From Recall Failures to RAG-Fusion: Prerequisites and Inner Workings of Query Decomposition and Routing
ELI5
Query transformation rewrites the user’s question into one or several smaller queries the retriever can actually find. It treats the prompt as a search plan, not a search string.
A user types: “Did the Red Sox or the Patriots win a championship more recently?” Your Retrieval Augmented Generation stack pulls a handful of chunks about the Patriots, none about the Red Sox, and the model invents a verdict. The retrieval call did not break. The pipeline did exactly what you asked. The question itself was the failure.
This is the layer that Query Transformation sits in — between the user’s natural language and the retriever’s index. Almost every interesting failure in RAG hides somewhere on this layer.
What you need under your belt before opening this engine
Query transformation is not a primitive. It is a control plane that sits above retrieval, and it inherits assumptions from every layer below it. If those assumptions are fuzzy, the fix you apply at the transformation layer will look like it works on the demo and quietly underperform in production.
Three pieces of prior knowledge do most of the work.
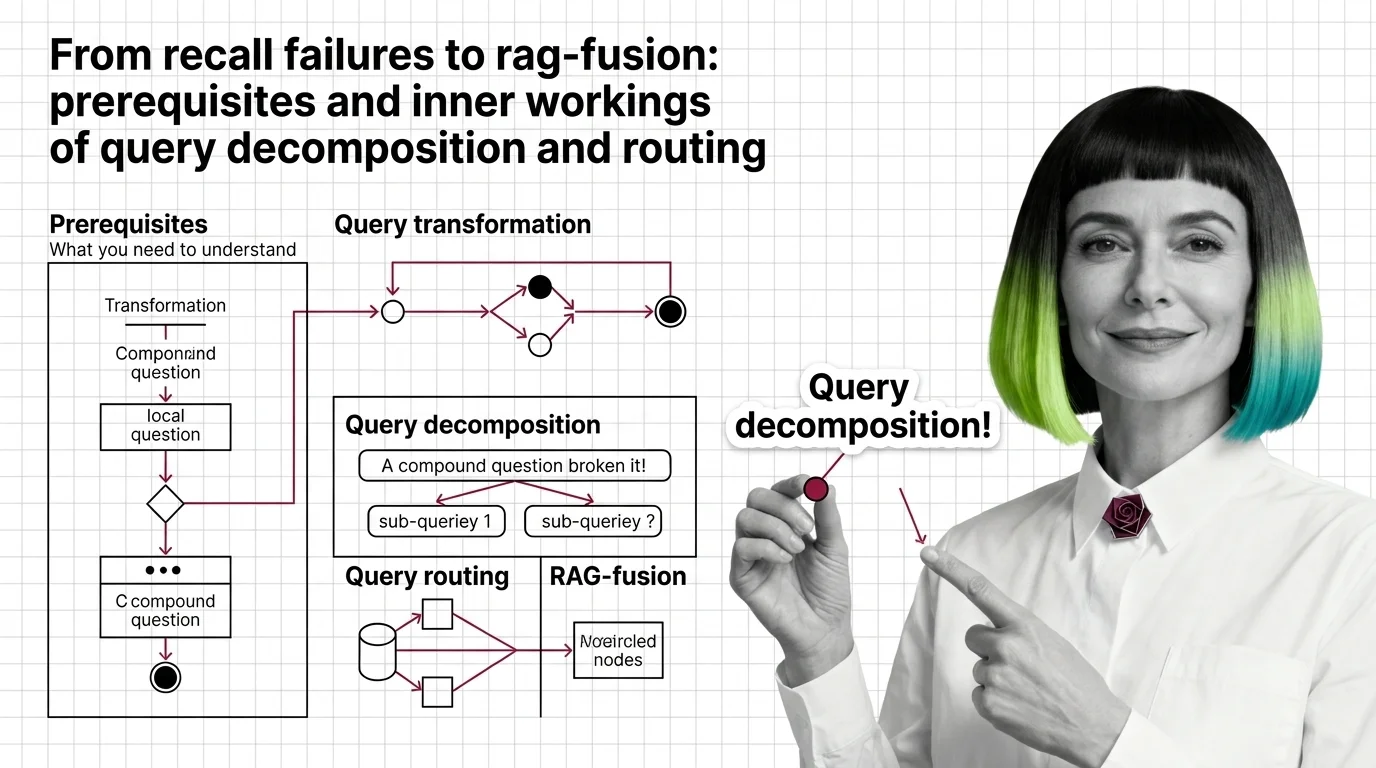
What do you need to understand before learning query transformation?
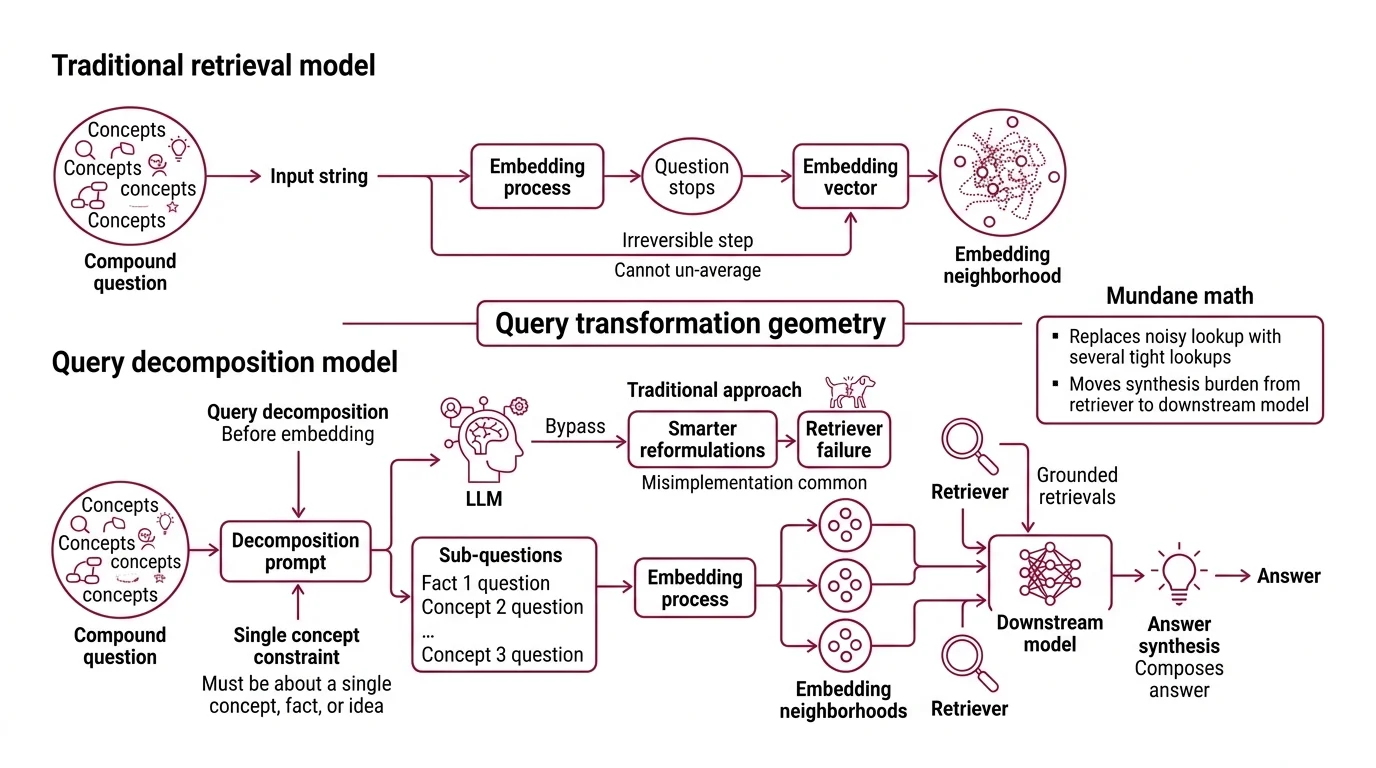
First, you need to understand why dense retrieval can fail to recall. A bi-encoder maps a query to a single point in a vector space and asks: which document points are nearest? The geometry is generous when the query is one tight idea — “the capital of Estonia” — and brutal when the query packs two ideas into one sentence. “Compare Estonia’s e-residency program to Singapore’s” becomes a single embedding that lives between the two true answers and matches neither cleanly. The retriever does not know it has averaged two semantic neighborhoods into one mediocre one.
Second, you need a working model of Hybrid Search. Lexical scoring (BM25) and dense scoring rank documents by different criteria, and reciprocal rank fusion (RRF) is the standard way to combine their outputs. Query transformation will eventually feed multiple queries into both lanes, and RRF will reappear inside RAG-Fusion. If you treat hybrid search as a black box now, the fusion math will look invented later.
Third, you need to know what Reranking does and what it does not do. A cross-encoder reranker can reorder the top-k of a single retrieval pass, but it cannot rescue a recall failure — it cannot promote a document that was never retrieved. This is the sentence to keep on a sticky note. Transformation fixes recall; reranking fixes precision. The two layers solve different problems and rarely substitute for each other.
With those three priors loaded, the rest of the system becomes legible.
The geometry of splitting a question
There is a moment in any retrieval system where the question stops being a string and starts being a vector. That moment is irreversible inside a single forward pass — you cannot un-average an embedding. Query decomposition exploits this by intervening before the irreversible step.
The technique was named alongside its siblings (rewrite-retrieve-read, step-back, multi-query, and RAG-Fusion) by the LangChain team in their October 2023 taxonomy of query transformations (LangChain Blog). Decomposition is the most aggressive of them. It assumes the user’s question is composite and explicitly breaks it apart.
How does query decomposition break compound questions into retrievable sub-queries?
The mechanism is small enough to fit in a paragraph and important enough to misimplement frequently.
A decomposition prompt asks an LLM to rewrite one input question as a list of sub-questions, with one operative constraint: each sub-question must be about a single concept, fact, or idea (LangChain Decomposition Guide). The constraint is the entire engineering decision. Without it, the LLM produces “smarter-sounding” reformulations of the original compound question, and the retriever fails the same way it failed before.
LangChain’s own worked example is unfashionably simple: “Who won a championship more recently, the Red Sox or the Patriots?” decomposes to “When did the Red Sox last win a championship?” and “When did the Patriots last win a championship?”. The compound question has no clean embedding neighborhood. The two sub-questions each have a tight one. The downstream model then composes the answer from two grounded retrievals instead of one ungrounded guess.
Notice what just happened.
Not a smarter retriever. A friendlier geometry.
The math behind this is mundane: you have replaced one embedding lookup in a noisy region with several lookups in tighter ones, and you have moved the burden of synthesis from the retriever to the generator — a model that can synthesize, given grounded inputs. This is why decomposition sometimes works on the same index that just failed; nothing about the index has changed.
A second, related family — multi-query retrieval — generates multiple search queries that can be executed in parallel when the question relies on several sub-questions. The naming convention varies between frameworks. The mechanism is the same: replace one fuzzy lookup with several precise ones, then pool the results.
Where decomposition ends and the rest of the stack begins
Decomposition assumes you know which retriever to call. Routing decides that. RAG-Fusion takes a different bet again — it assumes the user’s phrasing is the weakest link and rewrites the same question several ways. The three transformations are not mutually exclusive; production systems frequently chain them.
How do query routing and RAG-Fusion fit into the query transformation stack?
LlamaIndex’s reference implementation of routing is the cleanest mental model. A router takes a user query and a set of “choices” defined by metadata, and returns one or more selected choices using LLMs to make the decision (LlamaIndex Docs). The choices are usually retrieval engines. One engine indexes the company’s customer-support transcripts; another indexes its legal contracts; a third does numeric summarization over a SQL warehouse. The router’s job is to pick — not to retrieve. LlamaIndex exposes four selectors: LLMSingleSelector and LLMMultiSelector, which use text completion, and PydanticSingleSelector and PydanticMultiSelector, which use function-calling for structured output. Multi-selectors fan out to several engines and aggregate results.
RAG-Fusion sits in a different corner of the design space. Originally popularized by Adrian Raudaschl in 2023 and formalized in a 2024 arXiv paper by Zackary Rackauckas, the technique combines RAG and reciprocal rank fusion by generating multiple queries, retrieving for each, then reranking with reciprocal scores and fusing the documents (arXiv). Raudaschl’s reference implementation generates the original query plus four LLM-rewritten variants and combines all five result lists via RRF (Raudaschl’s GitHub repository). The number four is a property of that implementation, not a constant of the technique — published variants use anywhere from a couple to dozens.
The key property: RAG-Fusion does not assume the question is compound. It assumes the question is phrased badly. A single user query gets perturbed into several semantic neighbors, each of which retrieves slightly different documents, and RRF rewards documents that show up consistently across all of them. The signal you keep is the documents the variants agree on. The noise you discard is the per-phrasing accident.
What the retrieval geometry predicts
Once you see decomposition, routing, and RAG-Fusion as three different bets about where the failure lives, the system stops being a grab bag of tricks.
- If your retrieval failures correlate with compound questions, you should observe the largest gains from decomposition.
- If your failures correlate with the user picking the wrong index — asking the legal corpus an HR question — you should observe the largest gains from routing.
- If your failures correlate with brittle phrasing — small wording changes flipping the result set — you should observe the largest gains from RAG-Fusion.
The recent literature supports the direction even if absolute numbers vary. A July 2025 paper on Question Decomposition for RAG reports MRR@10 gains of 36.7% and F1 gains of 11.6% over standard RAG baselines (arXiv). An October 2025 follow-up using bandit-driven sub-query selection reports roughly 35% gains in document-level precision and around 15% in α-nDCG (arXiv). The numbers are domain-specific and the baselines are unforgiving — treat them as direction, not promise.
These transformations also compose. A router can wrap a Sub-Question (decomposition) engine and a vanilla single-shot engine as two of its choices, which is the canonical LlamaIndex pattern. Agentic RAG stacks go further and let an LLM rerun the loop with a new transformation when the first answer is unsatisfactory. The decomposition layer rarely lives alone in production.
Rule of thumb: Diagnose the failure mode before picking the technique. Compound-question failures want decomposition; index-selection failures want routing; phrasing-fragility failures want RAG-Fusion.
When it breaks: Every transformation multiplies retrieval cost — N sub-queries means N embedding calls, N index lookups, and an extra LLM call to synthesize. On a slow vector database or a budget-constrained inference path, the latency tax can wipe out the recall gain. Decomposition over a question that was never compound is also actively harmful: the LLM invents structure that does not exist, the retriever returns noise for the invented sub-questions, and the synthesis step launders that noise into a confident wrong answer.
Documentation & version notes:
- LangChain v0.1 → v1.0: The dedicated “Query Analysis → Decomposition” guide page exists only under archived v0.1 docs (
python.langchain.com/v0.1/...). Current v1.0 docs are agent-first and do not host an equivalent page. Older versioned URLs still resolve.- LlamaIndex docs domain:
docs.llamaindex.aipermanently redirects todevelopers.llamaindex.ai. Update bookmarks; cached links continue to work.
A subtler payoff
The deeper consequence of query transformation is that the locus of model reasoning shifts from the output to the input. The LLM is no longer asked “what is the answer?” first. It is asked “what would I have to retrieve to answer this?” — and only after that retrieval does it generate. Most production teams who get serious about RAG end up rewriting their pipeline around this idea, regardless of which specific transformation they pick.
The Data Says
Query transformation is the layer where retrieval failure is diagnosed and triaged. Decomposition splits compound questions; routing chooses the right index; RAG-Fusion stabilizes brittle phrasing. The same sub-query that a vanilla retriever cannot find, a decomposed pipeline often locates without changing a single document or embedding model. The failure was geometric, not informational.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors