From Vision Transformers to Modality Gaps: Prerequisites and Technical Limits of Multimodal AI in 2026
ELI5
Multimodal architectures bolt vision, audio, and language into one model. The math joining them is unsettled — images and text often live in different regions of latent space, and visual grounding decays mid-sentence.
A frontier Multimodal Architecture can caption a photograph with startling precision, then — two sentences later — describe a dog that isn’t in the frame. The text side of the model knows what dogs look like. The vision side fed it a park, a bench, and a jogger. The failure is not in what the model knows. It is in how the two sides of the model learned to agree, and where that agreement breaks.
The Questions Hiding Inside “Multimodal”
Before the modality gap has a meaning, a reader needs a working map of what “multimodal” actually refers to — and of the transformer pieces that make the bolt-together possible at all. Every failure mode in the later sections is a consequence of choices made at this layer. Skip it, and the geometry reads like a ghost story.
What do you need to understand before learning about multimodal architectures?
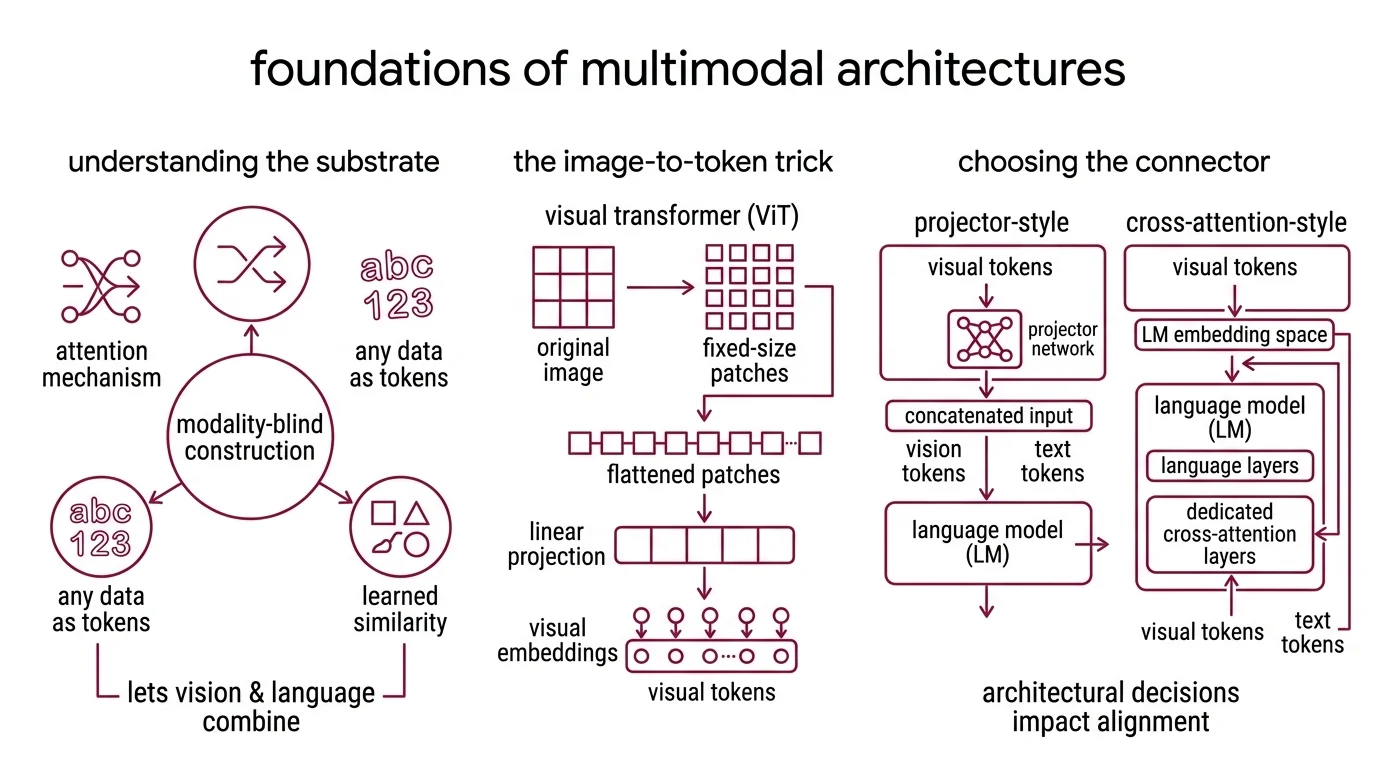
First, the substrate. Modern multimodal models inherit the transformer’s attention mechanism: tokens that attend to each other within a context window, weighted by learned similarity. That premise — that anything can become a token — is what lets a vision stack be welded onto a language stack at all. Attention is modality-blind by construction, which is the feature that makes the entire idea tractable and, later, the reason alignment failures are so hard to diagnose.
Second, the image-to-token trick. Images can be cut into fixed-size patches, flattened, projected into an embedding dimension, and fed into a transformer as if they were words — the move that turned vision into a sequence problem (Dosovitskiy et al., ICLR 2021). The Vision Transformer has no convolutional inductive bias; it learns spatial structure from position embeddings and attention alone. For multimodal purposes, the key consequence is output shape: a sequence of visual tokens that look, to a downstream language model, interchangeable with text tokens in dimensionality — and entirely foreign in geometry.
Third, the connector decision. A multimodal system has to get visual tokens into a language model. Two patterns dominate open-weight recipes: projector-style (a small network maps vision tokens into the LM’s embedding space and concatenates them with text tokens) and cross-attention-style (dedicated attention layers inside the LM query the visual features through a separate pathway). Raschka’s architectural breakdown remains the cleanest summary of the split. A third pattern — native multimodal pre-training, where the model is trained from scratch on mixed modalities — is reserved for frontier labs with the data and compute budget to pull it off. Which pattern you pick determines which failure mode you inherit.
Fourth, the context problem that lurks behind all of this. Transformer attention scales quadratically with sequence length, and images — especially high-resolution ones — inflate token counts fast. This is why the broader architectural conversation for long-sequence multimodal work reaches past the dense transformer. State Space Model variants promise linear-time sequence processing; Mixture Of Experts routing promises capacity without a proportional compute cost. Neither has fully displaced dense transformers in 2026 multimodal production stacks, but both shape the design space — especially for long video and audio, where dense attention is already the first thing to break.
These four layers — attention, patch tokenization, connector pattern, and sequence architecture — are the real prerequisites. Everything that breaks below, breaks because of a decision made here.
Before alignment matters, architecture decides what can align.
The Geometry That Won’t Align
Once images are tokens, the question becomes whether the model’s representation of “dog” learned from pixels lives in the same place as its representation of “dog” learned from the word. For a large class of multimodal models, the answer is: no, and not by a little.
What are the modality gap and cross-modal alignment problems in multimodal models?
Start with CLIP. A dual-encoder model was trained on 400M image-text pairs by pushing matched pairs together and unmatched pairs apart in a shared embedding space (Radford et al., OpenAI). The assumption was that enough contrastive pressure would collapse the two modalities into the same geometric region.
It did not.
Liang et al. (NeurIPS 2022) dissected the resulting embedding geometry and found that image embeddings and text embeddings occupy two narrow, nearly-parallel cones — separated by a measurable distance, with very little overlap. The paper traces the separation to two causes that compound each other: random weight initialization produces the cone effect, meaning embeddings start tightly clustered around a single direction per modality; and contrastive loss, moderated by a temperature parameter, is not strong enough to collapse that separation during training. The gap persists through training. It is not a transient artifact of under-fitting.
Not a bug. An artifact of the loss.
The consequence matters for downstream behavior. Zero-shot classification depends on comparing an image embedding to text embeddings of candidate class labels; if the geometries are systematically offset, the similarity scores carry a constant bias that interacts with class frequency and label phrasing. Liang et al. also showed the gap carries implications for fairness — demographic groups that cluster differently in image space than in text space inherit asymmetric representation quality, which propagates into any downstream classifier built on the embeddings.
There is a boundary worth naming, because the literature is careless with it. The modality gap, as studied by Liang et al. and subsequent work, is a property of contrastive dual-encoder models — CLIP, the SigLIP family, and their descendants. Decoder-based vision-language models like Flamingo-style cross-attention VLMs and LLaVA-style projector VLMs do not live in the same geometric regime; they fail differently. Saying “multimodal models have a modality gap” as a universal claim is the kind of overgeneralization that costs an engineer three weeks of debugging. The more accurate version: contrastive alignment produces a specific geometric artifact that other architectures avoid — and trade for their own failure modes.
The gap is geometric, not semantic.
When the Model Names What It Cannot See
Projector-style multimodal LLMs — the dominant open-weight recipe in 2026 — sidestep the contrastive-cone problem by concatenating visual tokens directly into the language stream. They trade that geometry for a different failure: the model stops looking at the image partway through its own answer.
Why do multimodal models struggle to ground text to images, audio, and video?
Bai et al. (MLLM hallucination survey) catalogs what goes wrong. The failure decomposes into three categories: object hallucination (naming objects that are not in the image), attribute hallucination (assigning the wrong color, texture, count, or material), and relation hallucination (describing spatial or causal relationships that do not hold). All three are pervasive in current open multimodal models, including ones built on modern vision encoders like SigLIP 2 and DINOv2 paired with strong language backbones.
The proposed mechanism is mechanically concrete, which is why it is worth taking seriously. Most projector-style MLLMs pull visual tokens from a single late layer of a frozen vision encoder — typically the penultimate block — and hand them to the language model once, at the start of the sequence. After that, the model generates text autoregressively. Each new token attends to the full context, including the visual tokens, but attention weights are learned from training data where the dominant statistical signal is linguistic coherence, not visual faithfulness. As the output grows, the effective contribution of the visual tokens decays. Language priors take over. The model finishes the sentence it has been trained to write, not the sentence the image warrants.
This is why hallucinations tend to appear later in long descriptions, not at the beginning. The first clause of a caption often describes what is actually in the frame. The third and fourth clauses start confabulating plausible but absent objects with full confidence. Evaluation benchmarks that test only short captions underestimate the problem systematically — a point Bai et al. make repeatedly.
The cross-attention connector pattern — Flamingo’s approach, gated attention blocks that let every decoder layer query the visual features directly — keeps vision in the loop more aggressively across the output sequence. It is architecturally better at sustained grounding and architecturally worse at data efficiency. The open-weight community bet on projectors anyway, because projectors are cheaper to train and easier to retrofit onto new language backbones as they arrive. The trade is paid in grounding reliability. Cross-attention is not forgotten, but it is no longer the dominant open-source recipe in 2026.
Native multimodal training — reportedly the route taken by frontier Gemini variants, processing image, audio, and video through a single long-context attention mechanism — side-steps this particular decay pattern by learning the fusion behavior end-to-end rather than retrofitting it. Whether the grounding decay is eliminated or merely shifted downstream is not settled in the published literature. The trade-off still appears in long-output evaluations.
Grounding decays across the answer, not at the start.
What the Geometry Predicts
Three if/then heuristics fall out of the mechanism — not as absolutes, but as the shape of what an engineering team should expect when these architectures break.
- If your pipeline rides on a contrastive dual encoder (CLIP, the SigLIP family, their variants), expect the modality gap to bias zero-shot outputs — especially across demographic categories, low-frequency labels, and any category where the visual and textual distributions diverge. The fix is not more training data; it is adding a calibration layer, or moving to a decoder-based VLM for the downstream task.
- If you are using a projector-style MLLM, expect grounding reliability to decay with output length. Short captions will look fine. Long-form descriptions and multi-turn visual Q&A will fabricate confidently. Design your evaluation set to match the output length you actually run in production, not the caption length the benchmark used.
- If your workflow requires cross-modal reasoning over video or long audio, the dense-attention approach inherits the quadratic cost of the transformer. This is the regime where state-space and mixture-of-experts alternatives become practically interesting — not as replacements for dense attention, but as offsets for the sequence length that strains it.
Rule of thumb: The question “does this model ground to the image?” is rarely yes or no. The useful version is “how well, for how long, and under what output format?” Design evaluations that measure the curve, not just the first sentence.
When it breaks: Single-late-layer visual tokens plus long autoregressive output is the canonical failure pattern. Language priors outweigh the visual evidence, model confidence stays high, and hallucinated objects enter the output indistinguishable in surface form from real ones. No decoding trick has fully closed this gap for projector-style models in open-weight 2026 production stacks.
The Data Says
“Multimodal” is a scope word, not an architecture. The field contains contrastive dual encoders with a geometric modality gap, projector-based MLLMs with grounding decay, cross-attention VLMs with data-efficiency limits, and native multimodal frontier models whose failure modes are not yet fully characterized. Reasoning about limits starts with picking which family is on the workbench.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors