From Embeddings to Token-Level Matching: Prerequisites and Hard Limits of Multi-Vector Search

Table of Contents
ELI5
Multi-vector retrieval stores one vector per token instead of one per document. The precision is real — so are the storage and latency costs you need to understand first.
Standard vector search compresses an entire passage into a single point in high-dimensional space. Multi-vector retrieval refuses that compression — it keeps every token as a separate coordinate. Not a refinement. A different geometry altogether. The result is dramatically better matching on nuanced queries, but something counterintuitive happens at scale: the index that held millions of passages as single vectors suddenly demands hundreds of gigabytes, and retrieval latency jumps by orders of magnitude. The question worth asking isn’t whether multi-vector retrieval works. It’s whether you understand the cost structure before you commit.
The Conceptual Debt You Carry Into Multi-Vector Search
Before multi-vector retrieval makes sense, you need to hold three ideas without confusion — and most tutorials assume you already do.
What do you need to understand before learning multi-vector retrieval?
The first prerequisite is understanding what an Embedding actually encodes. A single-vector model compresses an entire passage — hundreds of tokens — into one fixed-dimensional point. That point captures semantic meaning, but it does so by averaging. Subtle token-level distinctions (a negation, a modifier, a domain-specific term buried mid-paragraph) get smoothed into the aggregate. If you don’t understand that compression loss, you won’t understand why multi-vector retrieval exists.
The second is Similarity Search Algorithms — specifically, how approximate nearest neighbor search trades recall for speed. Single-vector retrieval runs ANN over one vector per document. Multi Vector Retrieval runs a fundamentally different operation: it computes maximum similarity across token-level vectors using what Khattab and Zaharia called “late interaction” (Khattab et al.). Instead of one distance calculation per document, you compute a matrix of token-to-token similarities and aggregate with a MaxSim operator. If your mental model of search is “find the nearest point,” you need to update it to “find the document whose best-matching tokens score highest.”
Third is Vector Indexing — the data structures that make search feasible at scale. Multi-vector retrieval doesn’t just increase the number of vectors; it changes what the index must support. A 300-token document that occupied a single index slot now occupies 300. The indexing strategy, the memory layout, the quantization scheme — all shift when the unit of retrieval changes from document to token.
These three concepts — embedding compression, similarity computation, and index structure — are load-bearing. Skip any one of them, and multi-vector retrieval looks like an inexplicably expensive version of something you already have.
Three Hundred Coordinates Where One Used to Live
Not a percentage increase. A categorical change in what your index contains.
Why does multi-vector retrieval require 10× to 100× more storage than single-vector search?
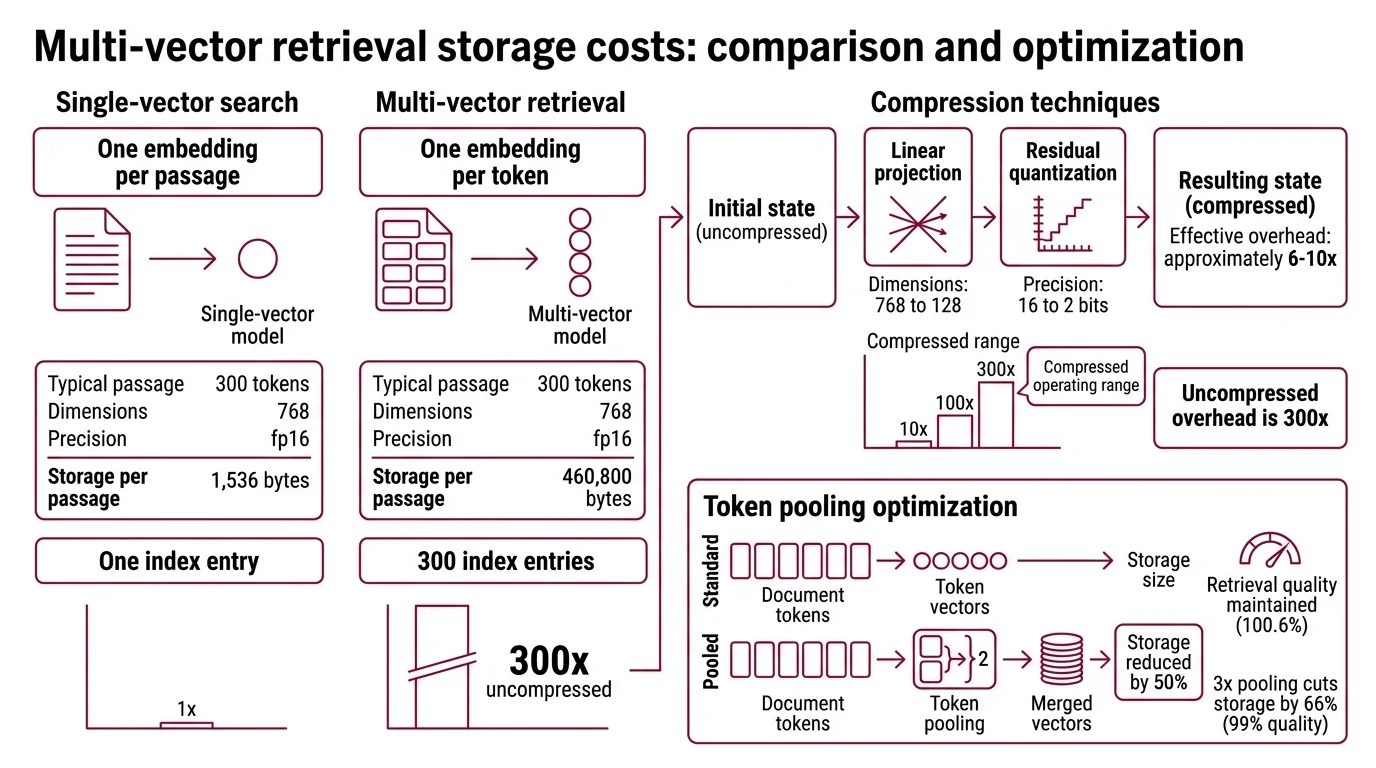
A single-vector model produces one embedding per passage. For a typical 300-token document at 768 dimensions in fp16 precision, that’s roughly 1,536 bytes (Answer.AI). One passage, one point, one index entry.
Multi-vector retrieval produces one embedding per token. The same 300-token document generates 300 separate vectors. At 768 dimensions and fp16 precision, that’s approximately 460,800 bytes — about 300 times the single-vector cost (Answer.AI).
That 300x figure is the uncompressed reality.
ColBERTv2 addresses this with two compression techniques applied in sequence: a linear projection reducing each token vector from 768 to 128 dimensions, and residual quantization compressing each dimension to 2 bits (Santhanam et al.). The combined effect is substantial — the MS MARCO index drops from 154 GB uncompressed to roughly 25 GB at 2-bit quantization (Weaviate Blog). Effective overhead against single-vector search falls to approximately 6-10x after compression.
So the range in the question — 10x to 100x — describes the compressed operating range. Uncompressed, the multiplier is closer to 300x. The variation depends entirely on how aggressively you compress, and compression trades storage for retrieval fidelity. Two-bit quantization buys an order-of-magnitude reduction in index size, but it introduces approximation errors that accumulate differently depending on domain and query type.
There is a third lever: token pooling. Merging adjacent token vectors by a factor of 2 reduces storage by 50% while maintaining 100.6% of retrieval performance — effectively no quality loss (Answer.AI). A pooling factor of 3 cuts storage by 66% at 99% retrieval quality. These numbers suggest that many token-level vectors carry redundant information; the storage curve has slack in it. But the slack runs out. Aggressive pooling eventually destroys the token-level signal that justified multi-vector retrieval in the first place.
The Retrieval Clock at 140 Million Passages
Storage is the bill you pay at rest. Latency is the bill you pay at query time — and it scales in ways that violate single-vector intuitions.
What are the latency and indexing bottlenecks when scaling multi-vector retrieval to millions of documents?
The core computational bottleneck is the MaxSim operation: for each query token, compute similarity against every candidate passage’s token vectors, take the maximum per query token, then sum. This is not a single vector-to-vector comparison — it’s a matrix operation that scales with the product of query length and passage length.
Vanilla ColBERTv2 on a CPU takes hundreds of milliseconds per query at scale. The PLAID engine — built specifically for late-interaction retrieval — reduces this to tens of milliseconds on GPU through centroid-based pruning, achieving a 7x speedup on GPU and 45x on CPU across an index of 140 million passages (Santhanam et al.). The more recent WARP engine pushes further: 58-171 milliseconds single-threaded, roughly 3x faster than PLAID and 41x faster than the XTR baseline (Kulkarni et al.).
These numbers come from research benchmarks. Production latency depends on hardware configuration, index size, quantization depth, and concurrent query load — conditions that research papers rarely replicate.
The indexing bottleneck is less discussed but equally constraining. Building a multi-vector index means encoding every token in every document, projecting to lower dimensions, quantizing, and constructing an ANN structure over a token count that may exceed the document count by two orders of magnitude. For a corpus of 140 million passages at an average of 300 tokens, you are indexing on the order of tens of billions of vectors. The time to build that index — not just to query it — can dominate your entire pipeline.
When the Precision Budget Runs Out
The pattern across both costs is consistent: multi-vector retrieval gives you token-level matching precision, and the bill arrives in two currencies — storage and latency. Compression and specialized engines reduce both costs, but they do not eliminate the structural gap.
If you’re retrieving from a corpus under a few million documents and you have GPU capacity, the latency overhead is manageable — PLAID and WARP bring query times into the tens-of-milliseconds range. If your corpus spans hundreds of millions of passages and you’re running on CPU, expect query latency that may exceed what your application tolerates unless you invest in aggressive quantization and index pruning.
If you apply compression (128-dim projection + 2-bit quantization), storage overhead drops from roughly 300x to 6-10x relative to single-vector. That’s still an order of magnitude more storage, more memory, and more I/O bandwidth — multipliers that compound in systems serving real traffic.
Token pooling offers additional headroom. Factor-of-2 pooling is essentially free in quality terms. Beyond that, you are deliberately discarding the fine-grained signal that distinguishes multi-vector from single-vector retrieval.
Rule of thumb: If your queries require matching specific terms or phrases within long documents — legal search, technical documentation, multi-modal page retrieval with Colpali — the multi-vector tax is likely justified. If your queries are broad semantic matches over short passages, single-vector search may deliver comparable quality at a fraction of the cost.
When it breaks: Multi-vector retrieval fails to justify its overhead when documents are short, queries are semantically vague, or the corpus is small enough that brute-force single-vector search already saturates recall. In those regimes, you pay the storage and latency premium without the precision benefit. Tools like Ragatouille lower the implementation barrier, but they do not change the underlying math.
Compatibility notes:
- RAGatouille LangChain integration: Deprecated as of LangChain v1.0 (Oct 2025). Core RAGatouille library (0.0.9) remains maintained; use it directly or via the pylate backend migration.
- ColPali torch compatibility: ColQwen models may fail on Mac with torch 2.6.0. Downgrade to torch 2.5.1 if affected.
The Data Says
Multi-vector retrieval is not an upgrade to single-vector search — it is a different retrieval architecture with a different cost structure. The prerequisite isn’t just understanding embeddings; it’s understanding that vector indexing at the token level changes the storage, latency, and indexing math by orders of magnitude. Compression narrows the gap. It does not close it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors