Prerequisites and Technical Limits of HITL for AI Agents
Table of Contents
ELI5
Human-in-the-loop for agents pauses an autonomous workflow at a designated checkpoint, hands a decision to a person, and resumes from saved state. The hard part is not the pause — it is keeping the human awake, accurate, and accountable when the pause arrives at three in the morning.
Engineers approaching their first Human In The Loop For Agents design tend to picture it like a code review: the agent does work, a human glances at the result, says yes or no, and the agent continues. Clean, synchronous, polite. That mental model survives until the first production incident — when the approver is on a flight, the agent has already issued half a refund, and the resumed workflow re-runs the side effect because the framework restarts the entire node from the beginning. The pause was the easy part. Everything around the pause is the protocol you forgot to design.
The Pause Is a Primitive, Not a Protocol
Every modern agent framework now ships some version of “stop here and ask a human.” The function call is a primitive. The protocol — what state survives the pause, who sees the request, how long the wait can last, what happens on timeout, what becomes idempotent before and after — is not in the framework. It is your design problem.
To see why, look at how five orchestrators express the same idea, and notice how much each one leaves to the caller.
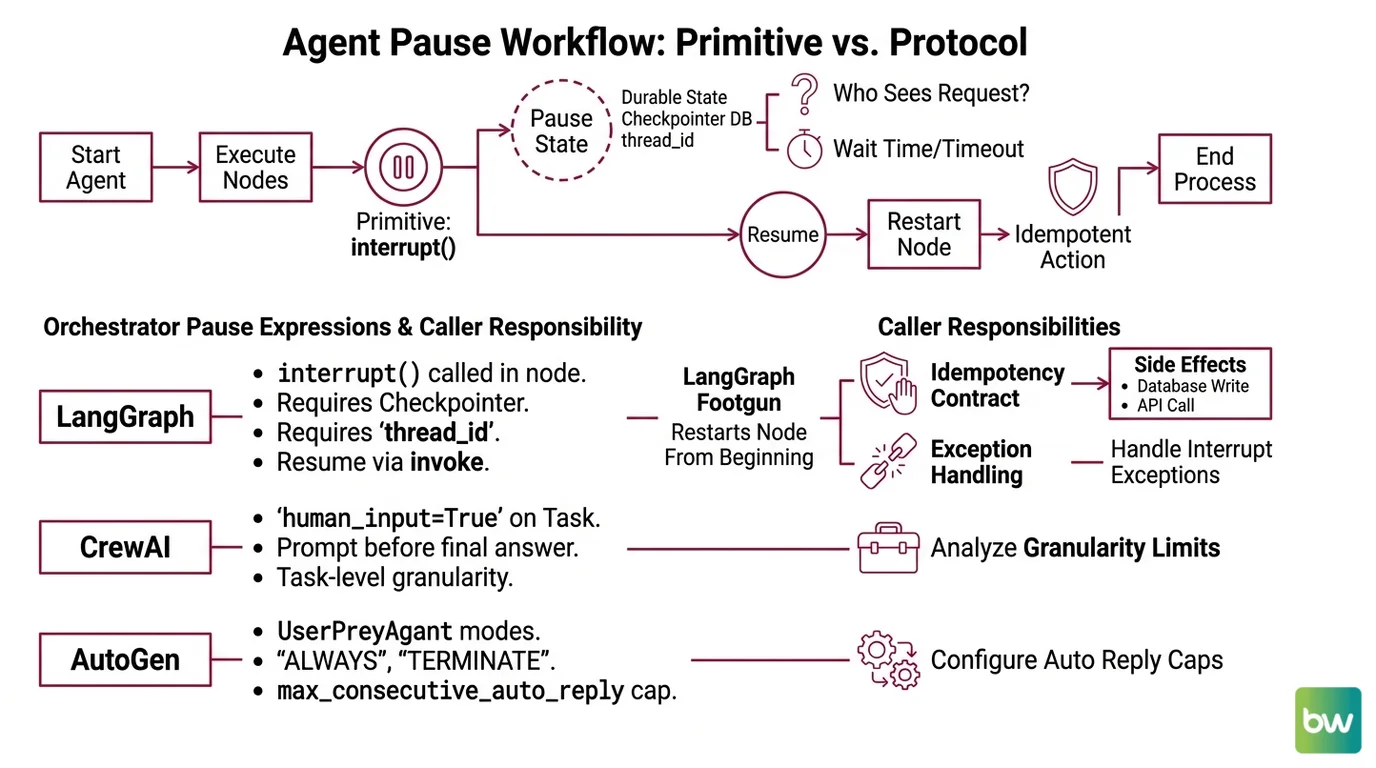
In LangGraph, the pause is interrupt(), called inside a graph node. It requires a checkpointer — durable, database-backed in production — and a thread_id in the run config so state can be reloaded later. To resume, the caller invokes graph.invoke(Command(resume=value), config=config), and the value passed in becomes the return of the original interrupt() call (LangChain Docs).
That sounds clean. There is a footgun.
When a LangGraph node resumes after interrupt(), the runtime restarts the entire node from the beginning. It does not pick up at the line where the pause happened. Any side effect that ran before the interrupt — a write to a database, an outbound API call, a charge on a card — runs again on resume. Wrap interrupt() in try/except and the exception path swallows the interrupt and breaks the flow entirely (LangChain Docs).
The pause primitive is the documented part. The idempotency contract is the unwritten one.
CrewAI pushes the same idea up a layer. Setting human_input=True on a Task tells the agent to prompt the user before delivering its final answer. The granularity is task-level, not arbitrary inside a tool call, which is simpler to reason about — but it also means you cannot pause mid-tool to confirm a destructive parameter.
AutoGen frames it conversationally. A UserProxyAgent accepts a human_input_mode of "ALWAYS", "TERMINATE", or "NEVER", and a max_consecutive_auto_reply cap that limits autonomous turns when the mode is not ALWAYS. The control surface is dialogue, not workflow state, so the question “what has already happened in the world?” is not part of the abstraction — it is up to the caller’s tool implementations.
OpenAI’s Agents SDK exposes the smallest unit: configure a tool with needsApproval: true and the run pauses until the caller approves or rejects, then resumes from saved state rather than starting a new turn. Streaming pauses too. The official guidance is to start with tool-level approvals on the highest-risk tools and to skip approvals on internal, low-risk, easily reversible actions — reads, drafts, calculations (OpenAI Agents SDK Docs).
Temporal sits underneath all of these as a substrate. A workflow waits on a Signal for the human decision; while it waits, it is in “Running” state but consumes no compute, and durable timers enforce time limits that survive process crashes. When your HITL step might wait hours or days — a manager review, an overnight queue, a regulator’s response — the question shifts from “how do I pause” to “how do I keep the pause alive across deployments and restarts.”
What do you need to understand before designing human-in-the-loop agent systems?
Step back from the APIs and the prerequisites become visible. They are the same questions across all five frameworks.
Durable state. Every pause needs a place to store what the agent already decided. If the checkpointer is in-memory, a process restart loses the loop. The minimum viable HITL stack has a durable store — Postgres, Redis with persistence, Temporal’s event history — keyed by a workflow identifier the human side can also resolve.
Idempotency before the pause. Whatever runs in the same atomic unit as the pause may run again. In LangGraph, the entire node re-executes on resume. In Temporal, retries are explicit. In AutoGen, the tool may simply be called again on the next conversational turn. The rule is structural: any side effect emitted before a pause must be safe to repeat. Use idempotency keys, conditional writes, or move the side effect to after the human’s decision.
Granularity choice. Tool-level approvals (OpenAI) are precise and noisy. Task-level approvals (CrewAI) are coarse and quiet. Node-level approvals (LangGraph) sit in between. The right granularity is whichever one matches the unit of action a human can meaningfully evaluate — not the unit the framework finds convenient.
Escalation policy as design pattern. No framework hands you an escalation protocol; it is a set of rules you write. Who gets the request first? With what context payload? After what timeout does it route to a second approver, a different role, or a default-deny? What audit trail does each transition produce? Treat this as a state machine you specify alongside the agent graph, not an afterthought (Caution: “escalation policy” is not a standardized concept — it is a pattern you compose).
Authentication and authorization for the approver. The pause primitive does not know who is allowed to say yes. That is your application’s job. The same agent might require a customer-service rep for refunds under a threshold and a compliance officer above it. Agent Guardrails can enforce the routing; the orchestrator only suspends the run.
A test harness for the loop, not just the agent. Agent Evaluation And Testing of an HITL flow has to exercise the pause path: timeout fallbacks, double-resume attempts, approver mismatch, network partition during signal delivery. The agent is one component. The loop is the system.
The Vigilance Tax: Why Human Oversight Has a Ceiling
The pause primitive is mechanical. The human on the other end is not. And that asymmetry is where the technical limits stop being about frameworks and start being about people — measured, repeatedly, for forty years.
What are the technical limitations of human-in-the-loop oversight in agent systems?
Five intersecting limits define the ceiling of any HITL system. None of them are solved by a better orchestrator.
The oldest finding sits in Lisanne Bainbridge’s 1983 paper, Ironies of Automation. Her formulation: “It is impossible for even a highly motivated human being to maintain effective visual attention towards a source of information on which very little happens for more than about half an hour” (Bainbridge 1983). Her larger thesis cuts deeper. Automating most of the work leaves the human operator with the messiest residue — the ambiguous, demanding, least-supported moments — at exactly the point where skill decay from lack of practice is greatest. Every modern HITL deployment recapitulates this argument. Vigilance has a ceiling, and the design of the loop pushes the human against it.
Layered on top is automation bias. Systematic reviews of human–AI collaboration find consistent over-reliance on machine recommendations even when they are noticeably wrong, with the effect amplified in high-stakes domains like health, law, and public administration. For LLM-based agents the problem is sharper. As one recent survey put it, “measuring and mitigating overreliance must become a central focus in LLM research and deployment” — the conversational fluency and complex outputs of LLMs complicate the interventions that worked for older predictive systems (arXiv 2509.08010).
The third limit is throughput. Even when humans want to review carefully, the queue eventually wins. In adjacent domains we already have data: 82% of SOC analysts surveyed worry they may be missing real incidents under existing alert volume (ACM Computing Surveys). Industry coverage of AI oversight roles describes the same pattern in a different vocabulary — “AI brain fry,” with monitors making noticeably more errors as oversight intensity rises.
The fourth limit is regulatory and structural. EU AI Act Article 14 specifies that human overseers of high-risk AI must be able to (1) understand the system’s capacities and limitations, (2) remain aware of automation bias, (3) correctly interpret output, and (4) decide to disregard, override, or reverse it via an effective stop control (EU AI Act). Article 14 also imposes a four-eyes rule on remote biometric identification — verification by at least two competent persons before action, with narrow law-enforcement exceptions. These are not features your framework provides. They are capabilities the design must produce in the human, by training, interface, and workload.
The fifth limit is the one LangGraph documentation embeds quietly in a warning box: re-execution semantics. A human who approves an action does not always know what state the system is already in. If the surrounding node ran a side effect before the interrupt, “yes” can mean two writes, not one. The technical limit and the cognitive limit meet here — the human is asked to authorise something whose past the orchestrator has not fully shown them.
Compatibility note:
- LangGraph
interrupt()re-execution: When a graph resumes viaCommand(resume=value), the entire node restarts from its first line — not from whereinterrupt()was called. Make every pre-interrupt side effect idempotent, and never wrapinterrupt()intry/except(LangChain Docs).
What the Mechanism Predicts
If the pause is a primitive and vigilance has a ceiling, the practical consequences are predictable rather than mysterious.
- If the approval queue grows faster than humans can sustain attention, expect approval drift — yes-rates that climb as queue depth climbs, even when error rates are unchanged.
- If pre-pause work has non-idempotent side effects, expect duplicates on every resume that follows a node restart.
- If the approval interface shows only the proposed action without the system state and the model’s confidence, expect rubber-stamping; Article 14’s four overseer capabilities cannot be produced by a single button.
- If the escalation has no timeout fallback, expect dead workflows in long-tail percentiles — runs that wait days because the routed approver is on leave.
- If you require approval on low-risk, easily reversible actions, expect alert fatigue to erode attention available for the high-risk ones — the OpenAI guidance on scope is not a style preference, it is a budget constraint.
The practical move is to design HITL as an asynchronous review system, not a synchronous gate. Push reversible, low-stakes work to automated guardrails and policy checks. Reserve the human for actions whose cost of error exceeds the cost of latency — and for those, instrument the loop the way you would instrument a payment system, with timeouts, audit trails, and idempotency keys at every step.
Rule of thumb: the fewer decisions you ask of a human per hour, the more accurate each one will be.
When it breaks: HITL fails when the orchestrator’s pause primitive does not match the durability of the state behind it — a checkpointer that loses memory across crashes, a side effect that runs again on node re-execution, or an approval queue that grows faster than the vigilance budget of the people draining it.
The Data Says
Pause primitives are the easy half. Every major agent framework — LangGraph, CrewAI, AutoGen, OpenAI Agents SDK, Temporal — ships one. The hard half is what surrounds the pause: idempotent state, escalation timeouts, and a human whose attention budget you have not already spent on noise. Treat HITL as a system design constraint, not a feature flag, and the failure modes stop being surprises.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors