From RAG to Agents: Prerequisites and Hard Limits of Agentic RAG
ELI5
Agentic RAG wraps a classic retrieve-then-generate pipeline inside a reasoning loop. An agent decides when to retrieve, judges what it got, and rewrites the query if the answer is weak — instead of retrieving once and hoping.
Take a retrieval pipeline that works ninety-five times out of a hundred. Wrap an agent around it, add a reranker, plug in an evaluator, give the model permission to rewrite the query and try again. The end-to-end success rate quietly slides toward four-in-five. The system did not get worse. It got longer. That is the part most teams discover after the demo, in production, with traffic.
The Stack You Inherit Before You Touch an Agent
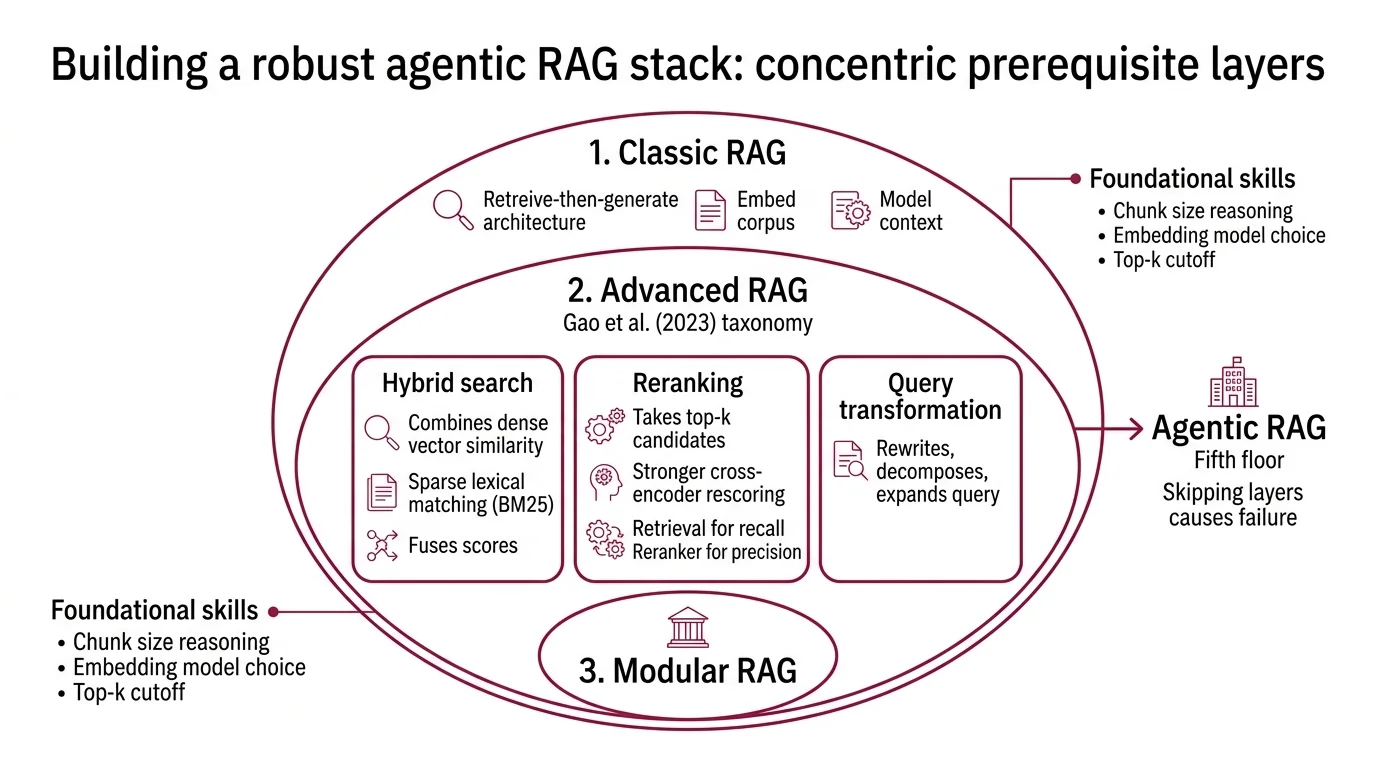
Agentic RAG is not a single technique you can learn in isolation. It is the fifth floor of a building, and most production failures happen because someone tried to install the elevator before the second floor existed. The Singh et al. (2025) survey on agentic RAG treats it explicitly as a generalisation of three earlier layers — and skipping any of them turns the agent loop into theatre.
What do you need to know before learning agentic RAG?
Three concentric layers, each a hard prerequisite.
The first layer is classic Retrieval Augmented Generation — the original retrieve-then-generate architecture introduced in Lewis et al. (2020). You embed a corpus, fetch the top-k chunks for a query, and stuff them into the model’s context. Naive in shape, but every piece of the agentic stack still depends on it. If you cannot reason about chunk size, embedding model choice, or top-k cutoff, no orchestrator on top will save you.
The second layer is advanced RAG — the techniques the field stacked on top of the naive pipeline once it became obvious that one-shot retrieval underperforms. The Naive / Advanced / Modular taxonomy in the Gao et al. (2023) RAG survey is the canonical reference here, and three primitives matter:
- Hybrid Search combines dense vector similarity with sparse lexical matching (typically BM25). Dense retrieval finds semantic neighbours; sparse retrieval pins down exact identifiers, rare tokens, and acronyms the embedding space dilutes. Most production retrieval systems run both and fuse the scores.
- Reranking takes the top-k from retrieval — say, fifty candidates — and rescoring them with a stronger cross-encoder that actually reads each candidate against the query. The retrieval index is built for recall; the reranker is built for precision. They are different jobs.
- Query Transformation rewrites, decomposes, or expands the user’s question before it ever touches the index. User queries are usually shorter, vaguer, and more under-specified than the documents that answer them; bridging that gap is one of the highest-leverage interventions in the stack.
A fourth advanced technique, Contextual Retrieval, prepends document-level context to each chunk before embedding it — so a chunk reading “The latency was 200ms” carries enough surrounding text to be retrievable as “Service X showed 200ms latency in the Q4 review.” Without it, retrieval over real corpora becomes a guessing game across stripped-of-context fragments.
The third layer is agent primitives — the patterns that turn a one-shot pipeline into a loop. Yao et al. (2022) introduced the ReAct pattern, the interleaved Thought → Action → Observation cycle every agentic-RAG implementation derives from. Anthropic’s engineering team catalogues the six composable patterns most teams build from: prompt chaining, routing, parallelization, orchestrator-workers, evaluator-optimizer, and the autonomous agent itself.
Sitting between the second and third layers are the bridge papers. Self-RAG (Asai et al., 2023) trains the language model to emit reflection tokens that decide whether retrieval is needed at all and whether the generation is grounded. CRAG (Yan et al., 2024) bolts a separate lightweight retrieval evaluator onto the pipeline, scoring each retrieved document and routing to one of three corrective actions: use as-is, refine, or fall back to web search. Both are often described as “agentic,” but be precise — Self-RAG fine-tunes the generator, CRAG adds an external evaluator. Neither is a multi-agent system on its own. They are the conceptual bridge.
The reason this stack order matters: an agent loop is only as good as the primitives it calls. If hybrid search is misconfigured, the agent will obediently rewrite the query and retrieve the same garbage with different syntax. Compounding zero is still zero.
Where the Pipeline Stops Behaving Like a Pipeline
Once you have all three layers and you wire an agent loop on top, the system gains a property classical RAG does not have: it can decide. That sounds like an upgrade. It is also a new physics, and the physics has four hard limits that show up the moment you touch production traffic.
What are the technical limitations of agentic RAG architectures?
Four constraints, all of them compounding — and the operational catalogue (latency, cost, reliability, complexity, observability/overhead) lines up with what production teams actually report.
Latency stacks linearly with steps. A naive RAG call is one retrieval plus one generation. An agentic loop with a planner, two retrieval rounds, a grader, and a synthesis step easily multiplies the wall-clock budget several times over. Each step waits for the previous one’s tokens. There is no parallelism inside a sequential trajectory. Users feel this immediately, and no amount of model speed-up rescues the order-of-operations cost.
Cost scales with the trajectory, not the request. The order-of-magnitude rule of thumb in circulation is roughly $0.001 per query for naive RAG, $0.005 with hybrid + rerank, and $0.02 to $0.10 per query for full agentic RAG (Lushbinary 2026 RAG Production Guide), because a multi-step trajectory makes multiple LLM calls — often with the full retrieved context attached each time. Treat that ladder as illustrative arithmetic, not a price quote — but treat the shape of it as real. A ten-cent query is fine for a knowledge-worker copilot and ruinous for consumer search.
Reliability multiplies, it does not add. This is the most underrated property of the architecture. If retrieval succeeds 95% of the time, reranking is right 95% of the time, and the final generation is grounded 95% of the time, end-to-end success is roughly 0.95 × 0.95 × 0.95 ≈ 0.81 — a three-stage pipeline failing about one in five calls. Each new agent step (a query rewrite, a tool router, a critic) multiplies again. The arithmetic is not a measurement — it is what compounding does to independent probabilities.
Not a glitch. An emergent property of multi-step composition.
Evaluator fragility cascades errors instead of catching them. Every “corrective” step in an agentic-RAG pipeline depends on a critic — a grader model, a reflection prompt, a confidence threshold. When the critic is well-calibrated, it filters bad retrievals and rescues the answer. When the critic is miscalibrated — too lenient, too strict, or systematically wrong on a class of inputs — the corrective step actively makes the pipeline worse, because it confidently routes good answers into a rewrite loop and rubber-stamps bad ones (Meilisearch Blog). Operators most often misdiagnose this: they assume a corrective system is robust by construction, when in fact it inherits the brittleness of its evaluator.
The Lewis-style retrieve-then-generate pipeline is a function. The agentic version is a state machine. They have different debugging tools, different cost models, and different failure modes — and that is before you account for the operational complexity and observability overhead that sit underneath the four physics.
What This Predicts About Your Build
The mechanism makes specific predictions you can test before you commit to the architecture.
- If your retrieval recall on a held-out test set is weak, an agent loop will not fix it — it will just spend more tokens to confirm the bad retrievals. Fix retrieval first.
- If your evaluator (grader / critic) has not been measured against a labelled set, treat the corrective step as a coin flip with extra steps. The agent will follow whatever the evaluator says, including when the evaluator is wrong.
- If your latency budget is sub-second end-to-end, cycle-based architectures (LangGraph-style) will not fit. Pick a router pattern with at most one retrieval round, or pre-compute.
- If you are running consumer-scale traffic, model the per-query cost ceiling first; agentic trajectories make individual queries an order of magnitude more expensive than the advanced-RAG baseline.
Rule of thumb: add an agent loop only after you have measured retrieval recall, reranker precision, and end-to-end latency on the non-agentic baseline.
When it breaks: the typical failure mode is not a single broken component — it is the compounding of three 95%-reliable steps into a roughly 81%-reliable system, with an undiagnosed evaluator that masks which step is responsible for the slide.
Security & compatibility notes:
- LangChain Serialization Injection (CVE-2025-68664, “LangGrinch”): Critical vulnerability allowing secret extraction from agentic stacks built on LangChain Core. Patched in 1.2.5 / 0.3.81 with breaking changes —
load()/loads()now enforce an allowlist, environment-variable interpolation defaults to off, and Jinja2 templates are blocked. Audit any custom serializers before upgrading.- LangChain Path Traversal (CVE-2026-34070): High-severity. Legacy
load_prompt()/load_prompt_from_config()are deprecated; removal is scheduled for 2.0.0. Migrate prompt loading off the legacy helpers now.
The Data Says
Agentic RAG is a generalisation of classic RAG, not a replacement for it — and the generalisation costs latency, dollars, and reliability in measurable, multiplicative ways. Build the three prerequisite layers first; measure the baseline; only then add the loop. The math under the loop does not care about the demo.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors