From TF-IDF to Learned Sparse: Prerequisites and Hard Limits of BM25, SPLADE, and ELSER
Table of Contents
ELI5
Sparse retrieval scores documents by matching tokens, not concepts. BM25 weights raw words. SPLADE and ELSER let a transformer expand which words count. All three obey the same physics: posting lists and vocabulary mismatch.
BM25 was published in 1994. SPLADE-v3 dropped in March 2024. On paper, three decades of NLP progress should have buried the older algorithm. Yet on out-of-domain benchmarks, BM25 still beats most dense neural retrievers — and even SPLADE wins by a margin that depends entirely on what kind of corpus you feed it. The interesting question is not which method wins. It is which physical constraint each one accepts.
What You Need Before You Touch a Sparse Retriever
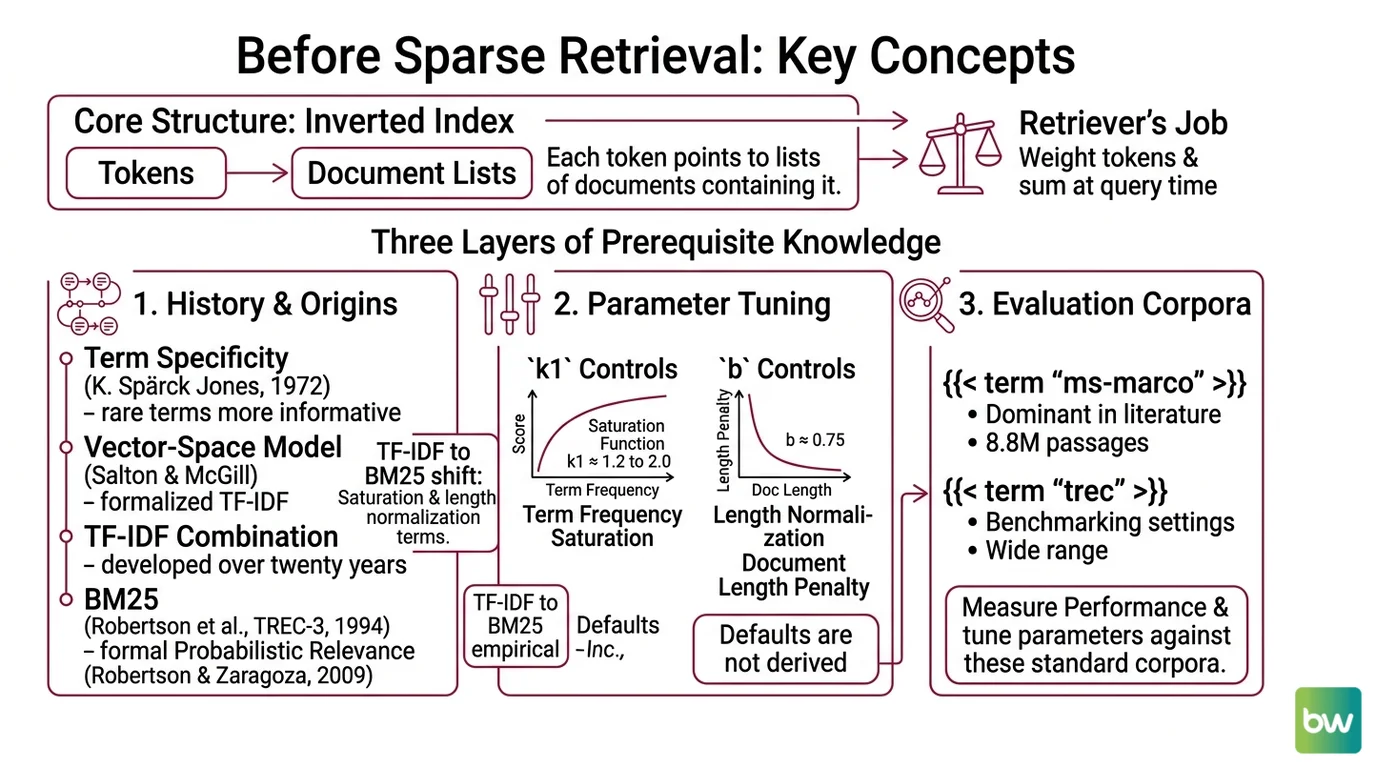
Every sparse retriever, classical or neural, lives inside the same data structure: an inverted index. Tokens point to lists of documents that contain them. The retriever’s only job is to assign weights to those tokens and sum them at query time. If you understand that one sentence, the rest of the field is a series of design decisions about which weights.
What do you need to know before learning sparse retrieval methods?
Three layers, in order — history, parameters, evaluation.
The first layer is where the weights came from. Karen Spärck Jones introduced “term specificity” in 1972, the idea that rare terms carry more information than common ones. Salton and McGill later formalized this as TF-IDF inside the vector-space model.
TF-IDF is not a single 1972 invention — it is a combination that took twenty years to settle. BM25 came in 1994 from Robertson, Walker, and the Okapi system at TREC-3, then was formalized as the probabilistic relevance framework by Robertson and Zaragoza in 2009. The shift from TF-IDF to BM25 was not better embeddings. It was a saturation function on term frequency and a length normalization term — k1 ≈ 1.2 to 2.0 for saturation, b ≈ 0.75 for length, per Stanford IR Book.
The second layer is what those parameters do. k1 controls how quickly extra repetitions of a term stop helping. With k1 = 0, every match scores the same regardless of frequency. As k1 grows, the score keeps climbing but with diminishing returns — a hyperbolic curve, not a line. b controls how harshly long documents are penalized for length. At b = 0, length is ignored. At b = 1, scores are fully normalized by document length. The defaults are empirical, not derived — they happen to work across a wide range of TREC and MS MARCO settings.
The third layer is what you evaluate against. Two corpora dominate the literature: MS MARCO, with about 8.8 million passages from Bing-derived web documents and roughly one million anonymized real queries, and BEIR, a zero-shot benchmark of eighteen IR datasets across nine task types, with query lengths from three to 192 words and corpora ranging from 3,600 to 15 million documents. MS MARCO is the supervised training distribution. BEIR measures what happens when you take the model out of that distribution. The two tell different stories about the same models, and conflating them is the most common mistake in sparse-retrieval blog posts.
For tooling, Pyserini is the bridge between papers and replication. Castorini’s v2.0.0 release on April 19, 2026 supports BM25, uniCOIL, SPLADE / SPLADEv2, DeepImpact, and SLIM on top of Anserini and Lucene 9 (Pyserini GitHub). If you cannot run a paper’s numbers in Pyserini, you do not yet have a baseline.
What “Learned Sparse” Actually Learns
The conceptual leap from BM25 to Sparse Retrieval models like SPLADE and ELSER is not “neural networks read meaning.” It is a much narrower claim: a transformer can predict, at index time, which tokens should have been in a document but were not.
How SPLADE turns BERT into a sparse encoder
SPLADE — Sparse Lexical and Expansion Model for First Stage Ranking, originally proposed by Formal, Piwowarski, and Clinchant at SIGIR 2021 — uses a BERT masked language modeling head to score every token in BERT’s WordPiece vocabulary against a document, then a FLOPS regularizer to push most of those scores to zero (Pinecone Learn). What survives is a sparse, weighted bag of tokens over roughly thirty thousand dimensions. Some of those tokens appeared in the original document. Others did not — the model adds them because the masked-LM head expects them to belong there. That is the expansion mechanism.
The latest checkpoint, SPLADE-v3 from Lassance, Déjean, and colleagues in March 2024, reports more than 40 MRR@10 on the MS MARCO development set and roughly two percent improvement over SPLADE++ on BEIR (arXiv).
Not magic. A 30,000-dimensional sparse projection of a transformer’s beliefs about token presence.
How ELSER differs
ELSER is Elastic’s production-oriented learned-sparse encoder. The architecture is similar in spirit to SPLADE — sparse vector with weighted token expansions over a fixed vocabulary, stored in Elasticsearch’s sparse_vector or rank_features field types. The differences are operational, not theoretical. ELSER v2 is generally available; v1 is still labeled technical preview. The optimized v2 model ingests around twenty-six documents per second on the minimum 4 GB ML node; the cross-platform v2 ingests around sixteen, and v1 around fourteen (Elastic Docs). It is English-only — non-English content needs the multilingual E5 model, or, since Elasticsearch 9.3, Jina v5 via Elastic Inference Service.
The line between SPLADE and ELSER is not “research vs production.” It is licensing and language scope. SPLADE’s reference repository (naver/splade) is released under CC-BY-NC-SA 4.0, which means its weights cannot be deployed commercially without a separate license. ELSER ships under the Elastic license inside the search engine you are presumably already paying for.
Where Each Method Snaps
The reason no sparse retriever has retired the others is that each one fails differently. BM25 fails on vocabulary. SPLADE fails on cost and license. ELSER fails on language and lock-in.
What are the technical limitations of BM25 and learned sparse retrievers?
BM25 fails at vocabulary mismatch. BM25 matches strings, not concepts. If a query says “heart attack” and the document says “myocardial infarction,” BM25 sees no overlap. The Qdrant Article calls this the “vocabulary mismatch problem,” and it is structural, not tunable. You cannot fix it with k1 or b. You can only fix it by adding synonym lists, query expansion, or by switching to a model that learned synonyms during training.
SPLADE fails at latency and license. Learned sparse retrievers are slower than BM25 at both ends of the pipeline. At index time, every document must run through a transformer encoder; at query time, the expanded posting lists are longer, which means more list traversals during scoring. The Two-Step SPLADE paper from Lassance and colleagues exists precisely because this latency was treated as a research problem worth a paper. Static pruning, guided traversal, and two-step scoring all reduce the cost — but none eliminate it. On top of that, the reference SPLADE weights are non-commercial. A team that built a prototype on naver/splade cannot release it commercially without switching to a derivative encoder.
ELSER fails at language scope. ELSER does not handle non-English content. If your corpus is multilingual, ELSER alone will under-retrieve in every language except English. Elastic’s own recommendation is to switch to the E5 multilingual encoder, or to the newer Jina v5 path in Elasticsearch 9.3+. Treating ELSER as “Elastic’s general-purpose semantic search” is a misreading of the documentation.
The shared limit cuts across all three. BEIR is a zero-shot benchmark. It tells you how a retriever behaves on corpora it never saw. SPLADE wins zero-shot on average; on in-domain MS MARCO, dense retrievers and learned sparse models are usually competitive or stronger than BM25 (BEIR paper, arXiv). The framing “sparse beats dense” is overstated. Per-task and per-corpus picture is what determines what wins in practice.
Compatibility & licensing notes:
- SPLADE weights — CC-BY-NC-SA 4.0: naver/splade is non-commercial. For production, use derivative open-licensed encoders (e.g., naver/efficient-splade-VI-BT-large-doc) or engine-provided alternatives (Qdrant miniCOIL, Elastic ELSER).
- SPLADE repo maintenance: last release October 2023, last code activity November 2023 (naver/splade GitHub). Treat as a research codebase, not a maintained library.
- ELSER v1 — technical preview: v2 is the supported choice for new deployments; v1 tutorials are stale.
What This Means for Your Index
The mechanism predicts a few things you can use without re-running benchmarks.
- If your corpus is in-domain, narrow, and your queries match document vocabulary closely, BM25 with default
k1andbwill be a brutally hard baseline to beat. Most “we replaced BM25 with embeddings” projects regress here and never publish the result. - If your queries paraphrase heavily and your latency budget allows for a transformer pass at index time, learned sparse will recover the synonyms that BM25 misses — but you pay for it on every retrieval.
- If your content is multilingual and you reach for ELSER, expect English documents to dominate your top-k and other languages to under-retrieve until you switch encoders.
- If you change
k1from default toward zero, expect rare-term matches to dominate; toward higher values, expect frequent-term matches to climb. The curve is not linear.
Rule of thumb: Use BM25 as your floor, log a RAG Evaluation run with both BM25 and a learned sparse model on your real query distribution, and only adopt the learned model where it wins on metrics you measured — not metrics from someone else’s corpus.
When it breaks: Learned sparse retrievers fail when latency budgets are tight, the corpus is multilingual, or the license forbids the use case — and BM25 fails when your users paraphrase faster than your synonym lists can keep up.
The Data Says
BM25 is the strongest sparse baseline because its parameters describe two physical phenomena — term saturation and document length — that no amount of pretraining can erase. SPLADE and ELSER win on metrics that reward synonym recovery and lose on metrics that reward speed and licensing flexibility. Picking the right sparse retriever is picking which failure mode you can absorb.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors