From RRDB Blocks to Diffusion Priors: Inside Modern AI Upscalers
ELI5
An AI upscaler does not enlarge pixels — it hallucinates plausible detail using a learned prior. ESRGAN-class models use stacked dense blocks; SUPIR-class models repurpose a full diffusion model.
A 480-pixel-wide screenshot lands on a 4K canvas with crisp eyelashes, individual fabric threads, and a brick wall whose mortar lines were never in the source file. The new pixels did not come from the input. They came from a prior — a compressed memory of millions of high-resolution images, accessed through a network whose internal architecture decides what “plausible detail” looks like. Image Upscaling is not magnification. It is constrained synthesis, and the constraints live in the architecture.
Inside the GAN-Era Upscaler: RRDBs, Discriminators, and Synthetic Degradation
The GAN lineage that dominated super-resolution for half a decade is built from a small number of well-defined parts. Once you can name them, the entire ESRGAN → Real-ESRGAN family stops looking like a black box and starts looking like a few engineering choices stacked on top of each other.
What are the components of an ESRGAN and Real-ESRGAN architecture?
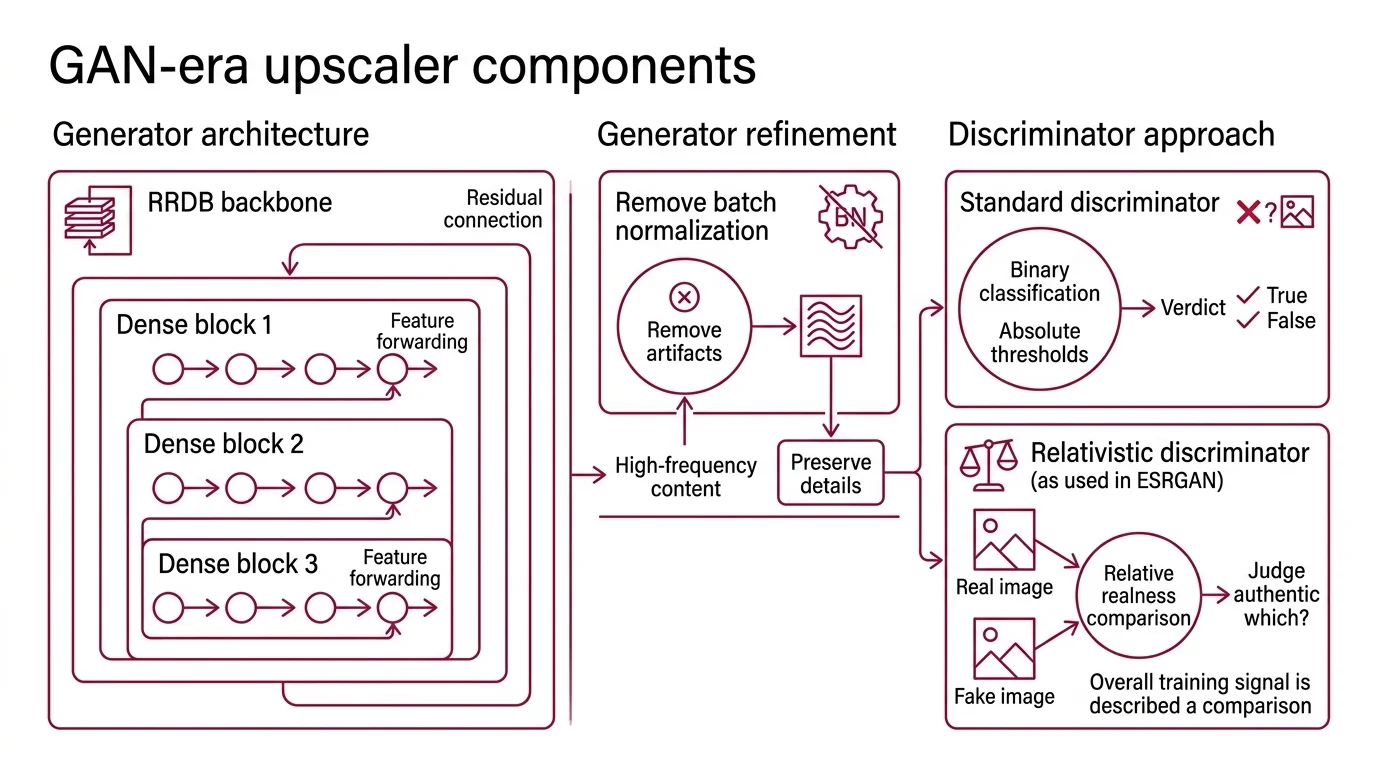
The original ESRGAN introduced one structural unit that almost every later open-source upscaler still inherits: the Residual-in-Residual Dense Block, or RRDB (ESRGAN paper). Wang and colleagues stacked these blocks deep to form the generator backbone. Each RRDB nests three dense blocks inside a residual connection, and each dense block in turn passes intermediate features forward to every subsequent layer inside the same block. The point of the nesting is depth without the gradient pathology that ordinary deep networks suffer.
One detail matters more than its modesty suggests: ESRGAN deliberately removes batch normalization from the generator. The original SRGAN included it; the ESRGAN authors observed that it produced unwanted artifacts and stripped it out (ESRGAN paper). The lesson encoded in that decision is that normalization layers, helpful for classification, can leak high-frequency artifacts into a generator whose entire job is producing high-frequency content.
The discriminator is the second half of the architecture and it is where ESRGAN broke from earlier super-resolution GANs. Instead of asking “is this image real?” — a binary classification with absolute thresholds — the relativistic discriminator predicts “relative realness instead of the absolute value” (ESRGAN paper). It compares a real and a fake sample and judges which one is more authentic. The training signal becomes a comparison, not a verdict, and the gradients the generator receives are correspondingly richer.
ESRGAN’s successor, Real-ESRGAN, kept the generator backbone unchanged. The same stack of RRDBs, the same absence of batch norm. What changed was the data the network learned from. The Real-ESRGAN paper replaces simple bicubic downsampling with what the authors call “high-order degradation modeling” — a multi-step pipeline of blur, noise, JPEG compression, and resizing applied repeatedly to clean training images (Real-ESRGAN paper). The generator never sees pristine pairs; it sees the kinds of degradation a real photograph from the internet actually carries.
That single change — a synthetic degradation model that resembles the wild — is the reason Real-ESRGAN works on phone screenshots, scanned documents, and anime frames where ESRGAN visibly fails. The architecture stayed the same; the training distribution caught up to reality. As of April 2026, Real-ESRGAN is stable at v0.3.0, with portable NCNN/Vulkan binaries shipping for Windows, Linux, and macOS (Real-ESRGAN GitHub).
The third component, less visible but operationally critical, is the perceptual loss. Pixel-wise mean squared error produces blurred outputs because it averages over plausible details; the perceptual loss compares deep VGG features instead, rewarding outputs that look right rather than ones that match each pixel. The combination — adversarial loss plus perceptual loss plus a small pixel reconstruction term — is what gives the GAN family its characteristic crispness without the visible texture noise of pure pixel-loss models.
When the Prior Becomes the Architecture: The Diffusion Upscaler Family
The diffusion upscalers do not extend the GAN lineage. They sit on top of a different machine entirely — a pretrained generative model whose statistical knowledge of the visual world is borrowed wholesale, then steered toward restoration.
How do diffusion-based upscalers like SUPIR and Magnific differ structurally from GAN upscalers?
The structural difference is foundational. A GAN upscaler is a from-scratch architecture trained on degraded/clean pairs. A diffusion upscaler hijacks a foundation Diffusion Models model — typically Stable Diffusion XL — and reformulates super-resolution as a conditional sampling problem.
Supir is the cleanest illustration. Yu and colleagues built SUPIR on top of SDXL, which carries roughly 2.6 billion parameters trained as a general image generator (SUPIR paper). SUPIR adds a custom adaptor — a connector network with more than 600 million parameters of its own — that injects information about the degraded input into SDXL’s denoising loop. The base diffusion model is doing what it always does: starting from noise and gradually constructing an image. The adaptor’s job is making sure the constructed image stays anchored to the low-resolution input rather than drifting into pure imagination.
A second component, absent from earlier GAN-family upscalers, is a multimodal language model. SUPIR uses LLaVA v1.5 13B to caption the degraded input image, then feeds those text prompts into the diffusion process (SUPIR’s GitHub repository). The architecture is multimodal in a literal sense — the upscaler reads the image, describes it in language, and uses that description as additional conditioning. The training corpus matches the ambition: 20 million high-resolution images with text annotations (SUPIR paper).
Sampling itself is the EDM scheme with restoration-guided modifications, defaulting to fifty denoising steps (SUPIR’s GitHub repository). Compared to a GAN upscaler that produces output in a single forward pass, an iterative diffusion sampler pays a much heavier inference cost per image. The compute cost is the price of the prior. And the SUPIR repository ships under a non-commercial license, with commercial use requiring written permission — a structural constraint, not just a legal note (SUPIR’s GitHub repository).
Magnific occupies a similar architectural space but is a closed product. Public information indicates it is built on diffusion-family models, framed as a generative upscaler rather than an interpolation tool (Magnific Docs). What is observable from the user surface — a Creativity slider that controls how much new detail the model invents, an HDR slider for tonal expansion, and a Resemblance slider that anchors output to input — exposes the same trade-off SUPIR exposes through code: how strongly does the prior dominate the input? Magnific was acquired by Freepik in May 2024 (Magnific’s pricing page).
The diffusion family also reorganizes how scale is achieved. Where Real-ESRGAN can upscale a full image in one pass on a consumer GPU, diffusion-based upscalers typically rely on Tiled Upscaling to fit within VRAM. The Ultimate SD Upscale node for ComfyUI is the canonical implementation: it slices the image into overlapping tiles, runs SD img2img on each, and stitches the results with seam masking (Ultimate SD Upscale GitHub). Tiling is what lets a 512×512 latent diffusion process produce 2K-plus output on commodity hardware. It also means the architecture for inference is no longer “one network, one pass” — it is a tiled scheduler wrapped around the underlying diffusion model.
The Prerequisites: What You Have to Understand Before the Architectures Make Sense
Reading either family’s paper without the right substrate produces the illusion of comprehension and almost no transferable knowledge. The prerequisites are not optional reading — they are the vocabulary in which the architectures are written.
What do you need to understand about CNNs and diffusion models before learning AI upscaling?
Three layers of prior knowledge carry the weight.
Convolutional neural networks, first. RRDB blocks are stacks of convolutions; the discriminator is convolutional; even the diffusion U-Net is built from convolutional layers with attention bolted on. You need to know how a convolution slides a kernel across an image, why receptive fields grow with depth, and how feature maps encode spatial hierarchies — edges, textures, parts, objects. Without this, the residual and dense connections in an RRDB read as decorative wiring instead of as deliberate gradient pathways.
Diffusion models, second. SUPIR and Magnific are unintelligible without the forward-noising / reverse-denoising mental model. You need to know that diffusion training corrupts clean images with progressively more Gaussian noise and trains a network to predict the noise added at each step. Sampling reverses this: start from pure noise, denoise iteratively, end with an image. Conditional diffusion — where text prompts or low-resolution inputs steer the trajectory — is the mechanism the entire upscaler-as-restoration framing depends on. The relationship between AI Image Editing workflows like img2img and an upscaler is direct: both are conditional denoising problems with different conditioning signals.
Latent space and adaptors, third. SDXL operates in a compressed latent space, not pixel space. The encoder/decoder pair that round-trips between pixels and latents is part of the architecture, and adaptors — including the family that LoRA for Image Generation fits into — are the mechanism by which a frozen base model gets specialized for new tasks without retraining. SUPIR’s 600M-parameter adaptor is conceptually adjacent to a LoRA: a smaller trainable module that bends a much larger frozen network toward a specific objective.
Beyond these three, fluency in adversarial training (loss balance, mode collapse, gradient saturation) is the prerequisite for reading the GAN literature, and basic probability — distributions, expectations, KL divergence — is the prerequisite for reading the diffusion literature. The architectures are not hard; the substrate is, and most confusion about upscalers is actually confusion about CNNs, diffusion, or adaptors masquerading as confusion about super-resolution.
What the Architectural Split Predicts About Outputs
The architecture is not a footnote to the result. It is the result, projected backward.
- If you upscale a textured surface — fabric, foliage, brick — and the output looks plausible but invented, you are seeing a diffusion prior dominate the input.
- If you upscale a face and Real-ESRGAN produces a smooth, slightly waxy result while SUPIR produces a sharper but subtly different person, you are seeing the gap between perceptual loss optimization and full generative resampling.
- If a tiled diffusion upscale shows seams or repeating patterns at tile boundaries, the scheduler — not the model — is the failure point.
The Magnific Creativity slider exposes this trade-off as a user control: high creativity gives the prior more authority and the input less. SUPIR’s restoration-guided sampling does the same thing programmatically, modulating how aggressively the diffusion trajectory snaps back toward the degraded input.
Compatibility & licensing notes:
- SUPIR license: Non-commercial use only; commercial deployment requires written permission from the authors. Plan for this before building a product on the SUPIR weights.
- ComfyUI + Ultimate SD Upscale: A January 2026 ComfyUI update broke certain Linux setups, with one community report from CachyOS (CachyOS Forum). The Ultimate SD Upscale node itself remained compatible — the breakage was upstream.
- Topaz Gigapixel: Current line is the v8.4.x series, with Wonder 2 and Recover 3 cloud models added in January 2026 (Topaz Community). There is no “Gigapixel 9” as of April 2026; some marketing references “Gigapixel 8 + Bloom” as a product pairing.
Rule of thumb: Pick the architecture by the failure mode you can tolerate. GAN upscalers fail toward over-smoothing; diffusion upscalers fail toward hallucination.
When it breaks: Both families share the same hard limit — neither model can recover information that was destroyed. They can only produce plausible substitutes drawn from their respective priors. When the input is degraded past the point where the prior can reconstruct rather than invent, the output stops being a faithful upscale and starts being a generated image that resembles the source. The architecture cannot fix this; it can only choose which kind of fiction it prefers.
The Data Says
Modern AI upscalers split into two architectural families — GAN upscalers built from RRDB blocks and relativistic discriminators, and diffusion upscalers built on top of foundation models like SDXL with adaptors and language-model conditioning. The split is not a stylistic preference. It is a structural commitment about where detail comes from: a perceptual loss trained on degraded pairs, or a generative prior absorbed from millions of unrelated images. Understanding the components is the prerequisite for predicting which family will fail on your specific image — and why.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors