Glitch Tokens, Fertility Gaps, and the Unsolved Technical Limits of Subword Tokenization

Table of Contents
ELI5
Subword tokenizers split text into pieces for language models, but the splitting algorithm creates dead vocabulary entries, punishes non-English languages with longer sequences, and breaks on simple typos.
Ask a large language model to repeat the string " SolidGoldMagikarp" and watch it spiral. The model might refuse, hallucinate, or produce output that looks like a seizure in text form. The token exists in the vocabulary. The model trained on it. And yet something went wrong between the merge table and the embedding layer — not a model failure, but a tokenizer failure that has been hiding in plain sight since 2016.
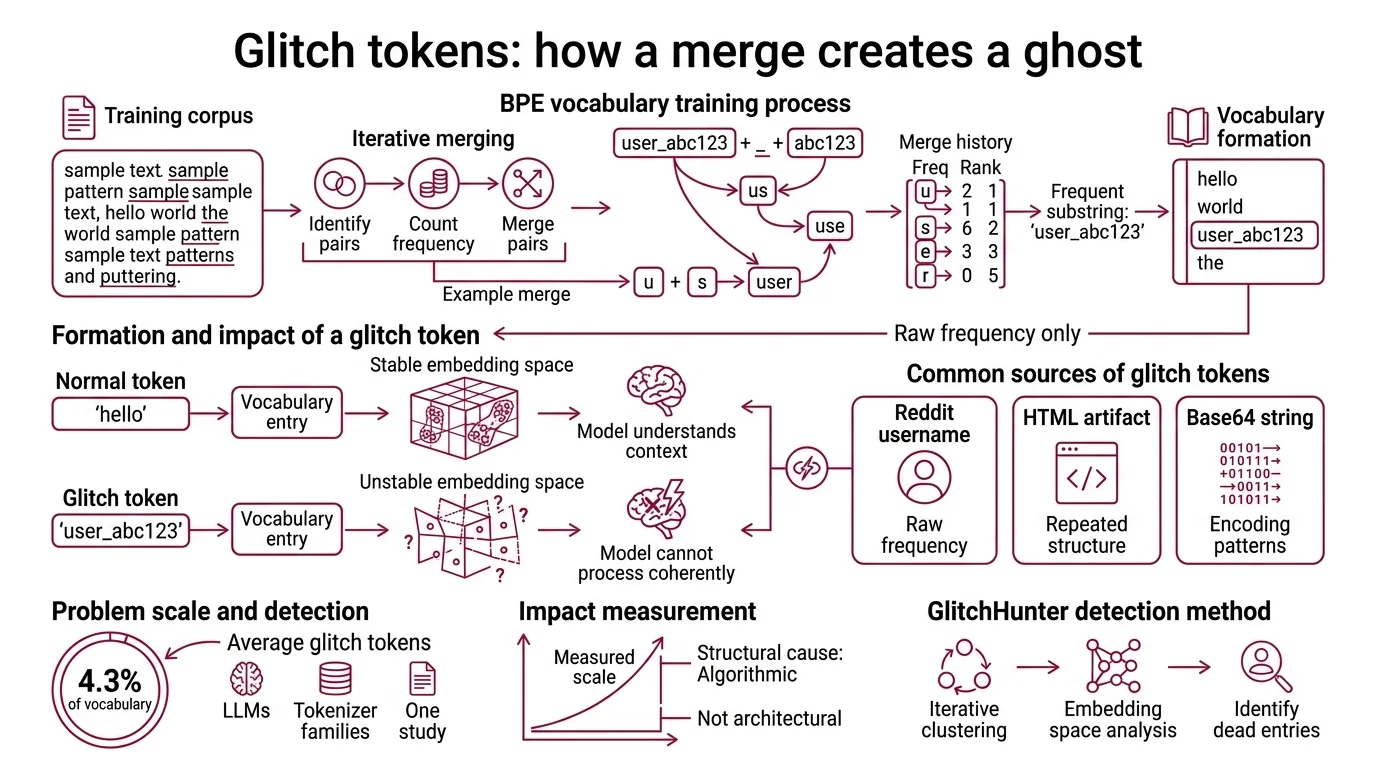
The Merge That Created a Ghost
Tokenization sounds like a solved problem. Take text, split it into pieces, feed the pieces to a model. The dominant algorithm — Byte Pair Encoding, introduced for neural machine translation by Sennrich, Haddow, and Birch in 2016 — works by iteratively merging the most frequent adjacent byte pairs in a training corpus until the vocabulary reaches a target size. Wordpiece and Unigram Tokenization follow related but distinct merge strategies, yet all three share a structural assumption: the training corpus is representative enough to produce a useful vocabulary.
That assumption creates ghosts.
What are glitch tokens and how do they form during BPE vocabulary training?
A Glitch Tokens is a vocabulary entry that earned its place through raw frequency during merge training but maps to a region of embedding space the model never learned to handle. The mechanism is straightforward: BPE merges are greedy and frequency-driven. If a substring appears often enough in the training data — a Reddit username, a repeated HTML artifact, a Base64-encoded string — it gets merged into the vocabulary as a standalone token. The model then encounters this token during training, but the contexts are sparse, contradictory, or nonsensical. The embedding never converges to a stable representation.
The result: a token the model cannot process coherently.
Systematic measurement puts the scale of this problem into perspective. Across seven large language models using three different tokenizer families, roughly 4.3% of vocabulary entries exhibited glitch behavior (Li et al.). That percentage comes from one study’s specific model set and will likely shift with newer architectures — but the structural cause is algorithmic, not architectural. GlitchHunter, the detection method developed in that study, identifies these dead entries through iterative clustering in embedding space; tokens that cluster far from semantically coherent neighbors get flagged.
The implication is uncomfortable. Every vocabulary file in production contains entries that exist only because a frequency heuristic promoted them — and no downstream filter removed them. The glitch token is not a rare curiosity. It is a predictable artifact of greedy merge statistics applied to messy corpora.
Seven Tokens Where One Would Do
The glitch token problem affects individual vocabulary entries. Fertility disparity affects entire languages.
Fertility — the number of tokens a tokenizer produces per word — determines how much of the Attention Mechanism a language consumes. In a Transformer Architecture, attention cost scales quadratically with sequence length. When a sentence in Myanmar requires 357.2 tokens while the same semantic content in Latin script requires 50.2 tokens, the asymmetry is not a rounding error; it is a 7x difference (Teklehaymanot & Nejdl).
What causes token fertility disparity between English and non-Latin scripts in current tokenizers?
The cause is corpus bias compounded by byte-level encoding. BPE builds its merge table from the statistical distribution of the training data, which overwhelmingly favors English and Latin-script languages. Characters in those scripts occupy single bytes in UTF-8; characters in scripts like Tibetan, Myanmar, or Devanagari require three or four bytes each. BPE starts from bytes, so a single logographic or abugida character enters the merge process as three or four separate units — and if those byte sequences appear too rarely in the corpus, they never merge into efficient tokens.
The numbers are precise: Latin scripts average 2.61 characters per token; Tibetan averages 0.49 characters per token — a 5.3x compression gap (Teklehaymanot & Nejdl). Hindi has the lowest Single Token Retention Rate across evaluated tokenizers, meaning Hindi words are almost never preserved as single vocabulary entries.
This is not merely an efficiency problem. Each additional token per word reduces downstream accuracy by 8-18 percentage points, and fertility explains a substantial share of accuracy variance across languages — between 20% and 50%, depending on the task (Lundin et al.). The model is not worse at Hindi because Hindi is harder. The model is worse at Hindi because the tokenizer fragmented it.
The cost follows from the quadratic attention relationship. Doubling fertility quadruples training cost. One extrapolation — assuming linear data scaling — estimates training a model comparable to Llama-3.1-405B at roughly $420M for a 2x-fertility language versus $105M for English (Lundin et al.). The absolute dollar figures are estimates with significant assumptions baked in; the structural relationship is mathematical.
Pre-Tokenization and the Boundaries That Won’t Bend
Before BPE even begins its merge iterations, a pre-tokenization step splits raw text along whitespace and punctuation boundaries. This step is nearly invisible — and nearly immovable.
What are the technical limitations of BPE and subword tokenizers in 2026?
The deepest limitation is pre-tokenization lock-in. Over 90% of words in a typical corpus are frozen as single tokens by the pre-tokenization boundary before BPE’s merge statistics can redistribute them (Schmidt et al.). The merge algorithm operates within these fixed boundaries; it cannot merge across a space or a punctuation mark. The vocabulary ends up dominated by high-frequency complete words that were never candidates for subword decomposition, while rare and cross-boundary patterns are permanently excluded.
The consequence: vocabulary shape is locked before merges begin.
Three additional failure modes compound the problem.
The first is robustness fragility. BPE-tokenized models exhibit what researchers call the “curse of tokenization” — acute sensitivity to typos, character-level perturbations, and length variations that alter token boundaries. A single inserted character can shift the entire merge chain, producing a completely different token sequence for semantically identical input. BPE-dropout, which randomly skips merges during training, partially mitigates this; it does not eliminate it.
The second is the vocabulary ceiling. Fixed-vocabulary tokenizers must commit to a vocabulary size before training. Too small, and fertility explodes for low-resource languages. Too large, and the embedding matrix consumes memory that could be spent on model capacity. There is no correct answer — only trade-offs frozen at vocabulary creation time and carried through the entire model lifecycle.
The third is architectural coupling. Every Decoder Only Architecture and Encoder Decoder Architecture in production today depends on its Tokenizer Architecture as a fixed preprocessing step. Changing the tokenizer means retraining the model. The tokenizer is not a configuration parameter; it is a load-bearing wall.
Where the Cracks Point
If fertility determines both cost and accuracy, and pre-tokenization locks in vocabulary distribution before training begins, then fixing tokenization requires breaking one or both of those constraints.
Two recent approaches attack the problem from opposite ends. BoundlessBPE introduces “supermerges” that cross pre-tokenization boundaries, achieving a 21% Renyi efficiency gain and 19.7% more bytes per token (Schmidt et al.). It keeps the BPE framework but removes the boundary constraint. The Byte Latent Transformer takes the other path entirely — it eliminates the fixed vocabulary, operating directly on bytes and grouping them into dynamic patches based on local entropy (Pagnoni et al.). At 8B parameters and 4T training bytes, BLT matches Llama 3 performance; whether that parity holds at production scale remains unverified.
The production tokenizer ecosystem is adjusting incrementally. OpenAI’s tiktoken moved from cl100k_base to o200k_base for GPT-4o, and introduced o200k Harmony in August 2025 with 201,088 tokens for GPT-5 — though the extent of its multilingual improvements is not publicly documented. SentencePiece continues as the backbone for Gemma and Llama families. HuggingFace’s Rust-based tokenizer library supports BPE, WordPiece, and Unigram; developers should note that Trainer.tokenizer is deprecated in favor of Trainer.processing_class as of HuggingFace Transformers v4.46.1+.
Rule of thumb: If your application serves non-Latin-script languages, measure fertility before choosing a tokenizer. A 2x fertility gap is a 4x cost gap — and an accuracy penalty that no amount of fine-tuning will fully recover.
When it breaks: Tokenizers fail silently. The model still produces output; it just produces worse output for languages the vocabulary was never built to handle. The failure mode is not a crash — it is a systematic accuracy degradation that looks, to the end user, like the model simply being “bad at” their language.
The Data Says
Subword tokenization is a load-bearing compromise built in 2016 and still carrying the weight of every major language model in production. Its failure modes — ghost vocabulary entries, systematic multilingual penalties, pre-tokenization lock-in, and robustness fragility — are structural features of the algorithm, not edge cases. The fixes are emerging; none have displaced the incumbent at scale.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors