From Perplexity to Few-Shot Prompting: Prerequisites for Understanding Evaluation Harness Internals
Table of Contents
ELI5
An evaluation harness runs standardized tests on language models, but interpreting the results requires understanding perplexity, few-shot prompting, and tokenization first.
A model scores 78.3 on a benchmark. Another scores 76.1. The first one is better — obviously. Except the scores used different numbers of few-shot examples, different tokenizers, different prompt templates. And one of the metrics was perplexity, which half the team couldn’t define under pressure. The 2.2-point gap might be noise shaped like a verdict.
The Measurement Stack Inside Every Leaderboard Rank
Before you can read an Evaluation Harness result with any precision, you need the vocabulary it assumes you already have. Not the vocabulary of the model being tested — the vocabulary of the test itself.
Model Evaluation frameworks don’t invent metrics from scratch. They inherit them from decades of machine learning research, then apply them to language models that behave nothing like the classifiers those metrics were designed for. That mismatch is where most misinterpretation begins.
What benchmarks and metrics should you understand before using an evaluation harness
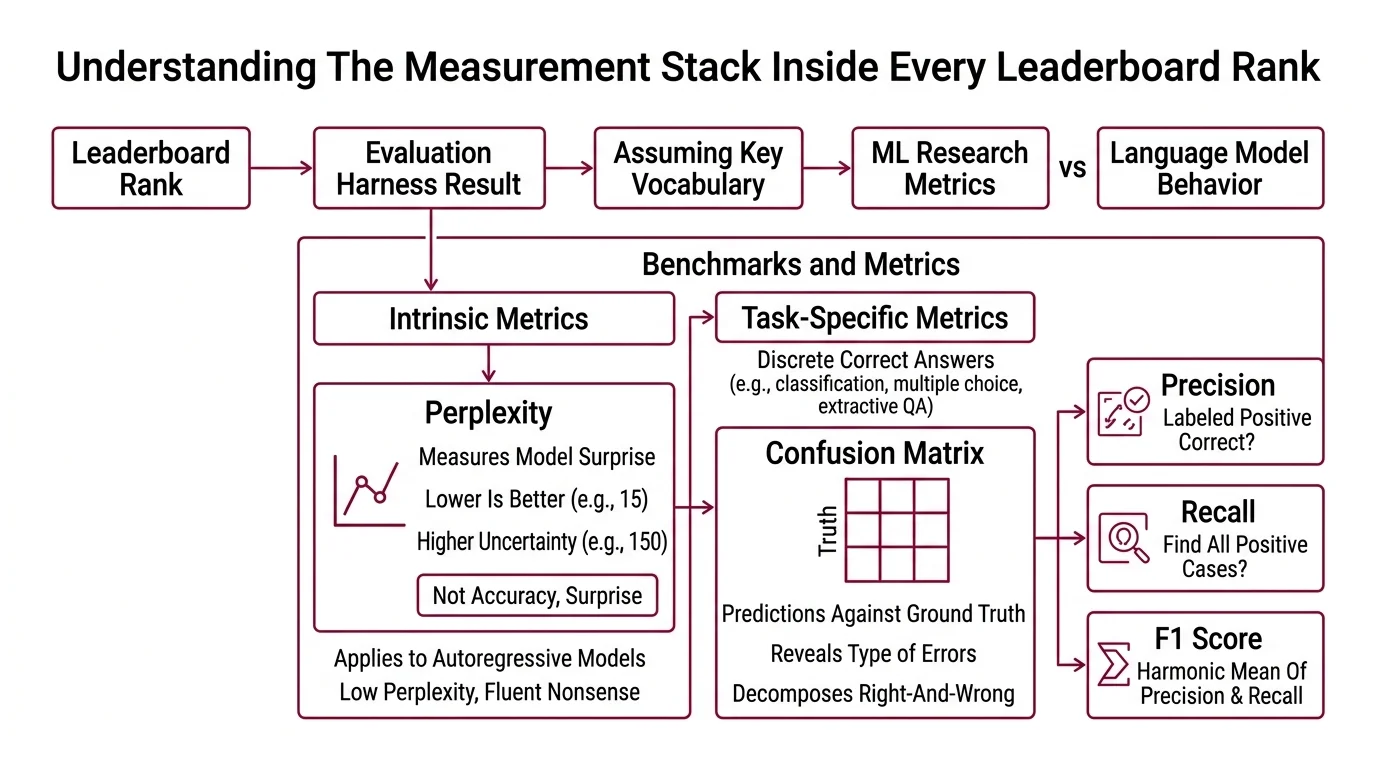
Start with Perplexity — the metric that sounds philosophical but behaves mathematically. Perplexity measures how surprised a language model is by a sequence of tokens. Lower is better: a perplexity of 15 means the model behaves, on average, as if it’s choosing among 15 equally likely next tokens. A perplexity of 150 means uncertainty is an order of magnitude higher.
The catch: perplexity applies primarily to autoregressive language models, and it tells you nothing about whether the model’s confident predictions are correct in any task-specific sense. A model can have low perplexity — high confidence, low surprise — while consistently generating fluent nonsense.
Not accuracy. Surprise.
Perplexity measures the distribution fit, not the usefulness of the output.
For tasks with discrete correct answers — classification, multiple choice, extractive QA — you need metrics that decompose right-and-wrong into something more diagnostic. A Confusion Matrix maps predictions against ground truth across all classes, revealing not just whether the model erred but how: did it confuse category A with category B? Did it miss rare classes entirely?
From the confusion matrix, you derive Precision, Recall, and F1 Score: precision asks “of the things you labeled positive, how many actually were?” Recall asks “of all the actual positives, how many did you find?” F1 balances the two. The metric you choose determines what kind of failure you’ll notice — and what kind you won’t.
Evaluation harnesses like EleutherAI’s lm-evaluation-harness — currently at v0.4.11 and supporting over 60 standard academic benchmarks (EleutherAI GitHub) — automate the scoring pipeline. But they don’t choose which metric matters for your use case. That judgment stays with you.
The frameworks differ in what they choose to measure. Helm Benchmark evaluates models across seven dimensions — accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency (Stanford HELM) — treating evaluation as a multi-axis problem rather than a single ranking. OpenCompass covers over 100 datasets across a wide range of models (OpenCompass GitHub). The Open LLM Leaderboard, which evaluated over 13,000 models and drew more than two million unique visitors, is now winding down — community-driven alternatives are stepping in (Hugging Face).
Each framework encodes assumptions about what “good” means. A leaderboard that ranks by accuracy alone will surface different winners than one that penalizes toxicity or measures calibration. The benchmark is never neutral; it reflects someone’s decision about which failures matter most.
How Few-Shot Examples Reshape the Exam
Evaluation doesn’t happen in isolation. The prompt an evaluation harness sends to the model carries formatting cues, structural context, and sometimes solved demonstrations that fundamentally alter the measurement. Change the number of demonstrations, and you change what the score reflects.
What is few-shot evaluation and how do evaluation harnesses use it to score models
Zero-shot evaluation gives the model a task with no examples. The result tells you what the model can do based purely on patterns internalized during pretraining — its prior distribution over plausible completions. It’s the baseline: raw capability, unassisted.
Few-shot evaluation shifts the ground. You prepend a handful of solved examples to the prompt — typically between one and five — and the model conditions its response on those demonstrations. No weight updates. No fine-tuning. You’ve changed the model’s posterior by reshaping the context it attends to.
Think of it as the difference between asking someone to translate a sentence into a language they’ve studied, versus showing them three correct translations first and then asking. The underlying knowledge doesn’t change. The activation pattern does.
Not teaching. Conditioning.
This matters for harnesses because the number of few-shot examples is a configurable parameter, not a universal standard. EleutherAI’s lm-evaluation-harness uses YAML-based task configurations with Jinja2 prompt templates, where few-shot settings can be adjusted per benchmark (EleutherAI GitHub). A model that scores 82% with five-shot prompting might score 71% zero-shot — and both numbers are “correct” within their respective setups.
The implication is uncomfortable: benchmark scores without stated few-shot counts are incomplete. A leaderboard that doesn’t report whether results used 0-shot, 3-shot, or 5-shot evaluation is leaving out a critical variable — allowing scores to look comparable when they aren’t.
Larger models tend to benefit more from few-shot demonstrations, an observation consistent with the original findings from Brown et al. (2020). Smaller models sometimes degrade with additional examples, as the demonstrations consume context window capacity without providing sufficient signal. The few-shot count is not a dial you turn up for better results; it’s an interaction between model capacity, context length, and task complexity — and that interaction varies in ways that no single leaderboard column captures.
The Tokenizer as Hidden Variable
Two models receive identical evaluation prompts. The text is the same, character for character. But identical text does not mean identical input — because every model sees the prompt through a different lens. Tokenization is the transformation step that most benchmark discussions skip over, and it introduces more variance than most teams suspect.
How do evaluation harnesses handle tokenization and prompt format differences across models
Every language model operates on tokens, not characters or words. A tokenizer converts raw text into a sequence of integer IDs drawn from a model-specific vocabulary. Different models use different tokenizers — BPE, SentencePiece, custom unigram variants — each with a different vocabulary size, different subword boundaries, and different handling of whitespace and special characters.
When an evaluation harness sends the same prompt string to two different models, each model’s tokenizer produces a different token sequence. The word “evaluation” might be a single token for one model and two subword tokens for another. A prompt that fits within one model’s context window might overflow another’s — not because the model is less capable, but because its tokenizer is less efficient for that particular text.
This is not a theoretical concern. Prompt template formatting — how the question is phrased, where newlines fall, whether answer choices are labeled (A), (B), (C) or 1., 2., 3. — interacts with the tokenizer to produce different token boundaries, which feed into different attention patterns, which produce different probability distributions over candidate answers. The “same” question, tokenized differently, becomes a subtly different question.
Modern evaluation harnesses address this with a tokenization-agnostic interface (EleutherAI GitHub) — abstracting the tokenizer behind a common API so that each model receives correctly tokenized input without manual intervention. But “correctly tokenized” and “equivalently tokenized” are not the same thing. The harness ensures each model processes valid input for its architecture; it does not guarantee that the resulting token sequences are semantically equivalent at the representation level.
Prompt format sensitivity is the gap between what the benchmark intends to measure and what it actually measures. A model might underperform on a multiple-choice benchmark not because it lacks the knowledge, but because its tokenizer splits the answer labels in a way that disrupts the expected probability distribution over choices.
Compatibility notes:
- lm-evaluation-harness v0.4.10+: The base package no longer installs HuggingFace or PyTorch by default. Install backend dependencies explicitly (e.g.,
pip install lm-eval[hf]).- Python 3.8: Support dropped in lm-evaluation-harness. Requires Python 3.9+.
- Open LLM Leaderboard: Officially retiring. Community-maintained leaderboards are replacing it as the primary public ranking system.
What These Dependencies Predict
If you treat benchmark scores as absolute rankings, you’ll draw wrong conclusions about model capability. The score is an interaction between the model, the metric, the prompt template, the few-shot count, the tokenizer, and — often overlooked — the Benchmark Contamination risk that the model saw test data during training.
Change the few-shot count, and expect ranking shifts. Change the prompt format, and expect variance that has nothing to do with model knowledge. If two models use radically different tokenizers, their scores on the same benchmark are not directly comparable without careful normalization.
Rule of thumb: Before comparing two benchmark scores, verify they used the same few-shot count, the same prompt template, and account for tokenizer differences. If any of these differ, the comparison is between experimental setups, not between models.
When it breaks: Evaluation harness results become misleading when teams treat them as single-number summaries — ignoring the metric chosen, the few-shot configuration, and the tokenizer interaction. The failure mode is not wrong scores; it’s correct scores interpreted without their measurement context.
The Data Says
Every benchmark score carries hidden dependencies — perplexity assumes autoregressive generation, few-shot counts reshape what the model can access during evaluation, and tokenizer differences mean “the same prompt” is rarely the same input. Understanding these prerequisites is the difference between reading a leaderboard and understanding what it measured.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors