From RAG to Agentic RAG: Prerequisites and Technical Limits of Retrieval-Augmented Agents
Table of Contents
ELI5
A retrieval-augmented agent wraps the classic RAG pipeline inside a reasoning loop. Instead of retrieving once and answering, the model decides when to search, what to re-query, and when to stop.
A team rolls out their RAG prototype on a Tuesday. By Thursday the demo runs beautifully on a curated set of questions. By the following Monday — the first day of real traffic — the agent loops three times on a query that used to need one retrieval, the per-call cost climbs an order of magnitude, and the median latency drifts past five seconds. Nothing in the code broke. The arithmetic of stacked LLM calls arrived right on schedule.
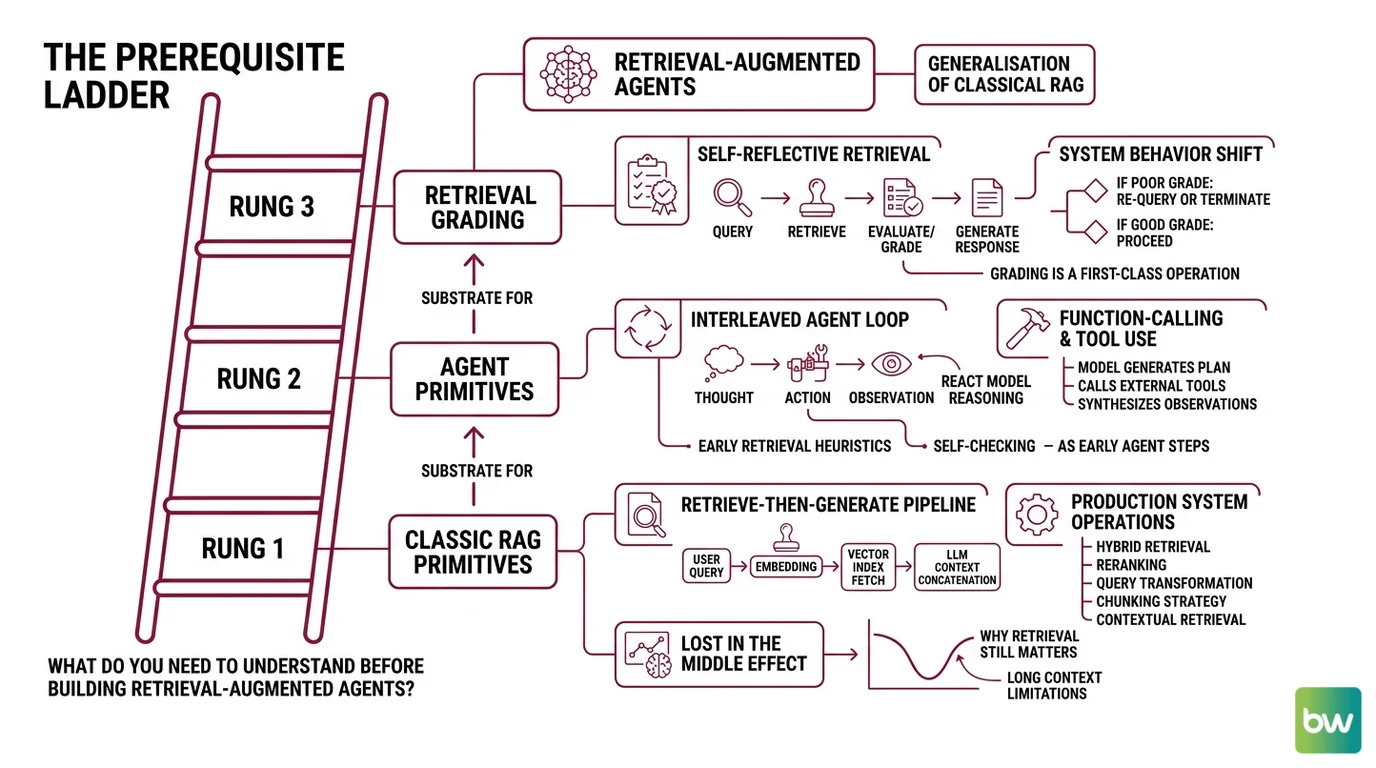
The prerequisite ladder hiding under the word “agent”
The word “agent” is doing a lot of work in 2026. Underneath it sits a tower of older ideas that decide whether your system behaves or thrashes. Before any orchestration code is useful, three layers have to be solid: the classic retrieval pipeline, the reasoning loop, and the small set of papers that connected the two.
What do you need to understand before building retrieval-augmented agents?
The first rung is classic RAG. Lewis et al. (2020) gave the canonical retrieve-then-generate shape: encode the query, fetch the top-k documents from a vector index, stuff them into the prompt, decode an answer. Everything modern is a variation on this loop — dense retrieval, hybrid retrieval (dense + BM25), reranking with a cross-encoder, query transformation, chunking strategy, contextual retrieval. Gao et al. (2023) organise these into a Naive → Advanced → Modular RAG ladder. If you cannot draw that ladder without thinking, the agent on top of it will hide bugs you can no longer locate.
The second rung is the agent loop itself. Yao et al. (2022) introduced ReAct — the interleaved Thought → Action → Observation cycle that nearly every retrieval-augmented agent inherits. The model emits a thought, picks an action (call a tool, retrieve, answer), reads the observation back into context, and repeats. Anthropic Engineering, in its December 2024 essay on building effective agents, formalises six composable patterns the loop can take: prompt chaining, routing, parallelisation, orchestrator-workers, evaluator-optimiser, and the fully autonomous agent. A Retrieval Augmented Agents system is almost always two or three of these patterns glued together — usually routing, evaluator-optimiser, and an autonomous loop with retrieval as a tool.
The third rung is the bridge papers. Self-RAG (Asai et al., 2023) fine-tunes the language model to emit reflection tokens that decide whether to retrieve at all and whether the generation is grounded in the retrieved evidence. CRAG (Yan et al., 2024) takes a lighter route: it bolts a small evaluator onto the retrieval step that scores each document and routes to one of three corrective actions — use, refine, or fall back to web search. Neither is a multi-agent system on its own. Both promoted retrieval grading into a first-class operation, and that is the move that distinguishes Agentic RAG from its predecessors.
Why the bridge papers matter more than they advertise
Read at speed, Self-RAG and CRAG look like incremental tricks. Read carefully, they redefine where the intelligence sits. Classic RAG assumes retrieval works and the generator’s job is to summarise; the bridge papers assume retrieval might be wrong and ask the model to judge its own evidence before committing. Once that judgement step exists, you no longer have a pipeline. You have a controller. The controller can call retrieval twice, rewrite the query, or refuse to answer — and that is exactly the shape every production-grade retrieval-augmented agent now follows.
The four prerequisite ideas map onto this ladder cleanly: Retrieval Augmented Agents is the definition, Agentic RAG is the architectural pattern, Workflow Orchestration For AI is the control-flow substrate, and Code Execution Agents is the tool-execution substrate the agent talks to when retrieval alone is not enough.
What changes when retrieval becomes a tool
In a classic RAG system, retrieval is a step. In an agent, retrieval is a callable function the model decides to invoke. That sounds like a small distinction. It is the entire restructuring.
The Singh et al. (2025) survey — the closest thing to a canonical academic anchor for this area — organises the design space along four axes: agent cardinality (single versus multi-agent), control structure (linear, hierarchical, graph), autonomy (how many decisions the model owns), and knowledge representation (where the documents and memory live). It groups the moves an agent can make into four design patterns: reflection, planning, tool use, and multi-agent collaboration. Retrieval, in this framing, is one tool among many. The agent can also call a calculator, a code interpreter, a SQL engine, or another agent.
The LangChain Docs canonical reference graph captures this in concrete code: generate_query_or_respond → retriever_tool → grade_documents → rewrite_question → generate_answer. Four of those five nodes are decisions, not computations. The LLM is no longer the last step of a pipeline; it is the scheduler. LlamaIndex makes the same shift visible from the other side — its Workflows abstraction wraps the old RAG primitives as event-handlers an agent dispatches against a shared context.
The cleanest mental model is the Weaviate Blog four-part decomposition: an agent is an LLM (role and task) plus memory (short- and long-term) plus planning (reflection, self-critique, query routing) plus tools (retrievers, calculators, web search, APIs). Strip any of those four and you get something simpler — a chatbot, a pipeline, a function-calling app — but not an agent.
The four physics the engineer cannot outrun
Once retrieval becomes a tool inside a loop, the system inherits a set of architectural ceilings. These are not bugs in any vendor’s implementation. They are arithmetic facts of stacked probabilistic systems, and they show up regardless of whether you build on LangGraph, LlamaIndex, Haystack, or roll your own.
What are the technical limitations of retrieval-augmented agents in production?
Four ceilings reliably define the operating envelope:
- Latency stacking. Every loop iteration is at least one LLM call plus one retrieval call. Two iterations is four sequential round trips; three is six. Even with sub-second components, a multi-step trajectory routinely crosses the threshold where users feel the interface “thinking.”
- Per-query cost. As an industry rule of thumb cited in the Lushbinary RAG Production Guide, naive RAG sits around $0.001 per query, hybrid plus rerank around $0.005, and a multi-step retrieval-augmented agent typically lands between $0.02 and $0.10 per resolved query. Order-of-magnitude, not a measured benchmark — but the shape is consistent across vendor reports.
- Reliability multiplication. If retrieve, rerank, and generate each succeed 95% of the time, the chain succeeds 0.95 × 0.95 × 0.95 ≈ 81% of the time. Add an agent loop that calls the chain twice, and you are multiplying again. This is arithmetic, not measurement (Lushbinary RAG Production Guide) — but it is the arithmetic vendors quietly run when they pick how many steps to allow.
- Evaluator fragility. Corrective patterns (CRAG, Self-RAG, evaluator-optimiser graphs) depend on a critic model that decides “retrieve again” or “stop and answer.” The Meilisearch Blog frames the failure mode bluntly: a miscalibrated grader cascades errors instead of fixing them, and the same grader’s biases shape the entire trajectory.
There is a fifth pressure — observability — that operators discover the first time something goes wrong. A bad answer in classic RAG has one place to look. A bad answer in an agent trajectory has a thought-action-observation log that can stretch dozens of steps, and reproducing the same path twice requires fixing the random seed at every call site.
The if/then version is easier to remember:
- If you stack more than three reasoning steps, expect latency to dominate user complaints.
- If your retrieval calls are cheap but generation is expensive, the agent’s decision to call retrieval again is your top-of-funnel cost driver — instrument it.
- If you copy a corrective pattern without measuring evaluator accuracy on your own data, you are not adding a safety net; you are adding a second source of error.
- If you cannot reconstruct the exact trajectory of a failed query, the agent is not in production yet, regardless of where its container is running.
Rule of thumb: budget for the case where every retrieval is called twice and every generation happens after a re-query — that is roughly the median behaviour of an under-tuned retrieval-augmented agent, not the worst case.
When it breaks: the most common production failure is not a hallucinated answer. It is a confidently wrong evaluator that decides the retrieval is good enough and short-circuits the corrective loop. The agent stops thinking and answers with full conviction.
Security & compatibility notes:
- LangChain Core serialization injection (CVE-2025-68664, “LangGrinch”): secret-extraction vulnerability. Patched in
langchain-core1.2.5 / 0.3.81 with breaking defaults —load()/loads()enforce an allowlist,secrets_from_env=False, and Jinja2 templates are blocked. Affects every retrieval-augmented-agent stack built on LangChain. Pin to the patched versions and re-audit any cached prompts loaded from disk.- LangChain path traversal (CVE-2026-34070): legacy
load_prompt()/load_prompt_from_config()are deprecated and scheduled for removal inlangchain2.0.0. Migrate prompt loading away from these entry points.- LangGraph 2.0 (Feb 2026): breaking change to
StateGraphinitialisation. Run thelangchain migrate langgraphCLI before treating any pre-2.0 tutorial as current.langgraph.prebuiltis deprecated; functionality moved tolangchain.agents.- LlamaIndex (March 2026): Python 3.9 support removed;
llama-index-workflowsbumped to 2.0 with breaking changes. Query Pipelines deprecated in favour of event-driven Workflows.
Not a panic. A compatibility budget. Build the stack assuming you will rev minor versions inside the year.
The Data Says
A retrieval-augmented agent is a controller, not a pipeline. Its job is to decide when to retrieve, what to re-query, and when to stop — and those decisions are what determine whether the system is fast, cheap, and reliable enough to put in front of users. The hardest production problem is not the model. It is the evaluator that grades the model’s own retrieval and quietly defines the ceiling of the whole stack.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors