From Recall and MRR to Faithfulness: RAG Evaluation Prerequisites
Table of Contents
ELI5
RAG evaluation is two systems being graded at once. The retriever is judged on whether it found the right documents and ranked them well. The generator is judged on whether its answer stays loyal to those documents. One score for both is a fiction.
Engineering teams keep building retrieval-augmented generation systems and grading them with a single number — usually some flavor of “did the answer match the expected answer.” Then a model produces a confident, fluent paragraph that contradicts the document it just retrieved, and the team is left holding a metric that did not warn them. The reason is not that the metric was wrong. The reason is that the system being measured has two halves, and each half can fail in ways the other half cannot detect.
The Anomaly Hidden Inside Every RAG Failure
A RAG pipeline answers a question by chaining two probabilistic processes. First, a retriever pulls a handful of passages from a vector store. Then a generator — a LLM As Judge-adjacent Context Window consumer — writes an answer conditioned on those passages. The output is a single string. The mistakes are not.
A wrong answer can come from the retriever returning irrelevant chunks, from the retriever returning relevant chunks in the wrong order, from the generator ignoring the chunks entirely, or from the generator paraphrasing them into something the source never said. These failure modes look identical from the outside. From the inside, they require different metrics, different fixes, and often different teams.
That is why RAG Evaluation cannot inherit its toolkit wholesale from either classical information retrieval or classical NLG benchmarks. The field has spent the last two years assembling a hybrid stack — and before that stack makes sense, you need to understand what each layer is actually measuring.
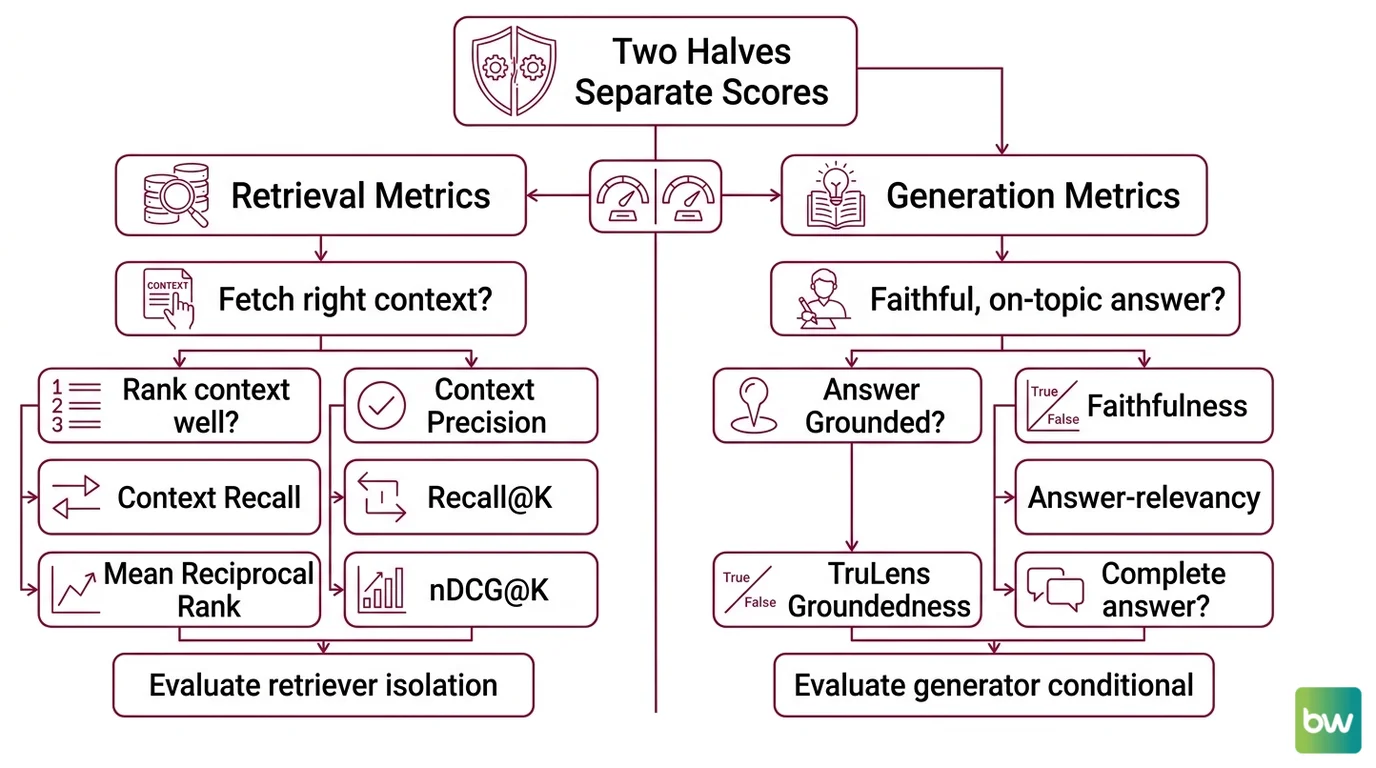
The Two Halves That Need Separate Scores
A RAG system is the composition of a retriever and a generator. The metrics that grade it inherit that composition. If you only measure end-to-end answer quality, you cannot tell which half broke. If you only measure retrieval quality, you cannot tell whether the generator squandered good context. The frameworks that took over RAG evaluation — Ragas, TruLens, DeepEval — all share a structural commitment: split the score into a retrieval side and a generation side, and grade each one against what it is actually responsible for.
What is the difference between retrieval metrics and generation metrics in RAG?
Retrieval metrics ask: did the system fetch the right context, and did it rank that context well? They are inherited from information retrieval research and they treat the retrieved chunk list as a ranked output to be judged against either a labeled relevance set or, in newer reference-free variants, against an LLM judge. Recall@K, Mean Reciprocal Rank, nDCG@K, and Ragas’s Context Precision and Context Recall all live here. They evaluate the retriever in isolation — what came back from the vector store, in what order, and whether the relevant material was inside the top K.
Generation metrics ask a different question: given the context that was retrieved, did the generator produce a faithful, on-topic, complete answer? These metrics do not care how the chunks were ranked. They care whether the answer is grounded in those chunks and whether it actually addresses the user’s question. Faithfulness, Answer Relevancy, and TruLens’s Groundedness all live here. They evaluate the generator conditional on whatever the retriever happened to deliver.
The split matters because the failures are not symmetric. A retriever that achieves high Context Recall can still feed a generator that hallucinates around the evidence — and a Faithfulness score will catch that even if the retrieval scores look pristine. Conversely, a generator that scores perfectly on Faithfulness can still be useless if the retriever never surfaced the right document; the answer is loyal to the wrong source. The TruLens team formalized this composition as the RAG Triad — Context Relevance, Groundedness, and Answer Relevance — three measurements that together cover the joint failure surface, per the TruLens Docs.
So the difference is not stylistic. Retrieval metrics judge a ranked list against a relevance signal. Generation metrics judge a free-text answer against a context. They are different mathematical objects, and grading a RAG system means tracking both.
The IR Vocabulary You Need Before Anything Else
Before faithfulness and answer relevancy make sense, the older information retrieval metrics need to. The retrieval side of every modern RAG framework is built on top of them — Ragas’s Context Precision is essentially Precision@k under a binary-relevance regime, and Context Recall is the classical recall question phrased for ground-truth chunks. If you do not see what those parent metrics are doing, the children look arbitrary.
What do you need to understand before learning RAG evaluation?
You need a small vocabulary from information retrieval, one primitive from natural language generation, and one structural distinction about ground truth. They are the prerequisites that turn the modern frameworks from a list of names into a coherent stack.
Recall@K and Precision@K — the unranked baseline. Recall@K is the share of all relevant items that landed in the top K results, defined as (number of relevant items in top K) / (total number of relevant items), per the Pinecone IR guide. Precision@K is the share of the top K that were relevant. Neither one is rank-aware. A retriever that returns the only relevant document at position 1 and a retriever that returns it at position 10 score identically on Recall@10. That is a feature for some questions and a bug for others.
Mean Reciprocal Rank — the rank-aware sibling. MRR computes (1/|Q|) × Σ(1/rank_i) where rank_i is the rank of the first relevant result for each query, per the Weaviate retrieval-metrics guide. MRR rewards systems that put the right answer at position 1 and penalizes systems that bury it. For RAG specifically, where downstream LLMs often weigh earlier context more heavily, rank position is not a cosmetic concern.
nDCG@K — graded relevance. Real document relevance is rarely binary. Some chunks are highly relevant, some tangentially relevant, some irrelevant. nDCG@K — Normalized Discounted Cumulative Gain — handles graded judgments by discounting relevance by rank position and normalizing against the ideal ordering, defined as DCG@k / IDCG@k per Evidently AI. It is the metric to reach for when “relevant or not” is too coarse for the task.
LLM-as-judge — the generation-side primitive. Faithfulness, Answer Relevancy, and Context Precision in modern frameworks do not run string-similarity scores against gold answers. They prompt a separate model to read the response, decompose it into atomic claims, and verify each claim against the retrieved context, per the Ragas Docs on Faithfulness. The score is (claims supported by context) / (total claims). This is a profound shift from BLEU and ROUGE, which compared n-gram overlap against a reference answer. The judge-model approach can grade open-ended generation where no single reference answer exists — and it is the reason reference-free RAG evaluation became practical.
Reference-free vs. reference-required. This is the structural distinction most teams miss until it bites them. Ragas separates its metric catalog cleanly: Context Precision, Faithfulness, Response Relevancy, and Noise Sensitivity are reference-free — they only need the question, the retrieved context, and the response. Context Recall, Context Entities Recall, and Answer Accuracy require ground truth — a human-annotated correct context or correct answer, per the Ragas Docs. Teams adopt Ragas expecting “no annotation needed” across the board, then discover that recall — the metric they care about most — does need labels after all.
Once those primitives are in place, the modern stack reads as a translation rather than a vocabulary list. Context Precision is Precision@k weighted by binary relevance, with the binary relevance label produced by an LLM judge instead of a human annotator. Context Recall is classical recall against an annotated ground-truth context. Faithfulness is an LLM-judged claim-verification ratio. Answer Relevancy is an LLM-judged response-question alignment, not a factual correctness score — a confusion the Ragas Docs explicitly flag.
What the Metric Stack Predicts
Once the retriever and the generator are graded separately, the failure modes stop being mysterious. They become predictions you can read directly off the score sheet.
- If Context Recall is low, the retriever did not return the relevant material at all — no generation-side fix can save the answer, and the right move is to revisit chunking, embedding model, or query rewriting.
- If Context Recall is high but Context Precision is low, the relevant material is present but buried under noise — the generator may still hallucinate because the signal-to-noise ratio in the context window is poor.
- If retrieval scores look healthy but Faithfulness is low, the generator is fabricating around evidence it actually has — the fix is on the generation side, often a prompt that forces explicit citation of context.
- If Faithfulness is high but Answer Relevancy is low, the answer is grounded but does not address the question — the system is loyal to the wrong target.
Rule of thumb: report at least one retrieval-side metric and at least one generation-side metric on every evaluation run. A single score will hide whichever half failed.
When it breaks: the entire LLM-as-judge approach inherits the limitations of the judge model. If the judge is weaker than the system under test, or if it shares the same training-data biases as the generator, scores can look stable while real quality drifts. Reference-free metrics measure agreement with a model, not truth — and that gap matters most exactly when you need evaluation most.
The Data Says
A RAG system has two failure surfaces, and any honest evaluation needs at least one metric per surface. The information-retrieval lineage gave the field its rank-aware retrieval primitives; the LLM-as-judge revolution made reference-free generation grading practical. Both layers are now baseline expectations — Ragas, TruLens, and DeepEval all encode the split, and treating end-to-end answer quality as a single scalar is the fastest way to ship a system whose failures you cannot diagnose.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors