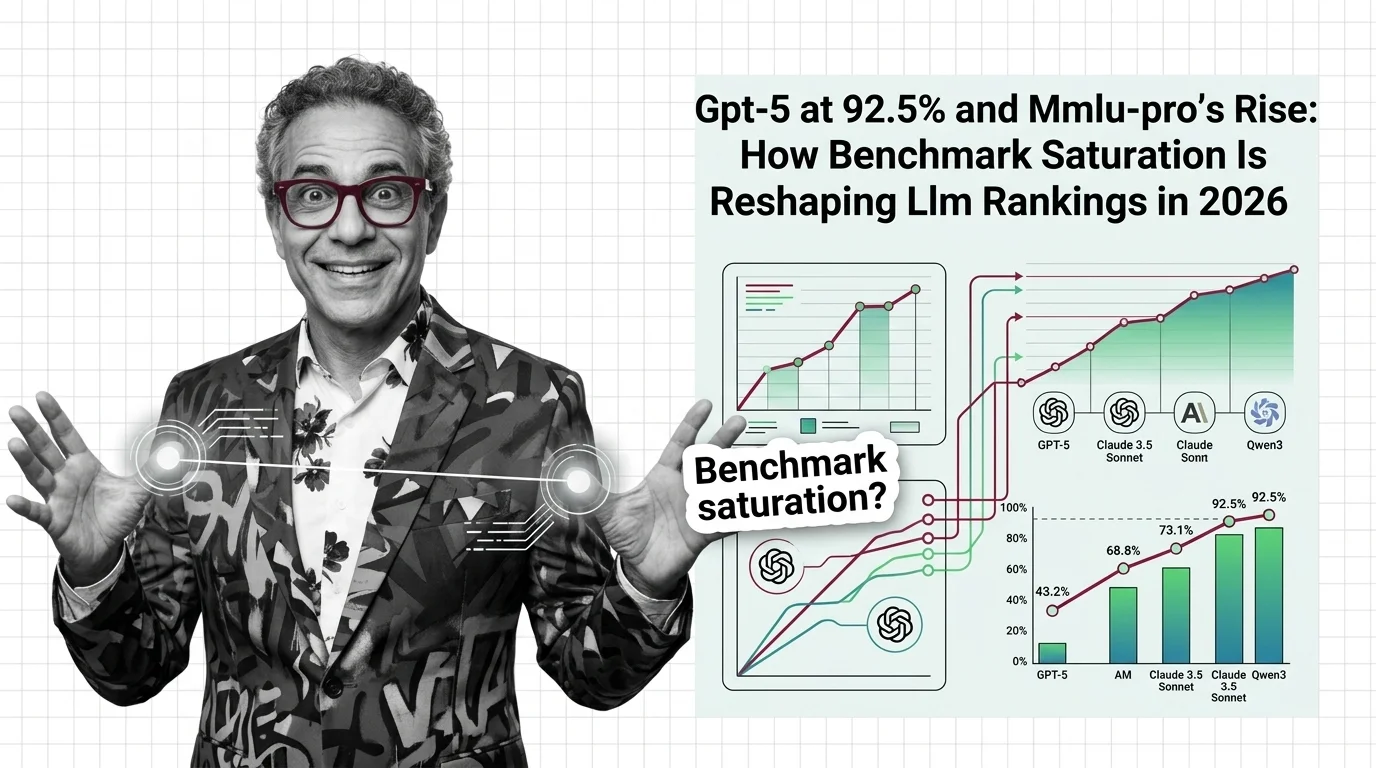
Table of Contents
TL;DR
- The shift: Frontier models cluster within 4 points on MMLU, turning the industry’s default benchmark into a ceiling metric that can’t separate leaders from the pack.
- Why it matters: The evaluation tool that defined LLM competition for five years has lost its signal — and its replacements are already showing the same symptoms.
- What’s next: The benchmark lifecycle is accelerating from discriminative tool to marketing number to deprecated metric in under two years.
GPT-5 posted a 92.5% on the MMLU Benchmark and it barely registered. Not because the score is unimpressive — it’s the highest on record. Because the gap between first and fifteenth place has collapsed to a range that tells you almost nothing about which model is actually better at the job you need done.
That’s the signal. Here’s what it means.
The Ceiling Nobody Planned For
Thesis: MMLU has completed its lifecycle as a discriminative benchmark — the scores that remain are marketing metrics, not engineering signals.
The original MMLU dataset covers 15,908 questions across 57 subjects (Wikipedia). It was built to measure broad knowledge and reasoning. It worked. For years, the spread between top-tier and mid-tier models was wide enough to mean something.
That spread is gone.
As of April 2026, the top fifteen models on the MMLU leaderboard sit between 88.8% and 92.5% (LLM Stats). A 3.7-point window separating the most capable language models on the planet.
The scores stopped being signals. They became proof-of-entry stamps.
And there’s a deeper problem. Of the 99 MMLU scores tracked on LLM Stats, 98 are self-reported and zero are independently verified. The industry’s most-cited Model Evaluation number is also its least audited.
Four Points, Fifteen Models, Zero Differentiation
GPT-5 at 92.5%. OpenAI’s o1 at 91.8%. GPT-4.5 and o1-preview share 90.8%. Qwen3 VL 235B and Sarvam-105B tie at 90.6%. Claude 3.5 Sonnet holds 90.4% at rank seven (LLM Stats).
Five architectures from four labs. All within two points.
The original MMLU carries structural flaws that erode trust further. Researchers documented an overall question error rate of approximately 6.5%, with the Virology subset reaching 57% errors (Wikipedia). When more than half the questions in a subject contain mistakes, the score measures a model’s tolerance for noisy input — not its knowledge.
Then there’s Benchmark Contamination. Estimates range from 13.8% using web detection to 72.5% using behavioral probing (Emergent Mind). The variance alone is disqualifying. A benchmark that might be one-seventh contaminated or three-quarters contaminated is one you can’t trust to rank anything.
The MMLU era is over. The leaderboard just hasn’t accepted it yet.
Who Benefits From a Broken Scoreboard
The labs building harder tests.
MMLU Pro was designed to fix this saturation problem. Over 12,000 questions across 14 domains with 10 answer choices instead of four — dropping model accuracy by 16-33% compared to original MMLU (TIGER-AI-Lab, NeurIPS 2024). The benchmark also reduced prompt sensitivity to 2% variance, down from 4-5% on the original, making Few-Shot Learning tuning less of a confound.
The MMLU-Pro leaderboard tells a different story. Qwen3.6 Plus leads at 88.5%. MiniMax M2.1 sits at 88.0%. ERNIE 5.0 holds 87.0% (LLM Stats). Chinese labs dominate the top five — a structural shift from MMLU’s OpenAI-heavy rankings that Western coverage has largely ignored.
With 202 models evaluated and an average score of 74.4, MMLU-Pro still has room to separate the field.
Teams measuring real-world task performance — using Confusion Matrix analysis, domain-specific accuracy splits, and Precision, Recall, and F1 Score breakdowns — also win. They get engineering data instead of a marketing number.
Stuck on the Old Metric
Anyone still using MMLU as a primary model selection criterion for production.
Artificial Analysis removed MMLU-Pro from its Intelligence Index v4.0 in January 2026, citing saturation (VentureBeat). If the evaluation authority tracking over two hundred models decides a benchmark no longer differentiates, that’s a verdict on the entire measurement framework.
Gemini 3 Pro Preview already hit 90.1% on MMLU-Pro (VentureBeat). The successor benchmark is approaching the same ceiling.
Organizations that built procurement processes around MMLU thresholds — “we need a model above 85%” — now select from a pool where every serious contender qualifies. The filter filters nothing.
You’re either building evaluation frameworks that measure what matters for your use case, or you’re picking models based on a number that stopped meaning anything.
What Happens Next
Base case (most likely): MMLU becomes a checkbox metric — required for launch marketing, ignored in technical evaluations. MMLU-Pro follows the same trajectory within twelve to eighteen months as frontier models push past 90%. Signal to watch: A second major evaluation platform drops MMLU-Pro from its index. Timeline: By mid-2027.
Bull case: The saturation crisis forces the industry toward task-specific, independently audited benchmarks that measure real deployment performance. Signal: A major cloud provider announces model selection based on domain-specific evaluations instead of aggregate scores. Timeline: Late 2026 to early 2027.
Bear case: Benchmark cycling continues — new tests saturate, get replaced, saturate again — and model selection stays vibes-based for most organizations. Signal: MMLU-Pro’s replacement is announced before MMLU-Pro itself is widely adopted. Timeline: 2027.
Frequently Asked Questions
Q: Which AI models have the highest MMLU scores in 2026? A: As of April 2026, GPT-5 leads at 92.5%, followed by o1 at 91.8%, GPT-4.5 and o1-preview tied at 90.8%, and Qwen3 VL 235B at 90.6%. All scores are self-reported (LLM Stats).
Q: How do GPT-5, Claude 3.5 Sonnet, and Qwen3 compare on MMLU benchmark? A: GPT-5 tops at 92.5%, Qwen3 VL 235B sits at 90.6% at rank five, and Claude 3.5 Sonnet holds 90.4% at rank seven. The two-point spread between them makes meaningful differentiation difficult.
Q: What benchmarks are replacing MMLU as the standard LLM evaluation in 2026? A: MMLU-Pro leads the replacement wave with harder questions and ten answer choices instead of four. GPQA Diamond and domain-specific evaluations are gaining traction. Artificial Analysis now favors real-world task tests.
Q: How is MMLU-Pro changing the way frontier AI models are ranked and compared? A: MMLU-Pro drops model accuracy by 16-33% versus MMLU, restoring differentiation. It also reveals a different competitive map — Chinese labs like Alibaba and Baidu dominate the top five, reshaping the power structure.
The Bottom Line
MMLU stopped being a ranking tool and became a qualification stamp. The models keep improving — the measurement just can’t see it anymore. Build your evaluation stack around what your deployment actually needs, or spend the next year selecting models based on a number that means less every quarter.
Disclaimer
This article discusses financial topics for educational purposes only. It does not constitute financial advice. Consult a qualified financial advisor before making investment decisions.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors