From Repo Indexing to Memory Files: Prerequisites and Limits of Code Context Engineering
Table of Contents
ELI5
Context engineering for code is the discipline of deciding what an AI coding agent reads at every step — repo indexes, prompts, memory files, tool outputs — so the model has enough signal to act without drowning in noise.
Watch a developer use Cursor on a five-thousand-line side project and the output looks miraculous. Watch the same developer point it at a fifty-thousand-file monorepo, and the miracle dies. The model did not get worse between sessions. The context did. And the strange part is that the failure rarely looks like running out of room — it looks like the agent forgetting things it just read.
The five concepts you need before any of this makes sense
Most explanations of Context Engineering For Code start with what the engineer should do. That is the wrong end of the telescope. The practice only becomes legible once you understand what an AI coding agent is physically incapable of doing without help — and what kinds of help it can actually absorb.
Andrej Karpathy gave the discipline its name in mid-2025, calling it the delicate art and science of filling the context window with just the right information for the next step (Karpathy on X). Shopify’s Tobi Lütke amplified it as the successor to prompt engineering. The renaming was not cosmetic. Prompt engineering treated the prompt as the unit of work. Context engineering treats the entire token stream — system prompt, retrieved code, tool descriptions, prior turns, memory files — as the unit of work.
What do you need to understand before learning context engineering for code?
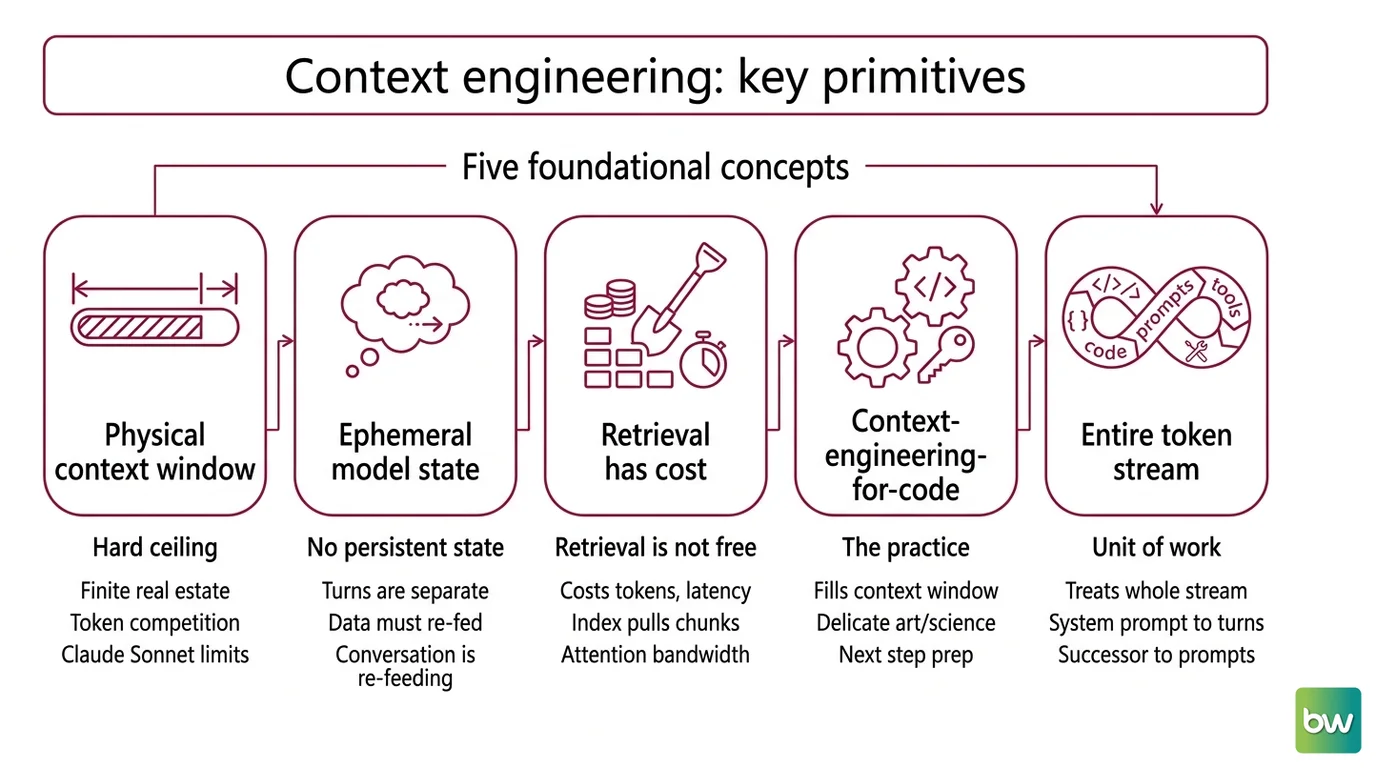
Five primitives. None of them are exotic, but missing any one of them turns context engineering into cargo cult.
First, the context window is a hard physical ceiling, not a soft suggestion. Claude Sonnet 4.5 ships with a 200K-token standard window; the 1M-token beta was retired on 30 April 2026 (Claude API Docs). Sonnet 4.6 and Opus 4.7 expose the 1M window as generally available, no beta header required. Every token the model reads — your code, the prompt, the tool schemas, the conversation history — competes for the same finite real estate.
Second, an LLM has no persistent state between API calls. Whatever the model “knew” in turn three is gone in turn four unless something — your code, your harness, a memory file — pasted it back in. The fiction of a long conversation is just disciplined re-feeding.
Third, retrieval is not free. Every chunk of code an indexer pulls into the prompt costs tokens, latency, and attention bandwidth. Pulling the whole repo “just in case” is the most expensive way to degrade the model’s output.
Fourth, tools are part of the context. Each MCP server you wire up injects its schema, its descriptions, its return values. Adding tools is not additive; past a threshold, more tools means more noise.
Fifth, the agent loop is recursive. The output of one step becomes the input of the next. Errors compound. This is why Agentic Coding succeeds or fails on what gets kept and what gets discarded between iterations — far more than on raw model capability.
How repo indexing differs from prompt stuffing
There is a popular belief that AI coding tools “read your codebase.” They do not, in any meaningful sense. They read a tiny slice, selected by an index, on demand.
Cursor maintains a local embedding index. It reportedly uses a tree-sitter AST parser to split source files at function and class boundaries, computes a Merkle tree of file hashes so only changed regions are re-embedded, and ships obfuscated vectors to a Turbopuffer-backed store. The reported scale is repos up to roughly five hundred thousand files before quality starts to slip (buildmvpfast). GitHub Copilot’s @workspace does something different — closer to prompt assembly with RAG-style retrieval — and the reported ceiling is closer to a hundred thousand files.
The shape of the index decides the shape of the answers. A function-boundary split makes the agent good at “find me the function that does X” and terrible at “explain how this feature flows across these seven modules.” Cross-file reasoning is a separate problem the index does not solve.
Memory files: the project-root contract
The newest primitive in this stack is the markdown memory file, sitting at the project root. AGENTS.md is the cross-tool standard, currently adopted by more than sixty thousand repositories and read natively by Codex, Cursor, Copilot, Gemini CLI, Aider, Windsurf, Zed, Factory, and Jules, with around twenty more agents supporting it (AGENTS.md). The file is plain markdown, schema-free; agents parse it as-is and treat its contents as project-level instructions.
CLAUDE.md plays the same role for Claude Code — coding standards, architecture notes, review checklists — loaded at session start. The OpenAI Codex research cited by Augment Code reports that the mere presence of an AGENTS.md file correlates with a 29% reduction in median runtime and a 17% reduction in output tokens (Augment Code). Treat those numbers as a directional signal, not a guarantee; the gain is what you would expect when an agent stops re-discovering the same conventions every session.
What memory files are not is persistent agent memory across sessions. They are static documents the agent re-reads. The newer Claude Code subagents add an opt-in memory: frontmatter field that lets a specialised agent persist patterns to a memory directory for reuse across runs — but even there, the memory is just structured text the parent process loads on demand.
The fifth piece, and the most genuinely new one, is the Model Context Protocol. MCP was introduced by Anthropic in November 2024 as an open standard, transports JSON-RPC 2.0, and reuses message-flow ideas from the Language Server Protocol. The spec sits at version 2025-11-25 (MCP Specification) and the governance was donated to the Agentic AI Foundation, a Linux Foundation directed fund, in December 2025. The Python and TypeScript SDKs together pull in roughly ninety-seven million monthly downloads. MCP is what turns “the agent can call my database” from a vendor-specific integration into a swap-in protocol.
The ceilings nobody warns you about
Knowing the five primitives is the floor. The ceiling is a set of failure modes that look like model regression but are actually context pathology.
What are the technical limits of context engineering for AI coding assistants?
The biggest one is context rot. Chroma Research benchmarked eighteen frontier models on long-input performance and found that output quality degrades well before the window is full (Chroma Research). On their needle-in-a-haystack variants, GPT-4-1106 drops from 96.6 at 4K input tokens to 81.2 at 128K. Llama 3.1-70B drops from 96.5 to 66.6 over the same range. Gemini 1.5 Pro is the exception, losing only about 2.3 points at 128K. The pattern across all eighteen models is the same direction: more input, less reliable output.
Not random noise. Attention dilution.
The mechanism is geometric. Attention is a softmax over the sequence, and as the sequence lengthens, probability mass spreads thinner across more tokens. The model still attends to the relevant span — just with less confidence relative to the surrounding noise. This is why a 200K-token model can show meaningful degradation at 50K tokens of input. The window is not full. The signal-to-noise ratio is wrong.
The second ceiling is the lossy summary problem at the subagent boundary. Claude Code subagents run in independent context windows, with their own system prompt, scoped tool list, and independent permissions; the parent process receives only the subagent’s final summary. The architectural win is obvious — the parent context stays small while the subagent does heavy work. The cost is equally obvious: anything the subagent observed but did not summarise is unrecoverable. If the subagent saw a subtle inconsistency in a test fixture and decided it was irrelevant, the parent will never know that decision was made.
The third ceiling is tool schema bloat. Each MCP server you wire in adds its tool schemas to the prompt every turn. The model has to attend to all of them to decide which one to call. As the wired-in tool surface grows, selection accuracy drops — the same context rot effect, applied to the tool-choice distribution rather than the answer distribution.
The fourth is the index staleness gap. Cursor’s Merkle tree only re-embeds what changed as the indexer sees it. A branch switch, a partial sync, a file written by another tool — and the embeddings describe a repository that no longer exists. The agent retrieves confidently from a fossil.
The fifth, and the most uncomfortable, is the
Knowledge Cutoff interacting with your dependency tree. The model knows the API of your library as it existed on its training cut. Your package.json may already be three minor versions ahead. Without explicit version pinning in your memory file or retrieved docs in the context, the agent will write fluent code against the wrong API and the test suite will catch it — or worse, will not. This is also where
AI Code Migration workflows fail most often: the agent migrates code against the API it remembers, not the one your repository actually targets.
What this predicts about your AI coding workflow
The mechanism gives the predictions. Once you see context as a finite, lossy channel, the failure modes you have been blaming on the model become predictable consequences of the pipe.
- If you double the size of the retrieved code without changing the relevance ranking, you should observe slower responses and lower accuracy, not higher coverage.
- If you add an MCP server without removing one, you should observe a small but real drop in tool selection accuracy across all calls — including the calls that have nothing to do with the new tool.
- If you spawn a subagent for a non-trivial task, you should observe the parent process making decisions later that contradict information the subagent saw and discarded.
- If you upgrade a dependency without updating your memory file or feeding the new docs into context, you should observe fluent, confident, wrong code against the old API.
These are not edge cases. They are what the geometry of attention guarantees once you read it carefully.
The practical consequence is that context engineering is closer to information architecture than to prompting. You are deciding what enters a finite channel, in what order, at what density, and what gets discarded. The Vibe Coding workflow — type a wish, accept whatever the model produces — works on small projects precisely because the channel is uncongested. The same workflow on a real codebase silently exceeds the channel’s capacity and the developer mistakes the symptoms for model weakness.
Rule of thumb: if you cannot point to the specific tokens that justify a model decision, you have not engineered the context — you have hoped.
When it breaks: the most common failure is silent. The model produces plausible code against a stale index, an outdated dependency, or a forgotten subagent decision; the developer accepts it because it compiles; the regression surfaces in production weeks later. There is no error message because, from the model’s point of view, nothing went wrong.
The Data Says
Across eighteen frontier models, more input tokens reliably mean less reliable output — sometimes by thirty points on the same benchmark. The window size on the model card is the maximum the model can ingest, not the size at which it stays sharp. Context engineering for code is the discipline of staying well inside that sharper region while still feeding the model what it actually needs.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors