From Feedforward Layers to Expert Pools: Prerequisites and Building Blocks of MoE Architecture
ELI5
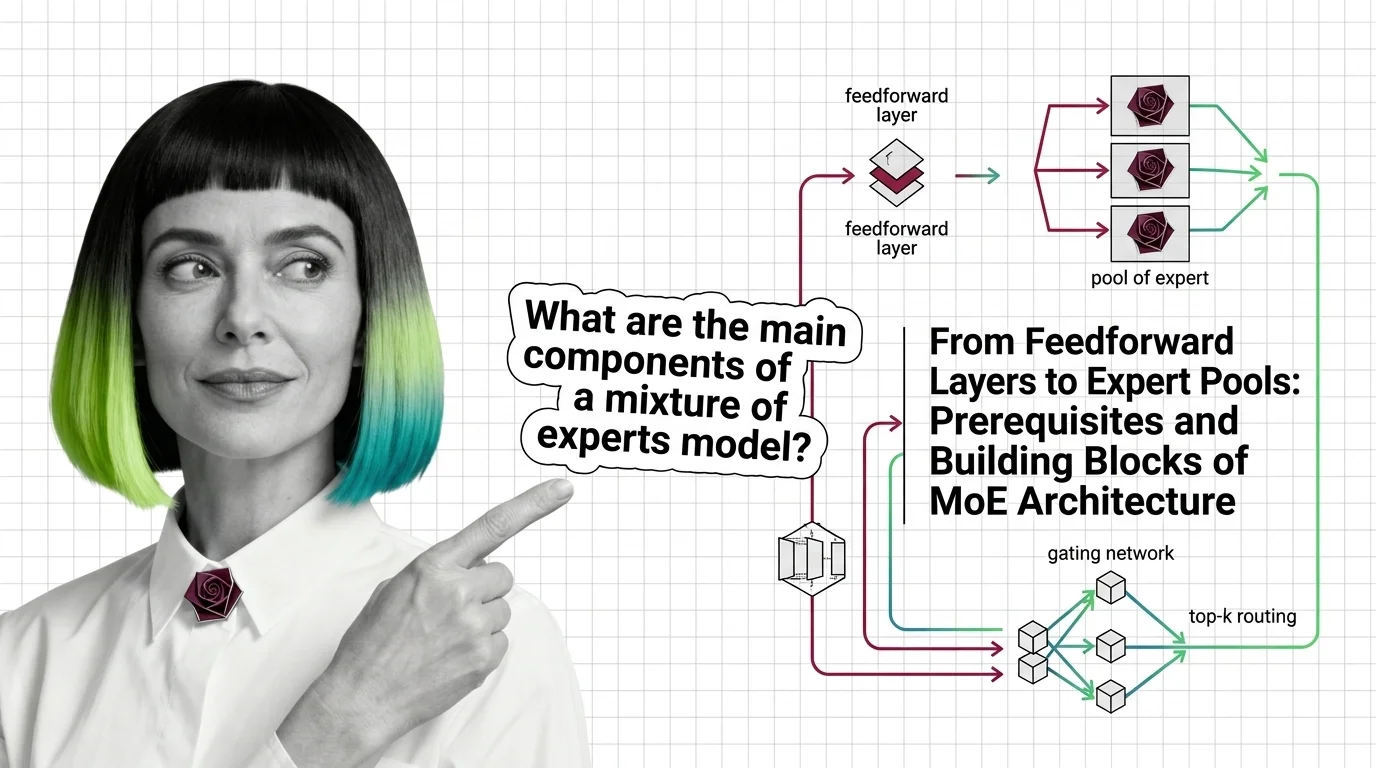
A mixture of experts model replaces one big feedforward layer with many smaller expert networks and a learned router that activates only a few per input — massive capacity, fraction of the compute.
DeepSeek-V3 has 671 billion parameters. During any single forward pass, 37 billion of them activate (DeepSeek Technical Report). The vast majority of the model sits idle for every token it processes. This is not a flaw in the engineering. It is the engineering — and the architecture that makes it possible, Mixture Of Experts, has become the default design pattern for frontier language models as of 2026. Understanding it starts not with the experts themselves, but with the single layer they replace.
The Layer That Becomes Many
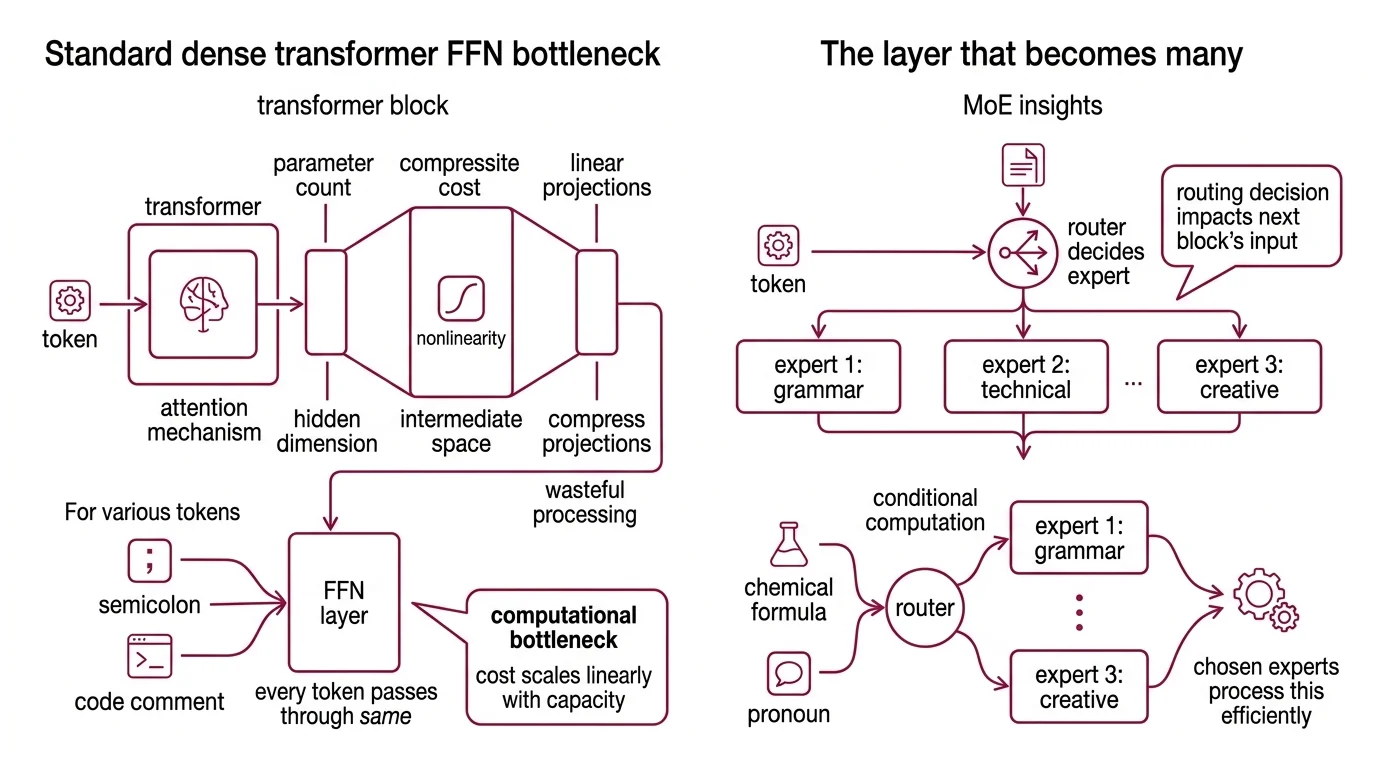
Every transformer block has two major components: an attention mechanism that determines which tokens attend to each other, and a feedforward network (FFN) that transforms each token’s representation independently. The attention mechanism gets the headlines, but the FFN is where most of the parameters live — and most of the compute burns.
What should I understand before learning mixture of experts architecture?
You need a working mental model of the standard transformer FFN and the cost it imposes at scale. In a dense transformer, every token passes through the same feedforward layer — typically two linear projections with a nonlinearity between them, expanding from the model’s hidden dimension to a wider intermediate space, then compressing back down.
This is the computational bottleneck. Doubling a dense model’s capacity means doubling the FFN width, which doubles the floating-point operations for every single token regardless of whether that token is a semicolon or a paragraph-length code comment. The cost scales linearly with capacity.
You should also understand the concept of conditional computation — the idea that not all inputs require the same processing. A token representing a chemical formula and a token representing a pronoun have different representational needs; running both through an identical FFN is architecturally simple but computationally wasteful. The mixture of experts insight is that this waste is avoidable.
Beyond the FFN itself, familiarity with how transformer blocks stack helps. Each block’s output feeds into the next block’s input, so the routing decision at one layer affects the representation available to subsequent layers. This compositional dependency is why routing quality matters far more than it might appear from looking at a single layer in isolation.
How do feedforward layers in transformers relate to mixture of experts?
The connection is almost surgical. An MoE layer replaces the single FFN in a transformer block with N parallel expert FFNs plus a Gating Mechanism — a learned router that decides which experts process which tokens (Hugging Face Blog). The attention layers remain untouched. The positional encoding stays the same. The residual connections are preserved.
What changes is the feedforward step: instead of one function applied uniformly, the model selects from a bank of specialized functions. Each expert has its own weight matrices, its own learned transformations. But for any given token, only a small subset — often just one or two — actually fire.
This is Sparse Activation in its most concrete form. The model’s total parameter count grows with the number of experts, but the compute per token stays roughly constant because only selected experts activate per forward pass. Mixtral 8x7B, for instance, carries approximately 47 billion total parameters but activates only about 12.9 billion per token with its 8-expert, top-2 routing setup (NVIDIA Blog).
The Router and Its Expert Pool
The question “what makes up an MoE model” sounds architectural. It is. But the answer is less about bricks and more about decisions — specifically, which tokens go where, and who decides.
What are the main components of a mixture of experts model?
Three components define the architecture. First, the expert networks — typically standard FFN sublayers, each with independent weight matrices — form the computational pool. Second, the router (also called the gate) is a small learned network, usually a single linear layer followed by softmax, that produces a probability distribution over experts for each input token. Third, the combination function merges the outputs of the selected experts, usually as a weighted sum scaled by the router’s gating scores.
The gating formula introduced by Shazeer et al. captures this: G(x) = Softmax(KeepTopK(H(x), k)), where H(x) includes tunable noise for load balancing. The noise is not an afterthought — without it, a small number of experts tend to dominate training, creating a rich-get-richer dynamic that starves the remaining experts of gradient signal.
This is where the auxiliary load-balancing loss enters. Standard MoE training adds a penalty that discourages the router from sending a disproportionate share of tokens to any single expert (Hugging Face Blog). The expert capacity formula — (tokens_per_batch / num_experts) times capacity_factor — defines how many tokens each expert can accept per batch; Switch Transformers operate well at a capacity factor between 1.0 and 1.25 (Fedus et al.).
But load balancing is harder than it sounds. DeepSeek-V3 abandoned the auxiliary loss entirely, replacing it with a dynamic bias term on gating scores that adjusts routing without distorting the training objective (DeepSeek Technical Report). The result: 256 routed experts plus one shared expert, with 8 active per token — training stability that earlier MoE architectures struggled to achieve.
Two Philosophies of Routing
Routing is the active research frontier of MoE. The difference between the two dominant strategies reveals a deeper tension about where the allocation intelligence should sit in the system.
What is the difference between top-k routing and expert choice routing in MoE?
In top-k routing, each token selects its own experts. The router computes a score for every expert, keeps the top k, and zeros out the rest. Top-1 routing, introduced in the Switch Transformer, assigns each token to exactly one expert — a simplification that yielded a 7x pretraining speedup at trillion-parameter scale (Fedus et al.). Top-2 routing, used by GShard, sends each token to two experts, gaining representational redundancy at the cost of doubled expert computation per token (Lepikhin et al.).
Expert choice routing inverts the decision entirely. Instead of tokens choosing experts, each expert selects the top-k tokens it wants to process from the batch (Zhou et al.). The expert becomes the active selector, not the passive recipient. This eliminates the need for auxiliary load-balancing loss — by construction, each expert processes exactly the same number of tokens. Zhou et al. reported roughly 2x convergence improvement over both Switch Transformer and GShard approaches.
The trade-off is architectural. Top-k routing is token-parallel: every token independently queries the router, making it straightforward to distribute across hardware via Expert Parallelism. Expert choice routing is batch-dependent: an expert’s selections depend on the entire batch, introducing a synchronization point that complicates distributed inference. Neither routing strategy is universally superior — top-k dominates production because of its parallelism, while expert choice shows stronger training dynamics at the cost of batch-level coordination.
What the Sparse Arithmetic Predicts
If each expert specializes — and empirical analysis of trained MoE models suggests they do, with different experts activating for different linguistic or domain-specific patterns — then MoE achieves a form of implicit task decomposition that dense models must represent in shared parameters.
If you increase the number of experts while keeping the active count fixed, you increase total capacity without increasing per-token cost. This is how DeepSeek-V3 maintains 671 billion parameters with the inference cost of a roughly 37-billion-parameter dense model. But if the router fails to distribute tokens evenly, some experts overtrain while others remain effectively random — a failure mode called expert collapse.
If you reduce the capacity factor too aggressively, tokens that overflow an expert’s buffer get dropped entirely. The model processes an incomplete batch. Output degrades silently — no error message, just worse answers.
Rule of thumb: more experts with fewer active per token increases capacity efficiency, but demands increasingly precise routing and load balancing to prevent expert starvation.
When it breaks: routing collapse is the primary failure mode — when a small subset of experts attracts the majority of tokens and the remaining experts receive too few gradient updates to develop useful specializations, the model’s effective capacity shrinks to a fraction of its total parameter count, and no amount of additional experts recovers it.
The trajectory is worth placing in context. State Space Model approaches like Mamba achieve efficiency through linear-time sequence modeling rather than sparse routing; MoE achieves it through conditional computation within the transformer framework. They solve the same underlying problem — scaling capacity without proportional compute — from different mathematical starting points.
The Data Says
Mixture of experts is an architectural bet that most computation in dense models is wasted — and the evidence across multiple generations of models supports that bet. The building blocks are deceptively simple: expert FFNs, a learned router, and a weighted combination function. The real complexity lives in routing, where the choice between token-selects-expert and expert-selects-token reflects a fundamental trade-off between parallelism and training efficiency. As of 2026, MoE is effectively the default architecture for frontier models, and understanding its prerequisites — the feedforward bottleneck, conditional computation, load balancing — is understanding the foundation that nearly every new model stands on.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors