From HiPPO to Selective Scan: The Components and Prerequisites of State Space Models
ELI5
A ** State Space Model** compresses an entire sequence into a single evolving hidden vector, then updates it one step at a time. No token-by-token attention to the full history — just a running state that carries what the model still needs.
For most of the last decade, recurrent networks were the architecture that got replaced. Transformers took language modeling, and the vanishing-gradient autopsy was already written. Then a small genealogy of papers — HiPPO in 2020, S4 in 2022, Mamba Architecture in late 2023 — rebuilt the recurrence on a different mathematical foundation and started matching Transformers at twice their parameter count. The return is not nostalgia. The components actually changed.
The Five Equations That Define Every Structured SSM
State space models descend from control theory, not from deep learning. The first equation looks nothing like a Transformer layer, and that is exactly the point.
What are the core components of a state space model architecture?
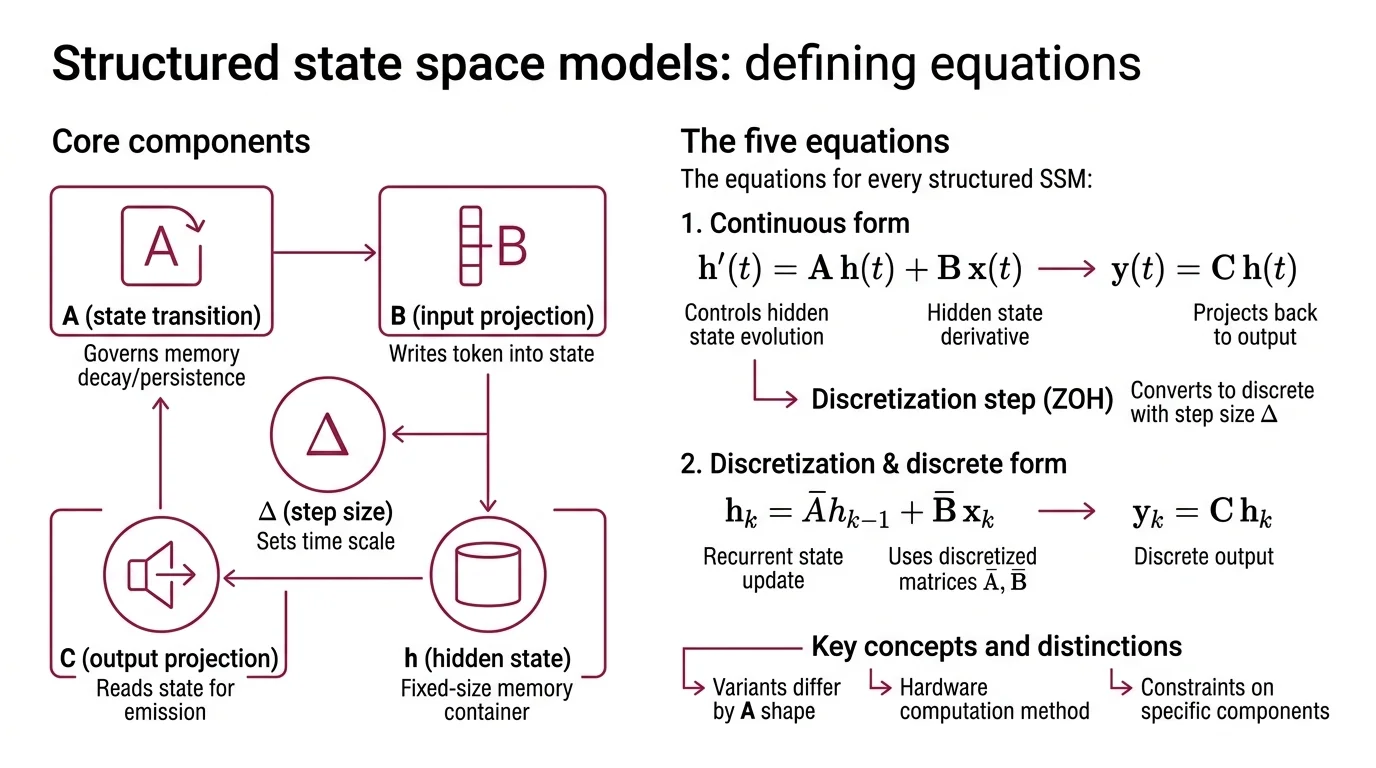
Every SSM is built from three matrices and one hidden state. The continuous form is disarmingly small: h’(t) = A h(t) + B x(t) controls how the hidden state evolves; y(t) = C h(t) projects it back out.
You cannot run continuous differential equations on a GPU, so the second layer is a discretization step. Zero-Order Hold converts continuous A and B into discrete Ā and B̄ using a step size Δ, producing the recurrent update h_k = Ā h_{k-1} + B̄ x_k and output y_k = C h_k. The matrix exponential needed for that conversion is cubic in the state dimension — an engineering constraint that shows up again later.
Name the moving parts:
- A — the state transition matrix, governs how memory decays or persists
- B — the input projection, decides how each new token writes into the state
- C — the output projection, reads from the state to produce the emission
- Δ — the discretization step size, sets the effective time scale
- h — the hidden state, the fixed-size container that carries everything the model remembers
Three matrices, one vector, one timestep. That is the whole skeleton.
Differences between SSM variants reduce to what shape A takes, whether B, C, and Δ stay fixed or depend on the input, and how the recurrence is computed on hardware. Once the skeleton is in place, each improvement lands as a constraint on a specific component, not a redesign of the architecture.
HiPPO, Selection, and Gating Solve Three Different Problems
A skeleton does not learn long-range dependencies on its own. A naive SSM drifts — forgetting old tokens, exploding on new ones — because random initialization produces an A matrix with no structural guarantee that memory is preserved. Each of the three conceptual upgrades below fixes one specific failure.
What is the SSM hidden state, selective scan, and gating mechanism?
The hidden state is the fixed-size vector h_k that carries compressed history. Its capacity is fixed: whatever arrives must either be written into it or forgotten. HiPPO, introduced at NeurIPS 2020, solved the memory-compression problem by projecting the continuous input signal onto an orthogonal polynomial basis (Gu et al. HiPPO). The HiPPO-LegS variant scales through time so the state can, in principle, remember all history with bounded gradients. That is the first upgrade: a principled A matrix that makes long memory theoretically possible.
S4 turned the principle into speed. Conditioning the state matrix with a low-rank correction lets it be diagonalized stably and reduces the SSM computation to a Cauchy-kernel calculation (Gu et al. S4). The result was state of the art on every Long Range Arena task and, at the sequence lengths reported, roughly 60x faster generation than Transformers on the tasks where attention quadratics bit hardest.
Selective Scan is the third upgrade and the one that finally closed the gap with attention. In the original S4, the matrices were data-independent — the model compressed every sequence the same way. The Mamba paper made B, C, and Δ functions of the input token (Gu & Dao). The recurrence can now selectively propagate relevant tokens and forget the rest. An associated hardware-aware algorithm fuses kernels, uses a parallel scan, and avoids materializing the expanded state in GPU HBM — roughly a 3x speedup over prior SSMs on A100 at the sequence lengths reported.
Not a recurrent network with extra steps. A recurrent network where the recurrence learns what to read.
Gating is the glue that holds the block together. The Mamba block wraps the selective SSM with a SiLU-gated linear projection — a multiplicative pathway in the GRU and LSTM lineage. The gate decides how much of the SSM’s output flows through to the next layer, and it is what lets the model learn when to rely on long-term memory versus the immediate token. Structured state, selective parameters, gating — the three pieces together. HiPPO did not invent gating — GRUs and LSTMs predate it — but the combination is what distinguishes these blocks from their 1990s ancestors.
The Prerequisite Stack That Makes SSMs Click
What do I need to understand before learning state space models?
The architecture is small; the prerequisites are not, because each component borrows from a different mathematical tradition.
Linear algebra is where most readers slow down. The stability of the recurrence depends on the eigenvalues of A, so eigendecomposition and diagonalization are not optional — they are what distinguishes memory that decays gracefully from memory that explodes on a long sequence. The low-rank correction behind S4 and the scalar-times-identity A behind Mamba-2 are both eigenvalue-structure choices.
Ordinary differential equations and discretization come next. The continuous-time formulation is where the mathematical elegance lives, but the discrete recurrence is what actually runs. Zero-Order Hold is one of many possible discretizations — each with different numerical trade-offs — and the choice matters when you hit step-size sensitivity during training.
Classical recurrent networks and their gating mechanisms are genuine prerequisites, not historical baggage. The intuition for why a SiLU-gated linear projection behaves the way it does transfers almost directly from GRU and LSTM gates. Attention is the next prerequisite, because modern SSMs are rarely deployed alone. The Hybrid Architecture families in current frontier models interleave SSM and attention layers; understanding Linear Attention specifically helps, because the State Space Duality result shows a structured SSM with a scalar-times-identity A is mathematically equivalent to masked self-attention with a 1-semiseparable causal mask (Dao & Gu Mamba-2).
Two more items finish the stack. Convolutions and the FFT matter because the parallel form of an SSM can be computed as a long convolution — this is how S4 trains efficiently even though it runs recurrently at inference. Parallel scan is the primitive that makes selective SSMs trainable on GPUs; without it, the input-dependent recurrence would serialize across the sequence.
A working order: linear algebra, then ODEs and discretization, then RNN gating, then attention, then parallel scans. Miss a layer and the next component looks arbitrary.
What the Components Predict
Once the pieces are named, the architecture behaves predictably — and so do its failures.
- Enlarge the hidden state and expect better long-range recall at the cost of memory bandwidth; the state is read and written at every step.
- Make B, C, and Δ input-dependent and you gain selectivity at the cost of the fast parallel form — which is why hardware-aware kernels become mandatory, not optional.
- Adopt a scalar-times-identity A matrix and State Space Duality collapses the recurrence into a block matrix multiplication — which is how Mamba-2’s chunked algorithm runs 2–8x faster than Mamba-1 at matching quality (Dao & Gu Mamba-2).
- Run a pure SSM language model at frontier scale and expect in-context learning and copy-task performance to lag a Transformer of similar parameter count. The fixed-size state is the reason, and no amount of training data removes it.
At inference, a pure SSM runs in O(T) time and O(1) memory per token, against the O(T²) self-attention scaling of a Transformer. Mamba-3B matched Transformers at roughly twice its parameter count on language modelling and delivered around 5x higher inference throughput at the sequence lengths measured (Gu & Dao). As with any reported speed-up, the exact factor depends on hardware and batch size.
Rule of thumb: an SSM compresses history; a Transformer references it. Whichever mode your workload spends most of its tokens in should drive your architecture choice.
When it breaks: the fixed-dimensional hidden state is both the source of linear scaling and the hard ceiling on recall. Tasks that require verbatim retrieval from arbitrary positions in the context — associative recall, needle-in-a-haystack lookup, long-form in-context learning — hit a capacity wall that attention does not have, because there is no mechanism to pull a specific past token back out of the compressed state.
The Hybrid Turn: Where Pure SSMs Rarely Ship
The architecture dominating production as of early 2026 is not pure Mamba. It is a hybrid that interleaves attention and SSM layers, usually with a Mixture Of Experts feed-forward stack on top to extend Long Context Modeling without inflating active parameters.
AI21’s Jamba 1.5 pairs one attention layer per eight total layers with a Mamba-MoE backbone, running at 256K context in both the 52B-total Mini and 398B-total Large variants (AI21). TII’s Falcon H1 family, released in May 2025, combines attention with Mamba-2 across six sizes up to 34B and extends to 262K context (TII Falcon). NVIDIA’s Nemotron-H — its 8B configuration runs 24 Mamba-2, 24 MLP, and 4 self-attention layers — reports up to roughly 3x faster inference at parity against Qwen-2.5 and Llama-3.1 at the sequence lengths measured (NVIDIA ADLR). Mamba-3, released in March 2026, introduces complex-valued state updates and a MIMO formulation while matching Mamba-2 perplexity at half the state size (Together AI).
The pattern repeats outside the Mamba family. RWKV-7 “Goose” is a linear-attention RNN hybrid with dynamic state evolution and no KV cache — another fixed-state architecture that converged on hybridization for frontier work.
The components did not lose — they got rearranged.
A pure-SSM frontier LM is rare; a hybrid SSM-Transformer-MoE is not.
The Data Says
A state space model is three matrices, one hidden state, one discretization step, and a gating wrapper — each solving a problem the others cannot. The HiPPO-to-selective-scan arc closed the long-range-memory gap and opened a linear-time alternative to attention at inference. But the hidden state’s fixed capacity is the ceiling that hybrid architectures are designed around, which is why pure SSMs rarely reach production even as their components appear almost everywhere in the current frontier stack.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors