Geometric Transforms, Mixup, and Back-Translation: How Core Augmentation Methods Work

ELI5
Data augmentation expands a training set by transforming copies of existing examples — flipping images, blending pairs, or round-tripping text through another language. The goal isn’t more data. It’s teaching the model which changes shouldn’t change its answer.
Take a clean, well-labeled image dataset and train a classifier on it. Now make distorted copies of every picture — rotate them a few degrees, flip them left to right, shift the crop — and train on those too. You have added no new photographs, no new labels, nothing the model couldn’t already infer from what it had. Accuracy on unseen images goes up anyway. That should bother you, because by every information-theoretic intuition, you got something for nothing.
The Data You Already Have
Myth: Augmentation works because it hands the model more data to learn from.
Reality: It adds almost no new information. What it adds is a set of constraints — an explicit statement about which transformations should leave the label untouched. A flipped cat is still a cat. By showing the model the flipped version with the same label, you are not enriching the dataset; you are narrowing the space of functions the model is allowed to learn down to those that ignore left-right orientation.
Symptom in the wild: A team augments aggressively, sees validation accuracy climb, then deploys to a setting where the augmentations didn’t match reality — and watches the model fail on exactly the variations it was never told to expect.
That reframing is the whole game. Data Augmentation is not a data factory. It is a way of encoding your prior knowledge about a task directly into the training signal. Once you see it that way, the three method families below stop looking like unrelated tricks and start looking like the same idea pointed at different kinds of data.
Why a Flipped Cat Is Still a Cat
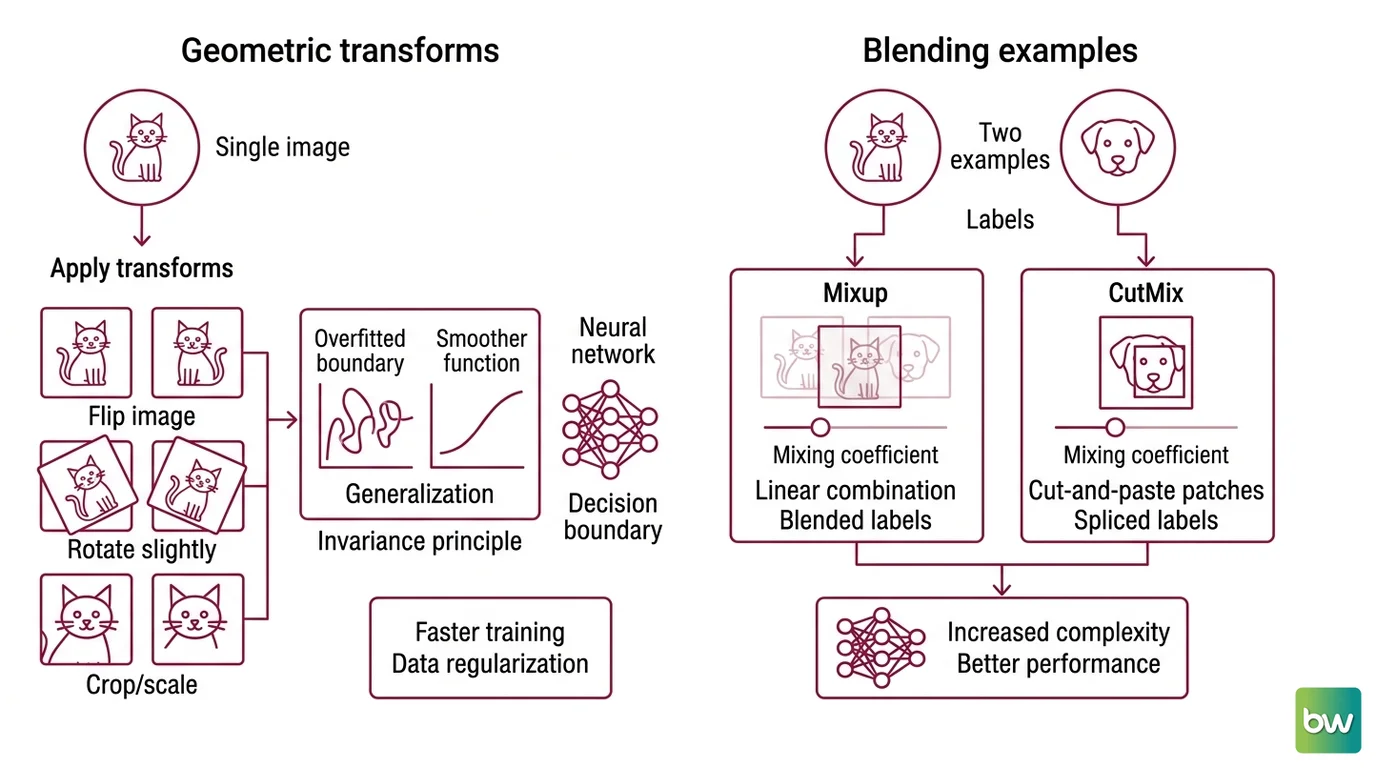
The oldest and most reliable augmentations are geometric. Flip, rotate, crop, scale, translate, shear — label-preserving spatial operations that form the standard baseline for image augmentation, as documented in the Albumentations Docs. Each one is a statement of invariance: a cat photographed slightly rotated is no less a cat, so the decision boundary should not move when the pixels rotate.
Here is the mechanism underneath the convenience. A neural network with enough capacity can memorize its training set exactly — it can carve a wildly contorted decision boundary that threads between every individual example. That is Overfitting, and it generalizes badly because the boundary encodes accidents of the specific images rather than the structure of the class. When you add geometrically transformed copies, you force the boundary to give the same answer across all of them. The contortions that fit one orientation but not its mirror image become impossible. The result is a smoother function — a form of Regularization that you implemented through the data rather than through a penalty term in the loss.
Not new pictures. New invariances.
The Albumentations library and its successor made these transforms fast enough to apply on the fly during training, which is why they became the default first move in computer vision. But the principle is older than any library: tell the model what it is allowed to ignore.
Mixing Two Truths Into One
Geometric transforms operate on a single example. The next family asks a stranger question — what happens if you blend two examples together, labels and all?
How do mixup and CutMix augmentation techniques work?
Mixup, introduced by Zhang et al. in “mixup: Beyond Empirical Risk Minimization” (mixup paper, 2017), trains the model on convex combinations of pairs of examples and their labels. Take two images, pick a mixing coefficient λ drawn from a Beta(α, α) distribution, and produce a new input that is λ of the first image plus (1−λ) of the second — pixel by pixel. Crucially, the label is mixed by the same λ: a 70/30 pixel blend gets a 70/30 soft label across the two classes. The model is no longer told “this is unambiguously a cat.” It is told “this is 70% cat, 30% dog,” and forced to behave linearly in the space between classes. That linear interpolation is what smooths the decision boundary and discourages the overconfident, jagged predictions that drive overfitting.
CutMix, from Yun et al. (CutMix paper, ICCV 2019), shares the goal but uses a different mechanism — and conflating the two is a common mistake. Instead of blending every pixel, CutMix cuts a rectangular patch from one image and pastes it onto another. The label is then mixed in proportion to the patch area, not by a per-pixel blend. If the pasted patch covers a third of the canvas, the label is a third the patch’s class. Because real local features survive intact rather than being washed into a ghostly average, CutMix preserves the kind of localizable detail an object detector cares about.
One trick, two geometries: mixup blends globally, CutMix swaps regionally. Both teach the model that class membership lives on a continuum, but they disagree about whether to smear the evidence or relocate it.
Translating a Sentence in a Circle
Images have an obvious notion of “the same thing, slightly changed.” Text does not. You cannot flip a sentence. So augmentation for language needed a different route to the same destination.
What is back-translation for text data augmentation?
Back Translation comes from Sennrich, Haddow, and Birch’s work on improving neural machine translation with monolingual data (Sennrich et al., ACL 2016). The original problem was scarcity: parallel sentence pairs for training a translator are expensive, but monolingual text in the target language is abundant. Their move was to translate target-language text backward into the source language using an existing model, then pair that synthetic source sentence with the real target sentence. You have manufactured a training pair out of data that was previously unusable.
The same machinery doubles as a general paraphrase generator. Round-trip a sentence into another language and back, and you usually get a sentence with the same meaning but a different surface form — different word choices, reordered clauses, altered phrasing. That is the textual analog of flipping an image: the label (the meaning, the sentiment, the intent) is preserved while the incidental form changes. The slight imperfections the translation model introduces are not a bug — they act as noise that regularizes the downstream model, exactly as a few degrees of rotation does for vision.
Audio takes yet another path. SpecAugment, from Park et al. (SpecAugment paper, Interspeech 2019), does not perturb the raw waveform at all. It operates on the log-mel spectrogram — the time-frequency image of the sound — applying time warping, frequency masking, and time masking. By masking out bands of the signal, it prevents the model from leaning on any single acoustic feature. Different modality, identical lesson: hide part of the evidence so the model learns the robust structure instead of a shortcut.
What You Need to Know First
Augmentation looks like a one-line call to a library. The decisions it hides are not one-line decisions.
What concepts should you understand before applying data augmentation?
Start with label preservation, because it is the assumption every transform rests on. A horizontal flip leaves a cat a cat — but it turns a “b” into a “d” and mirrors a road sign into nonsense. The transform is only valid if the invariance is true for your task, and that is a judgment no library can make for you.
Understand overfitting and regularization first, because augmentation is a regularizer — if you don’t know what it is fighting, you can’t tell whether it’s helping or just adding noise. Understand Class Imbalance, because augmentation is often reached for to rebalance a skewed dataset, and over-augmenting a tiny minority class amplifies whatever Label Noise it already contains. And understand Training Data Quality and Data Deduplication, because augmenting dirty data multiplies the dirt — every mislabeled example becomes ten mislabeled examples wearing slightly different clothes.
It also helps to know where augmentation sits among the other data-centric moves. It is the cheap option compared to Data Labeling And Annotation or active learning, which buy genuinely new information at genuine cost. Augmentation buys robustness, not knowledge. Knowing which one your problem actually needs is the difference between a fix and a placebo.
The tooling spans modalities. The Nlpaug library covers text perturbations, and AugLy offers augmentations across four modalities — audio, image, text, and video — with over a hundred transforms in a single package (AugLy GitHub). Their maintenance status, however, is not uniform.
Library maintenance notes:
- Albumentations: The original repository is no longer actively maintained (last update June 2025). Development has moved to AlbumentationsX, a dual-licensed successor still under active release (AlbumentationsX GitHub). Pin and verify before relying on the legacy package.
- nlpaug: Maintenance status is inactive — still widely cited in the literature, but no longer actively developed (nlpaug GitHub). Confirm it works against your current stack before building a pipeline on it.
- AugLy: Actively maintained by Meta, with no breaking changes identified at the time of writing.
What the Augmented Geometry Predicts
Because augmentation encodes invariances, you can predict in advance when it will pay off and when it won’t.
- If your test distribution contains variations your training set lacked — rotations, crops, paraphrases — then augmenting with those exact transforms should close the gap. If the test set never varies that way, the augmentation buys you nothing.
- If you mixup across classes that sit far apart in feature space, expect better-calibrated, less overconfident predictions. If the classes already overlap heavily, expect the blended labels to mush the boundary into something worse.
- If you back-translate through a weak intermediate model, expect the synthetic noise to cross from helpful regularization into outright label corruption.
Rule of thumb: Only augment with transforms whose invariance is actually true for your task — never because the library makes them easy.
When it breaks: Augmentation fails silently when a transform changes the correct label but you keep the old one. A flipped road sign, a mirrored character, or an over-blended mixup pair straddling a decision boundary all inject label noise that the model faithfully and confidently learns — and because validation accuracy can still look fine, the damage hides until deployment.
The Data Says
Core augmentation methods don’t add information; they add constraints, encoding which changes should leave a label intact. Geometric transforms, mixup, CutMix, back-translation, and SpecAugment are one principle aimed at four kinds of data. Their power is exactly as good as the invariance assumption behind them — which is why the hard part was never the library call, but knowing which transform tells the truth about your task.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors