From Static Batching to PagedAttention: Prerequisites and Hard Limits of Continuous Batching
Table of Contents
ELI5
Continuous batching lets an LLM server swap finished requests out and new ones in after every single token generation step, instead of forcing the GPU to wait until the slowest sequence in the batch is done.
Run an LLM on a high-end GPU. Watch the utilization graph. For a card that costs tens of thousands of dollars, it spends a remarkable fraction of its time doing nothing — not because the arithmetic units are slow, but because the scheduling policy told them to wait. The bottleneck during Inference is rarely what people assume.
Not compute. Coordination.
Three Eras of Request Scheduling
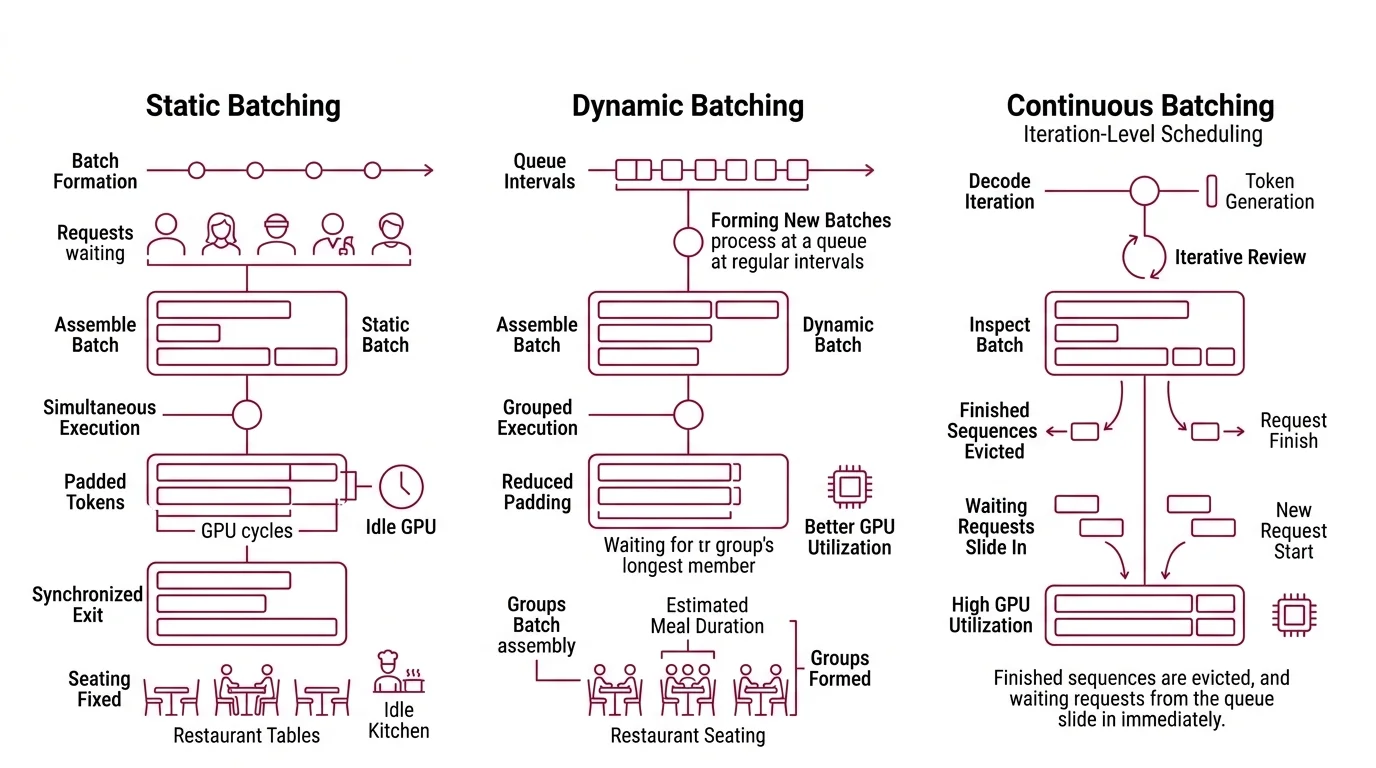
The original sin of LLM serving is a scheduling decision made before the first token is generated. Static Batching groups incoming requests into a fixed batch, runs them together, and refuses to release any request until every sequence in the batch has finished. A request that needs 20 tokens waits for the one that needs 512 — and the GPU cycles allocated to the shorter request sit unused for the entire duration.
The waste is structural, not accidental. Understanding why requires looking at how each scheduling strategy treats the relationship between a request’s lifetime and the batch’s lifetime.
What is the difference between static batching, dynamic batching, and continuous batching?
In static batching, the batch is sealed at formation time. Every request enters together and exits together. The GPU processes pad tokens for every completed sequence still waiting for its neighbors to finish, which drags GPU Utilization well below capacity. Think of a restaurant that refuses to seat anyone until every table from the last seating has paid the bill. The kitchen is idle. The customers are waiting. The only thing moving is the clock.
Dynamic batching improves on this by forming new batches from a queue at regular intervals — but the fundamental unit of scheduling remains the full request. The batch still waits for its longest member; it just assembles smarter groups of similar-length requests when the queue allows it. The restaurant now groups parties by estimated meal duration. Better, but still rigid.
Continuous Batching — introduced as “iteration-level scheduling” by Yu et al. in the Orca system (OSDI 2022) — breaks the batch open at the level of individual decode steps. After every single token generation iteration, the scheduler inspects the batch: finished sequences are evicted, and waiting requests from the queue slide in immediately. The batch composition changes on every forward pass.
The throughput difference is not subtle. Orca demonstrated 2-36x gains over static batching, with typical improvements of 3-8x for conversational workloads (USENIX). Under conditions with high output-length variance — where some requests generate far more tokens than others — the gains are larger, because static batching wastes the most cycles on padding.
A widely cited figure is 23x throughput over naive static batching, but that measurement comes from a specific setup: OPT-13B on an A100-40 GB with maximum output-length variance (Anyscale Blog). Workloads with more uniform sequence lengths produce gains closer to the 3-8x range. The gap between peak and typical matters for anyone sizing infrastructure.
The Memory Problem That PagedAttention Solved
Iteration-level scheduling solves the when of request management — when to admit and evict. But it exposes a deeper problem: where to store the memory each active request accumulates.
Every active sequence in a transformer-based model maintains a KV Cache — the stored key and value tensors from previous attention computations. This cache grows with each generated token and can consume gigabytes of GPU memory across a large batch. Under traditional contiguous allocation, the system reserves a maximum-length memory block for each sequence at admission time, regardless of how many tokens that sequence will actually produce.
The result is geometrically predictable: 60-80% of allocated KV cache memory is wasted through internal fragmentation and over-reservation (Introl Blog).
How do GPU memory management and KV cache size affect continuous batching performance?
The connection between memory management and throughput is mechanical. The number of sequences a server can batch simultaneously is bounded by available KV cache memory. If each sequence pre-reserves memory for its maximum possible length, fewer sequences fit in the batch. Fewer sequences in the batch means lower throughput — regardless of how intelligent the scheduler is.
PagedAttention, proposed by Kwon et al. (SOSP 2023), borrows a concept from operating-system virtual memory. Instead of allocating a single contiguous block per sequence, it divides KV cache memory into fixed-size blocks — analogous to memory pages — and assigns them to sequences on demand, one block at a time. A sequence that has generated 50 tokens occupies only the blocks those 50 tokens require, not the blocks reserved for a 2048-token maximum.
The analogy to virtual memory is structural, not decorative. Just as an OS maps virtual pages to physical frames through a page table, PagedAttention maps logical KV cache positions to physical GPU memory blocks through a block table. Sequences don’t need contiguous memory. Blocks scatter across GPU DRAM, and the block table handles the indirection transparently.
Waste drops from 60-80% to under 4% — limited to the last partially filled block of each sequence (Anyscale Blog). That recovered memory translates directly into higher batch sizes, which translates directly into higher throughput.
But block size introduces its own engineering tradeoff. Smaller blocks reduce last-block waste but increase the size of the block table and add kernel indirection overhead on every attention computation. Larger blocks improve memory locality and reduce table size but waste more space in partially filled final blocks. The optimal block size depends on the distribution of sequence lengths in the workload — there is no universal constant.
The Ceilings of Iteration-Level Scheduling
Continuous batching with PagedAttention solved memory waste and scheduling rigidity. It did not eliminate bottlenecks — it relocated them. The new ceilings are subtler and more dependent on workload characteristics.
What are the memory fragmentation, scheduling overhead, and tail latency limits of continuous batching?
Memory fragmentation changes shape rather than disappearing. PagedAttention eliminates inter-sequence fragmentation — the wasted space between contiguously allocated sequences — but internal fragmentation persists within the last block of every active sequence. At high concurrency with short sequences, the cumulative proportion of last-block waste can become non-trivial. And the block table itself consumes memory; a cost that scales with active sequences times blocks per sequence.
Scheduling overhead grows non-linearly with queue depth. The scheduler evaluates every active sequence at every decode iteration to decide evictions and admissions. One characterization study found that doubling the number of enqueued requests produced at least a 2x increase in scheduling overhead, driven by the cost of managing evictions during batch formation (INRIA, IPDPS 2025). For servers processing thousands of concurrent requests, the scheduler itself can become the constraint.
Tail latency is where the tradeoffs become most visible. In vLLM’s architecture, P99 per-token decode latency runs approximately 3.8x worse than the P50 median — and preemption accounts for roughly 70% of requests experiencing that P99-level degradation (vLLM Blog). The mechanism is direct: the same aggressive eviction-and-readmission cycle that enables high throughput creates latency spikes for evicted sequences, which lose their cached KV states and must recompute them or swap them back from CPU memory.
Head-of-line blocking compounds the problem. Without chunked prefill — a technique that splits long prompt processing into smaller chunks interleaved with decode steps — a single long prompt can monopolize an entire engine step, stalling decode progress for every other request in the batch. Aggregate throughput metrics look healthy while individual requests experience unpredictable stalls.
What the Mechanism Predicts
If your workload has high output-length variance — a mix of short completions and long generations — continuous batching delivers its largest throughput gains, because static batching wastes the most cycles on padding in exactly that scenario. If your workload is uniform, the gains compress toward the lower end of the 3-8x range, and the operational complexity of continuous batching may outweigh the throughput improvement.
If you push batch size upward to maximize throughput, expect tail latency to degrade. The P99/P50 ratio worsens because more sequences compete for the same KV cache memory, triggering more preemption events. This is the designed tradeoff — throughput and tail latency pull in opposite directions under a fixed memory budget.
If you serve latency-sensitive applications, chunked prefill is not optional. Without it, a single long-context prompt creates a latency spike for every concurrent request sharing that engine step.
Quantization interacts with these limits directly. Reducing KV cache precision — from FP16 to FP8 or INT4 — shrinks per-token memory requirements, allowing larger batches within the same GPU memory budget. But quantization buys memory headroom; it does not change the scheduling dynamics or the tail-latency tradeoff.
Temperature And Sampling settings influence output-length distributions. Higher temperature with nucleus sampling tends to produce more variable output lengths, shifting the workload profile toward the scenario where continuous batching provides its largest advantage.
Rule of thumb: Monitor P99 decode latency alongside throughput. When the P99-to-P50 ratio climbs well above 3x, preemption is likely dominating your tail — reduce maximum batch size or enable preemption-aware scheduling policies.
When it breaks: Continuous batching degrades when the scheduler’s per-iteration evaluation cost exceeds the time saved by efficient slot recycling — a failure mode that emerges at extreme concurrency with thousands of short-lived requests, where eviction thrashing turns the scheduler into the primary bottleneck rather than the solution.
Compatibility notes:
- vLLM v0.18.0 (March 2026): Removed BitBlas quantization and Marlin 24 backends; deprecated
reasoning_contentfield andVLLM_ALL2ALL_BACKENDenv var. Verify backend compatibility before upgrading.
The Data Says
Continuous batching is a scheduling architecture that trades simplicity for efficiency at the iteration level. PagedAttention solved the memory allocation problem that made it practical — reducing KV cache waste from 60-80% to under 4%. The remaining limits — scheduling overhead that scales non-linearly with queue depth, tail-latency degradation under preemption, and head-of-line blocking without chunked prefill — are the engineering walls that determine whether the theoretical gains translate to a specific workload.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors