From Embeddings to Attention: The Math You Need Before Studying Transformers
Table of Contents
ELI5
Attention lets a model decide which words matter most for each other word, using dot products and softmax to create weighted connections.
The Misconception
Myth: Attention is a black box that “just works” — you can use transformers without understanding the underlying math.
Reality: Attention is a precise sequence of linear algebra operations — matrix multiplications, dot products, and a single nonlinearity — each with a clear geometric interpretation.
Symptom in the wild: Engineers debug transformer outputs by tweaking hyperparameters randomly instead of tracing which attention heads attend to which positions; they treat symptoms because they never learned to read the mechanism.
How It Actually Works
Every Attention Mechanism computes a weighted sum of values, where the weights come from measuring similarity between queries and keys. Picture a room full of radio receivers: each receiver (query) picks up signals from every transmitter (key), but amplifies only the frequencies that match its tuning. The math behind this tuning is not abstract — it is geometry in high-dimensional space, and every operation has a physical interpretation.
What math prerequisites do I need to understand attention mechanisms?
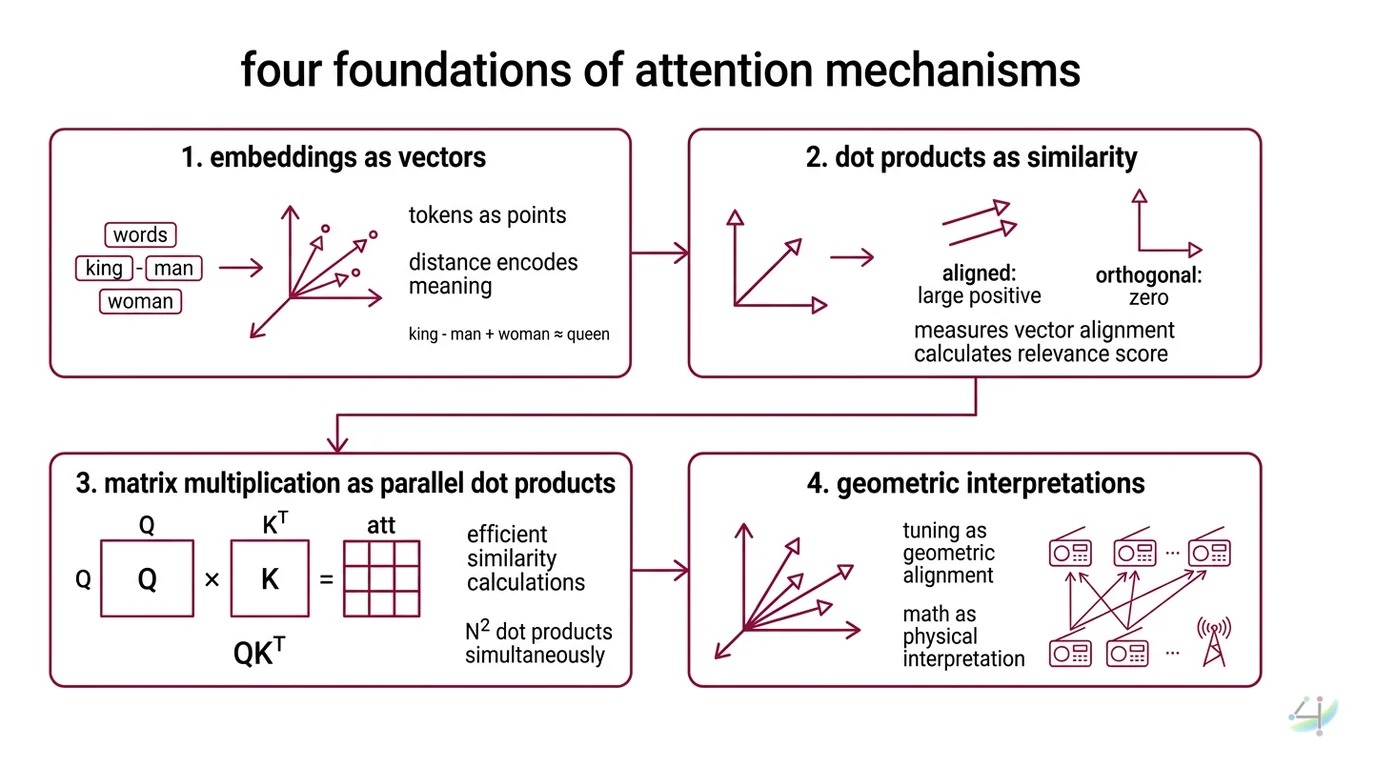
Four operations form the entire foundation. Miss any one, and the rest collapses.
Embeddings as vectors. Before attention happens, tokens become vectors — points in a learned coordinate system where distance encodes meaning. The word “king” minus “man” plus “woman” lands near “queen” not because the model understands monarchy, but because the training process organized vectors so that analogous relationships produce consistent geometric offsets. If you cannot think of words as coordinates, attention will look like magic instead of arithmetic.
Dot products as similarity. The dot product of two vectors measures how much they point in the same direction. Two vectors aligned in the same direction produce a large positive value; orthogonal vectors produce zero; opposing vectors produce negative values. This is the fundamental measurement that attention uses to decide relevance — and it is nothing more than multiplying corresponding elements and summing the result.
Matrix multiplication as parallel dot products. When the original transformer paper computes QK^T, it is performing every possible dot product between queries and keys simultaneously (Vaswani et al.). One matrix multiplication replaces N^2 individual similarity calculations. Understanding why this works — that each row of Q dots with each column of K^T — is the difference between reading the attention equation and actually seeing what it computes.
Softmax as probability. Raw dot products can be any real number. Softmax converts them into a probability distribution: all values become positive, and they sum to one. This ensures attention weights are non-negative and normalized — the model must distribute a fixed budget of “attention” across all positions (D2L). The exponential in softmax also amplifies differences: a slightly higher dot product gets a disproportionately larger weight. This amplification is what makes attention selective rather than uniform.
How do query key value matrices work in attention?
The analogy is surprisingly literal. A query is what you are searching for; a key is the label on each available item; a value is the content you retrieve when a key matches (D2L).
In practice, each token’s embedding gets multiplied by three different learned weight matrices — W_Q, W_K, and W_V — to produce its query, key, and value vectors. These projections are critical: the raw embedding carries all information about a token, but the projections extract different aspects. The query projection asks “what am I looking for?”; the key projection says “here is what I offer”; the value projection holds “here is what you get if you attend to me.”
The scaled dot-product formula assembles these pieces:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
The division by sqrt(d_k) — the square root of the key dimension — prevents dot products from growing too large in high-dimensional spaces. Without scaling, softmax saturates: it pushes almost all weight onto a single position, and gradients vanish. The scaling factor keeps the distribution soft enough to remain trainable.
Not a design choice. A numerical necessity.
What is multi-head attention and why use multiple heads instead of one?
A single attention head computes one set of queries, keys, and values — one “lens” through which the model views token relationships. Multi-head attention runs h independent sets of these projections in parallel, each with its own learned W_Q, W_K, W_V matrices (D2L). The outputs are concatenated and projected through a final matrix W_O.
Why not just use a larger single head?
Because different relationships require different subspaces. One head might learn to track syntactic dependencies — which verb governs which noun. Another might capture positional proximity. A third might specialize in coreference — linking “she” back to “Dr. Martinez” three sentences earlier. These patterns live in different geometric subspaces, and a single projection cannot separate them cleanly.
The original Transformer Architecture used 8 heads with a model dimension of 512 — so each head operated in a 64-dimensional subspace (Vaswani et al.). Modern architectures vary widely, but the principle holds: multiple narrow views outperform one broad view because they decompose the relationship space into independently optimizable components.
What This Mechanism Predicts
- If two tokens have embeddings that project to similar query-key directions, they will attend strongly to each other — regardless of their distance in the sequence.
- If the scaling factor sqrt(d_k) is removed, the model will exhibit near-one-hot attention patterns early in training, and gradient flow through the softmax will collapse.
- If you reduce the number of heads while holding total parameters constant, the model will retain aggregate performance on simple tasks but degrade on tasks requiring multiple simultaneous relationship types — long-range coreference being the first casualty.
What the Math Tells Us
The attention mechanism is, at its core, a differentiable dictionary lookup. Queries search keys; matches retrieve values; softmax ensures the retrieval is a weighted blend rather than a hard selection. Every improvement to transformers — from Flash Attention to sparse attention to linear attention — modifies one piece of this pipeline while preserving the fundamental QKV-softmax-weighted-sum logic.
FlashAttention (Dao et al.) does not change the math at all — it reorganizes the memory access pattern, tiling the computation to reduce reads and writes between GPU high-bandwidth memory and on-chip SRAM. According to Dao et al., this IO-aware approach achieves a 7.6× speedup by avoiding quadratic N×N HBM reads and writes. Successive versions continue to optimize hardware utilization across newer GPU architectures, though implementation details evolve rapidly with each generation.
Linear attention variants attempt to reduce the quadratic N^2 complexity of standard attention to linear in sequence length, but they trade expressiveness for speed — the low-rank nature of their kernel approximations degrades performance on tasks where softmax’s sharp selectivity matters most.
Rule of thumb: If you can explain what QK^T / sqrt(d_k) computes geometrically — a scaled similarity matrix between every query-key pair — you have the prerequisite math to read any transformer paper.
When it breaks: Softmax attention scales quadratically with sequence length. At context windows beyond tens of thousands of tokens, memory and compute costs become prohibitive without architectural modifications like FlashAttention’s tiling or sparse attention patterns — and each modification introduces its own approximation trade-offs.
One More Thing
The attention matrix QK^T is not symmetric. Token A attending to token B can have a completely different weight than token B attending to token A. This asymmetry is not a bug — it is what allows the model to encode directional relationships. “The cat sat on the mat” needs “cat” to attend differently to “mat” than “mat” attends to “cat.” Directionality falls out of the math because queries and keys are different projections of the same embedding.
Not symmetry. Directed flow.
The Data Says
The math beneath attention is a short list: vector embeddings, dot products, matrix multiplication, softmax, and learned projections into query-key-value spaces. None of it requires anything beyond undergraduate linear algebra — but all of it must be understood geometrically, not just algebraically, to make transformer papers readable. The mechanism is precise, interpretable, and — once you see the geometry — elegant in a way that no amount of hand-waving about “neural networks learning patterns” can substitute for.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors