OCR to Layout-Aware Models: Prerequisites and Hard Limits
Table of Contents
ELI5
Document parsing turns a PDF into structured data a model can read. It needs three layers — character recognition, layout analysis, structured output — and each layer has predictable failure modes around tables, formulas, and handwriting.
A PDF feels like a document. It opens in a viewer, you read it top to bottom, the columns wrap correctly, the table aligns. The mental model is text. The reality is graphics — a stream of glyph-placement instructions floating in 2D space, with no concept of “paragraph,” “row,” or “reading order.” Every document parser exists to undo that fact, and every limitation of Document Parsing And Extraction traces back to the moment the visual abstraction stops being lossless.
The Three Layers Every Parser Has to Reconstruct
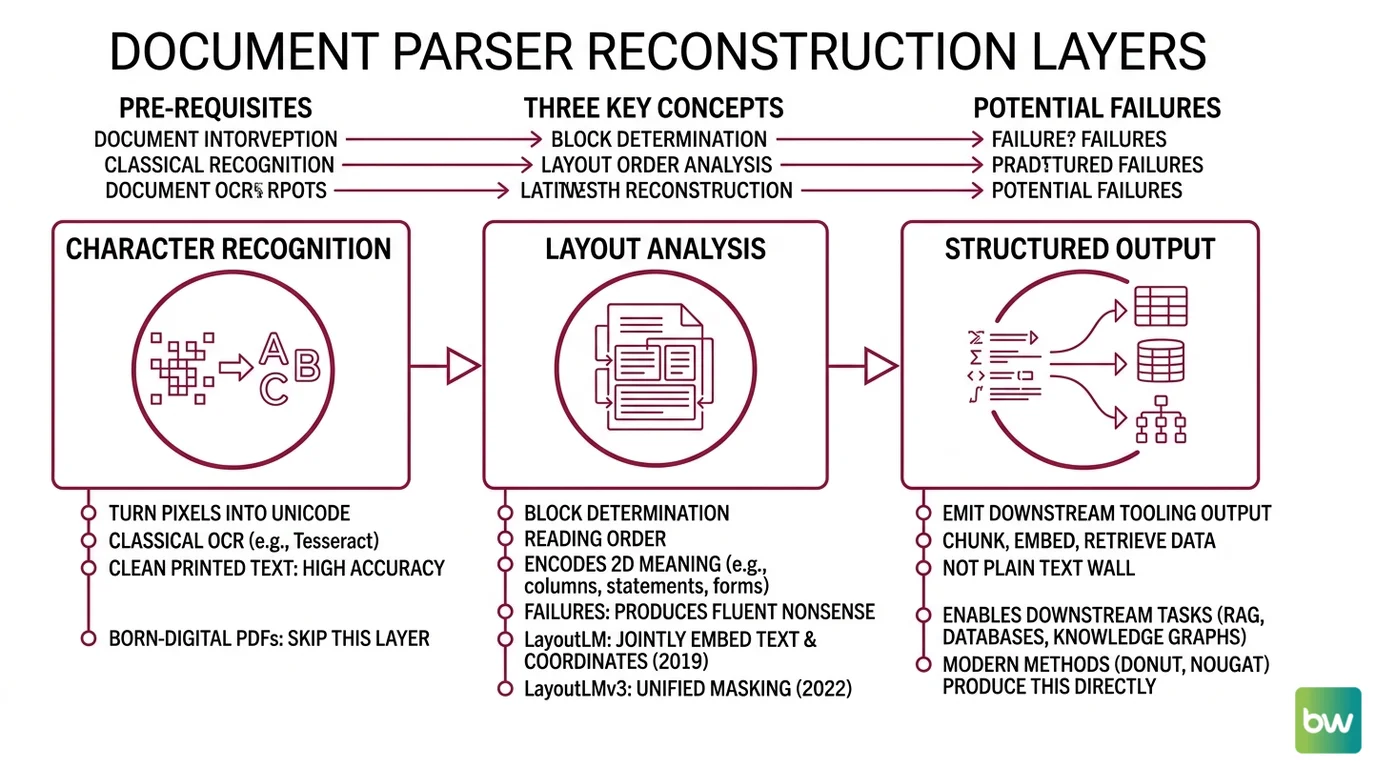
Before any modern method makes sense — OCR, LayoutLM, Donut, Nougat, the current generation of vision-language models — the reader needs to know what these systems are actually trying to recover. The pipeline has three layers, and a method either solves them sequentially or end-to-end, but it never skips them.
What do you need to understand before learning document parsing?
Three concepts. They map to three different things that can go wrong, which is the only reason the taxonomy matters.
The first is character recognition: turning pixels into Unicode. This is what classical OCR does — Tesseract is the canonical open-source example, and on clean printed text it reaches 98–99% accuracy (Koncile). For born-digital PDFs you skip this layer entirely; the glyphs are already encoded. The temptation is to treat character recognition as solved. It mostly is, on the inputs it was designed for. The trouble starts the moment the input drifts: scans at low DPI, faded receipts, multi-language pages, or anything cursive.
The second is layout analysis: deciding which characters belong to which block, in what reading order. This is the hidden layer most people don’t realize exists. A two-column academic paper, a financial statement with footnotes, a form with floating labels — these all encode meaning in 2D position, not in token order. A parser that recovers perfect characters in the wrong order produces fluent nonsense. LayoutLM, introduced in late 2019, was the first model to jointly embed text content and 2D coordinates so the language model itself could attend to position (arXiv). LayoutLMv3 generalized that idea further by unifying text and image masking in 2022 (arXiv). Layout-aware is the layer where most pipeline failures actually originate — not a bonus feature.
The third is structured output: emitting something downstream tooling can chunk, embed, and retrieve. A wall of plain text is not structured output. JSON with {role: "title", text: ..., bbox: ...} or markdown with preserved table syntax is. This layer is what makes a parsed document useful to a
Knowledge Graphs For RAG pipeline or a vector index — without it, you embed paragraph soup and wonder why retrieval is incoherent.
How the methods divide along those layers
The whole field splits cleanly into two architectural bets.
Pipeline approach — run OCR first, then a separate model for layout, then a third for structure. Each stage is debuggable in isolation. Tools like Docling (originally from IBM Research Zurich, now under LF AI & Data, with over 37,000 GitHub stars per Docling Docs) and Unstructured (around 14,600 stars per Firecrawl) sit in this camp. The cost is error compounding: an OCR mistake at stage one corrupts everything downstream, and stages cannot recover information the previous stage discarded.
End-to-end approach — feed the page image directly to a vision-language model that emits structured output in one pass. Donut was the first widely-adopted OCR-free model in this category (Hugging Face). Nougat extended it to academic PDFs, including LaTeX math (arXiv). The current generation — PaddleOCR-VL, GLM-OCR, Granite-Docling-258M — pushes the same idea with more capable backbones. The cost is opacity: when extraction fails, you cannot point at a stage; the model simply hallucinated a row or skipped a column.
Neither bet is universally correct. The choice depends on which failure modes you can tolerate, which is the next thing to understand.
Where Document Parsing Still Breaks
Modern vision-language models have made earlier “hard limits” look soft. As of early 2026, GLM-OCR scores 94.6% on OmniDocBench v1.5 and PaddleOCR-VL 1.5 reaches 94.5% with only 0.9 billion parameters (Hugging Face). The benchmark itself has been declared saturated (LlamaIndex). This is real progress. It is also a lure — average accuracy hides where the residual errors concentrate, and the residuals are not random.
What are the technical limitations of document parsing for tables, formulas, and scanned PDFs?
Three failure clusters dominate, and they share a common cause: each requires the model to recover information that is not actually present in the local pixel neighborhood.
Tables with merged cells, invisible borders, or nested headers. A human reads a financial statement by treating an empty cell as “same as above,” interpreting a centered span across three columns as a header, and following alignment more than rules. Classical OCR-plus-layout pipelines reach as low as 40% accuracy on difficult tables (Ramamtech) — not because the characters are illegible, but because the cell structure is implied rather than drawn. Modern LLM-based extraction is dramatically better here; Gemini 2.5 Pro reaches near-perfect extraction on financial PDFs (Vellum). But “near-perfect on this benchmark class” is not “solved everywhere.” Tables that mix row-spanning headers with footnote markers and parenthetical units still produce silent errors — silent meaning the output looks plausible until you check it against the source.
Mathematical formulas. A formula encodes a tree of relations — superscripts, subscripts, fractions, summation bounds — using spatial position. Linearizing it requires recovering the tree, not just the symbols. GROBID, a strong baseline pipeline tool, scores under 11% on mathematical formulas; Nougat raised that to roughly 75% by training on academic PDFs end-to-end (Nougat paper). The continuous text in the same papers reaches over 91% BLEU and over 96% accuracy. The gap between 96% on prose and 75% on formulas is not a bug to fix later. It reflects that prose is locally generative — the next token is mostly determined by the previous few — while formulas are globally structural.
Scanned and handwritten content. Born-digital PDFs hand the parser a vector representation. Scans hand it a noisy raster. Tesseract drops from 98–99% on clean printed text to 90–95% on scanned PDFs, 70–85% on complex layouts, and 50–80% on handwriting (Koncile). The handwriting figures are illustrative rather than definitive — they come from a secondary source — but the direction is unambiguous: cursive, angled scans, low DPI, and bleed-through compound multiplicatively, not additively. Tesseract v4+ shipped no human-handwritten training data (Extend), which means the open-source default has a structural blind spot rather than a tunable one.
Notice that all three failure modes share a property: they are cases where 2D structure carries semantic load that cannot be recovered from local features. That is not a coincidence.
What These Limits Predict for Your Pipeline
The mechanism gives you a small number of useful predictions. They turn the abstract “OCR has limits” into something you can act on.
- If your corpus is born-digital prose with simple layout, every modern parser will work. The differences between them — Docling, Unstructured, LlamaParse, the VLM-based options — show up in latency, deployment cost, and post-processing convenience, not in extraction quality.
- If your corpus contains complex tables, expect silent errors regardless of which parser you choose. Build a downstream validation step that checks row counts and column-sum totals where applicable. The parser’s confidence score will not flag the structural mistakes.
- If your corpus contains formulas, prefer end-to-end models trained on documents structurally similar to yours (Nougat for academic PDFs, for example). A pipeline approach will discard the spatial information before the formula extractor sees it.
- If your corpus contains scans, separate them from born-digital documents in your ingest queue. They need higher-tolerance parsing, more aggressive validation, and probably a human-in-the-loop step. Mixing them with clean inputs hides the failure rate.
- If extracted data feeds a knowledge graph or a ScaNN-style nearest-neighbor index, parser quality propagates downstream as retrieval noise. A 95% extraction accuracy looks fine in isolation and looks catastrophic after three more lossy stages.
Rule of thumb: the parser’s average accuracy lies; what matters is the failure rate on your worst document class.
When it breaks: the dominant production failure is not catastrophic OCR garbage — it is silent structural corruption in tables, formulas, and complex multi-column layouts, where the output is fluent and confidently wrong. No current model reliably surfaces this class of error through its own confidence signal, which means downstream validation is not optional.
The Real Lesson From the Benchmark Saturation
OmniDocBench v1 saturating at over 94% does not mean document parsing is solved. It means the benchmark stopped distinguishing between models on the document classes it covers (LlamaIndex). The interesting question shifted: not “which model has the highest score” but “which model fails most predictably on the documents you actually have.” Predictable failure is more valuable than slightly higher average accuracy, because predictable failure is something you can wrap with validation. Unpredictable near-perfection is something you can only audit by hand.
The Data Says
Document parsing is three reconstruction problems stacked on top of each other — characters, layout, structure — and modern vision-language models solve the first two well enough that the bottleneck has moved to the third. The remaining hard limits cluster around 2D structure carrying semantic load: merged-cell tables, mathematical formulas, and scans. None of these will be fixed by another two points of average benchmark score.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors