From Overfitting to N-Gram Overlap: Prerequisites and Hard Limits of Detecting Benchmark Contamination

Table of Contents
ELI5
Benchmark contamination means a model already saw the test answers during training. Overfitting is the visible effect; leaked data is the hidden cause. Every detection method misses a different slice of the problem.
GPT-4o scores 88.0% on the MMLU Benchmark. Then someone rephrases the same questions — shuffles the answer options, rewrites the stems — and the score drops to 73.4% (Zhao et al.). A 14.6-percentage-point gap that looks like a smoking gun. But the gap conflates two signals: actual contamination and difficulty changes introduced by the rephrasing itself. With current detection methods, separating those signals is the problem nobody has solved.
This is the prerequisite puzzle. Before you can detect Benchmark Contamination, you need to understand why the tools designed to catch it each fail in a different direction — and why the concepts underneath (overfitting, deduplication, n-gram matching) constrain every approach from the start.
The Cause-Effect Confusion That Detection Must Untangle
Most discussions of contamination jump straight to the detection method. That is backwards. The detection problem is downstream of a conceptual ambiguity between two terms everyone assumes they understand — and that ambiguity explains why no single method works.
What is the difference between overfitting and benchmark contamination?
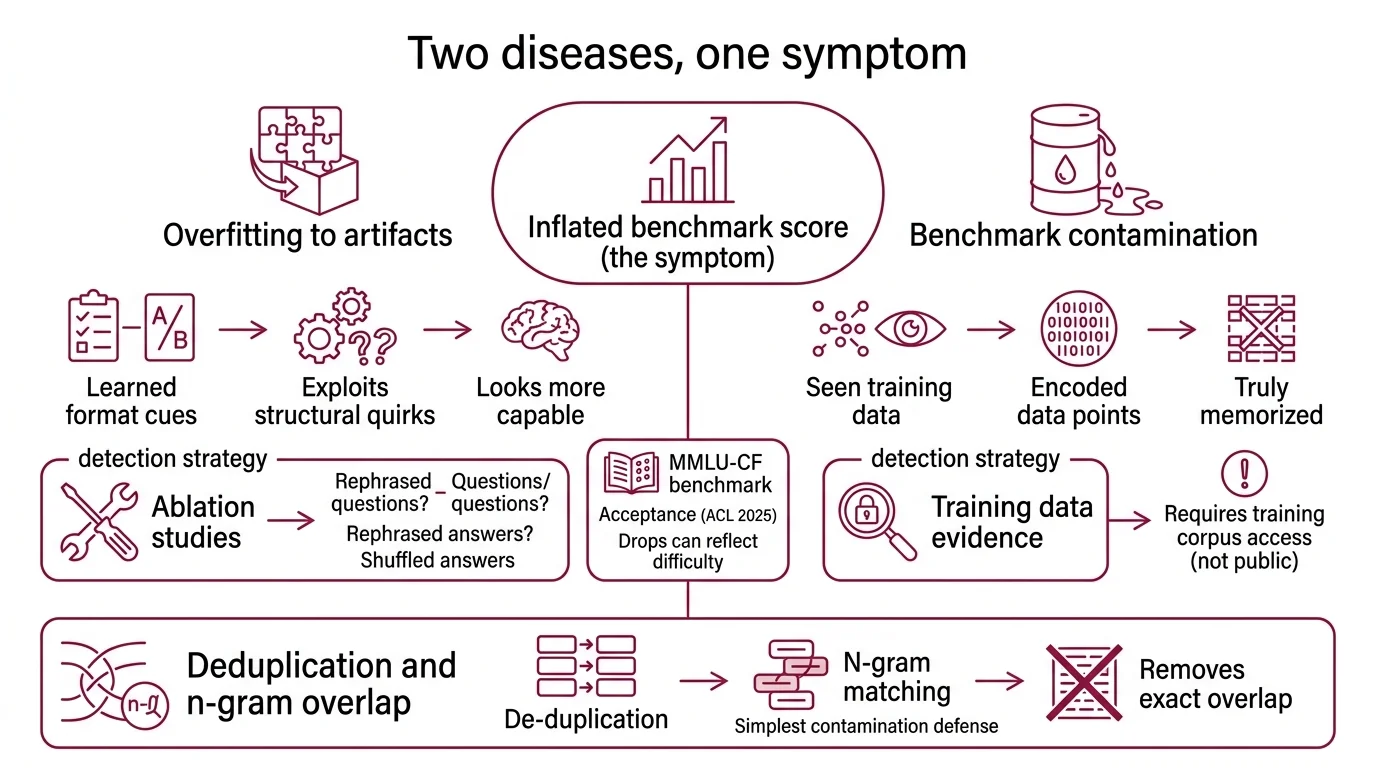
Overfitting is a behavior: the model fits training data so tightly that it loses the ability to generalize. It shows up as a gap between training accuracy and test accuracy. Benchmark contamination is a cause: benchmark data — questions, answers, context passages — leaked into the training set. Contamination can produce overfitting, but overfitting has broader origins: insufficient regularization, architecture mismatch, poorly tuned hyperparameters.
The distinction matters because they look identical in the one metric most people check — the benchmark score. A model that memorized MMLU answers and a model that genuinely generalized to the same distribution both produce impressive numbers. The difference surfaces only when you perturb the input: rephrase questions, shuffle answer positions, test on semantically equivalent but syntactically different problems.
Not a capability deficit. A data leak.
Think of it like a medical diagnostic. The symptom (high score) is shared by two conditions (genuine capability and memorization). You need a differential test that separates them — and that is exactly what detection methods attempt. Frame it through the Confusion Matrix: every detection method trades false positives against false negatives, and no current method minimizes both.
How do data deduplication and n-gram overlap detection relate to benchmark contamination?
Data Deduplication is the prevention layer. Remove benchmark data from the training corpus before training begins, and contamination cannot occur. The standard approach uses n-gram overlap: flag any training document that shares an n-gram sequence above a threshold length with a benchmark item.
The thresholds vary dramatically across model families. GPT-2 used 8-gram word overlap; GPT-3 raised the bar to 13-gram; GPT-4 shifted to 50-character substring matching (Ravaut et al. Survey). PaLM uses 8-gram words but flags a sample only at 70% n-gram coverage. Llama-2 introduced skip-gram matching with up to 4 mismatches; Llama-3 returned to a simpler 8-gram token threshold.
These are not arbitrary decisions. Each reflects a tension between catching contamination and preserving useful training data. The C4 corpus — among the most widely used pretraining datasets — contained 1.68% near-duplicates when analyzed in 2021, with one sentence repeated over 60,000 times (Lee et al.). Models trained on deduplicated data emitted memorized text ten times less frequently. The effect is real: deduplication works as prevention. But it works only against verbatim and near-verbatim matches.
A model trained on paraphrased MMLU questions — same knowledge, different surface form — reached 85.9% accuracy while remaining invisible to standard n-gram detectors (Xu et al. Survey).
The n-gram filter caught the echo but missed the reverberation.
The Detection Wall Where Scale Defeats Pattern Matching
The detection problem compounds at web scale. Over 50 techniques have been catalogued across more than 100 papers as of early 2025 (Ravaut et al. Survey). Despite that volume of research, the field has not converged on a reliable method — and the reasons are structural, not just incremental.
Why is benchmark contamination so hard to detect in web-scale pretraining data?
Three forces conspire against reliable detection at scale.
First, the surface-form problem. N-gram matching catches verbatim and near-verbatim overlap. It fails against what recent work calls “soft contamination” — semantically equivalent content with different wording. A preprint by Spiesberger et al. found semantic duplicates of benchmark items in training data at startling rates: 100% of MBPP (a code benchmark), 77.5% of CodeForces problems, and 50% of ZebraLogic tasks. Finetuning on these semantic duplicates produced roughly 20% performance gains — shallow generalization masquerading as genuine capability. (This result comes from a 2026 preprint not yet confirmed at a top venue.)
Second, the black-box problem. When training data is not publicly available — as with most frontier models — open-data methods (string matching, embedding similarity) cannot apply. Black-box approaches must infer contamination from model behavior alone: membership inference attacks, confidence analysis, memorization probing. But membership inference attacks achieve an ROC-AUC below 0.6 across attack types — barely above random guessing (Ravaut et al. Survey). Min-K% Prob, one of the stronger black-box signals, averages an ROC-AUC of 0.72 on WikiMIA, though performance varies significantly across domains. In Precision, Recall, and F1 Score terms: mediocre recall, unstable precision.
Third, the reasoning-model problem. GRPO training — used in reasoning-focused models — can conceal the statistical signals that most black-box detection methods rely on. When the training process itself reshapes the probability distributions detectors measure, the detector is aiming at a target that moved during training.
Does moderate benchmark contamination get forgotten at Chinchilla-optimal training scale?
Here the story turns counterintuitive. Bordt et al. examined what happens when contaminated data appears in training but the model continues through enough additional data. At Chinchilla-optimal compute allocation and beyond, moderate contamination fades.
The mechanism is weight decay. As training continues past the contaminated segment, the regularization term in the optimizer gradually erases the parameter adjustments caused by memorization. At five times Chinchilla-optimal data scale, even 144-fold repeated contamination is forgotten (Bordt et al.).
But “forgotten” requires precision. For a 774-million parameter model with single contamination exposure, the overfitting effect was approximately 3 percentage points — notable but not catastrophic. Increase repetition to four times, and the effect jumps to 15-20 percentage points depending on model size. OLMo-7B showed a 17-percentage-point initial accuracy boost from contamination that declined to approximately 2 percentage points after 13% additional training (Bordt et al.).
The practical implication for Model Evaluation: if a model trained at or beyond Chinchilla-optimal scale encountered contamination incidentally, the residual inflation is likely small. If the contamination was systematic — scraped benchmark answers appearing repeatedly across the corpus — the inflation persists unless post-contamination training volume is enormous.
What the Detection Blind Spots Predict
Map the detection methods onto the contamination taxonomy — semantic, information, data, and label contamination, ordered from hardest to easiest to detect (Xu et al. Survey) — and a pattern emerges. Current tools handle the easy end: verbatim overlap, exact-match deduplication, label leakage. The hard end — semantic contamination, training-process masking — remains largely opaque.
If you are evaluating a model using MMLU scores alone, treat the number as an upper bound, not a point estimate. MMLU carries a ~6.5% question error rate (Wikipedia), and its scores have saturated in the 88-93% range for frontier models — a ceiling that makes contamination effects proportionally harder to separate from genuine capability. Newer benchmarks like MMLU-Pro (12,000 graduate-level questions, 10 answer options, 16-33 percentage points harder than original MMLU) attempt to restore discriminative power, but each new benchmark inherits the same vulnerability: its questions eventually appear in training corpora.
An Ablation Study of detection methods reveals the same shape as any diagnostic problem: strict thresholds reduce false positives but increase false negatives; loose thresholds catch more contamination but flag benign overlap. No single threshold eliminates both errors. The practical consequence is layered detection — n-gram overlap for verbatim matches, embedding similarity for paraphrases, behavioral probes for black-box models — with each layer covering a blind spot of the previous one.
Rule of thumb: If a model’s score on a rephrased benchmark drops more than 10 percentage points, treat contamination as a contributing hypothesis — not a confirmed diagnosis. The drop may partly reflect difficulty changes introduced by rephrasing.
When it breaks: Detection fails most completely against deliberate contamination in closed-training regimes — where the training data is inaccessible, the contamination is paraphrased rather than verbatim, and reasoning-model training obscures the behavioral signals that black-box methods depend on. In that scenario, no existing method reliably separates memorization from capability.
The Data Says
Benchmark contamination detection is a diagnostic problem with the same structure as any confusion-matrix trade-off: every method sacrifices recall for precision or the reverse, and no current approach achieves both. The prerequisite concepts — overfitting as effect versus contamination as cause, n-gram overlap as a string-level filter that misses semantic duplicates, weight decay as a natural forgetting mechanism — define the boundaries that any future detection method will operate within. Understanding these boundaries is where evaluation literacy begins.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors