OpenTelemetry GenAI: Prerequisites and Limits of Agent Tracing

Table of Contents
ELI5
Agent observability extends distributed tracing into non-deterministic LLM calls and tool use. Before turning it on in production, you need W3C Trace Context propagation, an OTLP backend, and acceptance that the GenAI semantic conventions are still being written.
You wire up tracing on an agent that calls three tools to answer one question. The first trace looks beautiful — a tidy tree of spans, neat parent-child arrows, response times to the millisecond. Then you try to answer a simple question with it: why did the agent pick that tool? The trace cannot tell you. It can show you the call happened, but the decision boundary that produced the call lives inside a probability distribution the trace was never designed to capture.
That gap is what Agent Observability is trying to close. And the gap is wider than the marketing slides suggest.
The Distributed Tracing You Already Have, And Where It Stops Short
Distributed tracing is a mature technology. W3C Trace Context Level 1 is a published Recommendation from November 2021 — every modern HTTP client and server library knows how to read a traceparent header and propagate a 16-byte trace-id across process boundaries (W3C Trace Context). Level 2 — which would standardize random trace-id generation — is still a Candidate Recommendation Draft from March 2024 (W3C Trace Context Level 2), but Level 1 is enough to stitch a request across services.
What tracing was not designed for is what an agent does. A microservice span answers the question “how long did this RPC take.” An agent span has to answer something stranger: “what did the model decide, with what context, against what probability landscape, and which tool did it choose as a result.” The plumbing carries over. The semantics do not.
What do I need to understand before adopting agent observability?
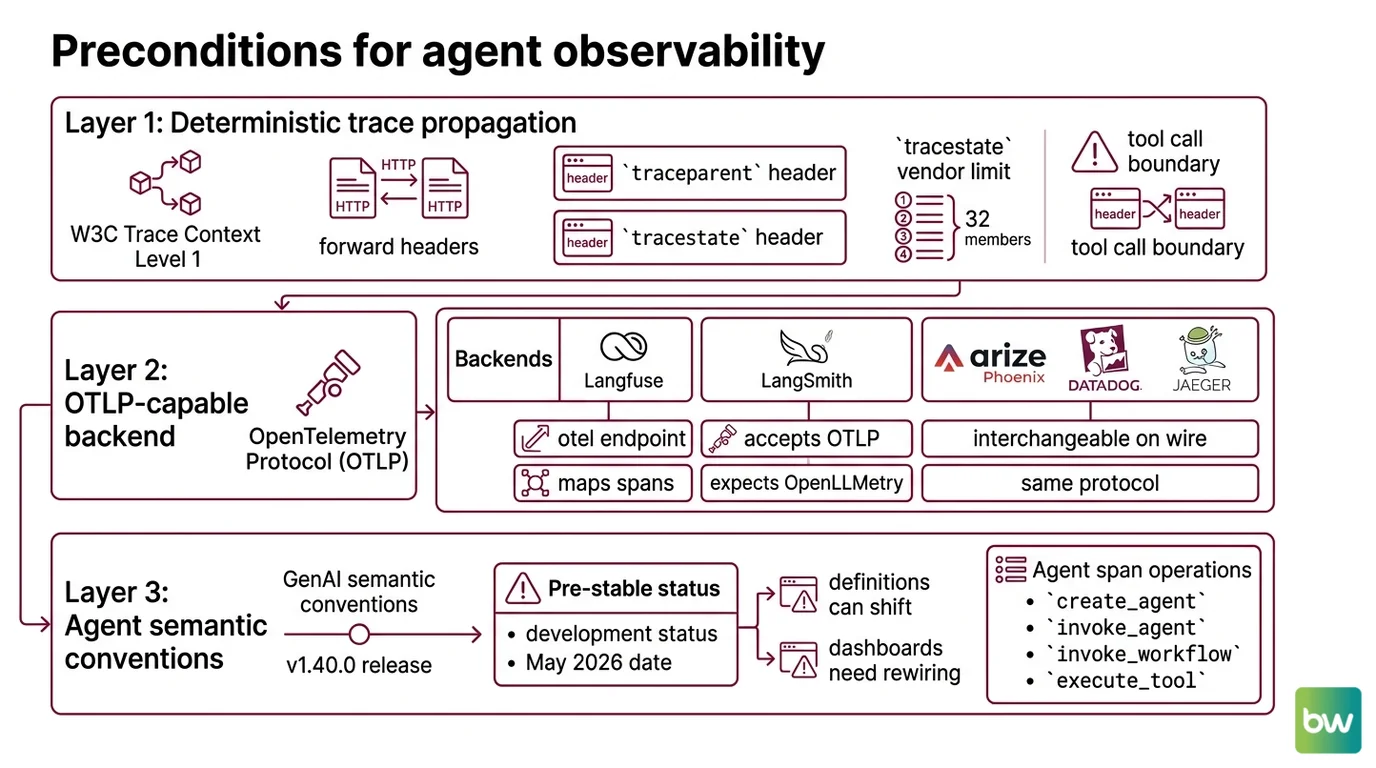
There are three layers, in this order, before you turn anything on.
Deterministic trace propagation. Your services must already speak W3C Trace Context Level 1, and your HTTP clients must forward traceparent and tracestate headers across every hop — including the call into your model provider. If a tool call crosses a process boundary and drops the header, the agent span and the tool span end up in two unrelated traces. The tracestate field carries vendor-specific data with a hard limit of 32 list members (W3C Trace Context), which matters once you start chaining frameworks that each want to write into it.
An OTLP-capable backend. OpenTelemetry’s Protocol (OTLP) is what every modern observability tool ingests. Langfuse exposes an OTel endpoint at /api/public/otel and maps incoming spans into its LLM-aware data model (Langfuse OpenTelemetry docs). LangSmith accepts OTLP today but still expects OpenLLMetry semantic conventions, with OTel GenAI semconv support on the roadmap (LangChain Blog). Arize Phoenix, Datadog, Jaeger, and others are interchangeable on the wire — they speak the same protocol, then diverge on what they do with the payload.
The semantic conventions for what an agent actually emits. This is where the prerequisite list gets uncomfortable. The OpenTelemetry GenAI semantic conventions are in Development status as of May 2026 — spans, metrics, events, and exceptions are all still pre-stable (OpenTelemetry GenAI semconv). The current release is semantic-conventions v1.40.0 (OpenTelemetry semantic-conventions releases). Pre-stable does not mean unusable. It means span names, attribute keys, and metric definitions can still shift between minor versions, and your dashboards built today may need rewiring tomorrow.
The canonical agent span operations defined by the spec are create_agent, invoke_agent, invoke_workflow, and execute_tool (OpenTelemetry GenAI agent spans). On any agent span, two attributes are Required: gen_ai.operation.name and gen_ai.provider.name. Token usage attributes — gen_ai.usage.input_tokens and gen_ai.usage.output_tokens — are Recommended, which is the spec’s polite way of saying some instrumentations will give you these and some will not. Plan accordingly.
The companion conceptual prerequisites are the ones nobody links to in the docs: Agent Evaluation And Testing (because traces show behavior, not correctness), Agent Guardrails (because an unobserved guardrail is just hope), and Human In The Loop For Agents (because some failure modes resolve in review, not in code).
The Layer the GenAI Semconv Adds On Top
The mechanical reason an agent trace is different from a microservice trace lives in one attribute: span kind.
For a hosted agent that runs in the provider’s cloud — OpenAI Assistants API, AWS Bedrock Agents — invoke_agent is a CLIENT span, because your process is calling out across the network and waiting for the result. For an in-process agent built on LangChain or CrewAI, the same operation is an INTERNAL span, because the loop is running inside your runtime (OpenTelemetry GenAI agent spans). Same span name. Different topology. The blast radius of a latency spike depends on which one you actually have.
The Recommended attributes on invoke_agent extend the model-call vocabulary into the agent layer: gen_ai.request.temperature, gen_ai.request.max_tokens, the input/output token counts, server.address, server.port (OpenTelemetry GenAI agent spans). The Required client metric is gen_ai.client.operation.duration, with gen_ai.client.token.usage recommended on top (OpenTelemetry GenAI metrics). These attributes are enough to build a latency-and-cost picture. They are not enough to reconstruct a decision.
What are the technical limits of tracing non-deterministic agent runs?
A trace is a record of a past execution. A trace of an agent run is a record of one sample from a probability distribution the model could have produced many other valid samples from.
Not a bug. A property of the substrate.
That single fact cascades into four hard limits that no backend can fix for you.
Traces cannot replay non-deterministic outputs. Temperature, sampling, and provider-side caching mean re-executing the same prompt does not reliably reproduce the same trace. Distributed tracing was built around request-replay as a debugging tool. With agents, replay gives you a different run, not the run you wanted to inspect. You can capture the inputs precisely — the prompt, the model, the temperature — and still get a different tree of tool calls on the second attempt.
Prompts and completions stop fitting in span attributes. It is an explicit anti-pattern in the OpenTelemetry GenAI conventions to stuff full prompt or completion text into span attributes (OpenTelemetry GenAI events). The reason is operational: long-string attributes balloon trace size, blow past attribute-length caps, and bypass the redaction pipeline. The convention stores prompt and completion content as span events instead, which the OpenTelemetry Collector can filter or drop without redeploying the instrumented service. Useful — but it means your “trace” of an agent now lives in two places: the span tree, and a stream of events the Collector may or may not have kept.
Span kind ambiguity hides where the latency actually lives. Because invoke_agent is CLIENT in some setups and INTERNAL in others, a single dashboard cannot generalize “agent latency” the way it can generalize “HTTP latency.” The same query against your trace store returns different things depending on which framework produced the spans.
Framework instrumentation is still being negotiated. Adapters for CrewAI, AutoGen, LangGraph, and Semantic Kernel are in active development but not finalized — each framework currently needs its own bridge into the GenAI semconv. The good news: a converged vocabulary is coming. The current cost: instrumentation drift between frameworks, and a real possibility that two of your agents emit semantically different traces for the same operation.
Traces are not a recording. Traces are a projection.
Version & stability notes:
- GenAI semconv attribute rename (BREAKING): The
gen_ai.promptandgen_ai.completionspan attributes are deprecated after semantic-conventions v1.36.0, replaced by a message-structured model emitted as span events (openllmetry issue #3515). Action: opt in withOTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimentalto emit only the new shape; otherwise instrumentations keep emitting the legacy attributes.- GenAI semconv overall status: Entire spec is in Development as of May 2026 — span names, attribute keys, and metric names can still change between releases (OpenTelemetry GenAI semconv). Action: pin instrumentation versions and treat dashboards as rewireable.
- W3C Trace Context Level 2: Still a Candidate Recommendation Draft (March 2024). Level 1 (the 2021 Recommendation) remains the only production-stable header format.
What Your Agent Trace Will Quietly Lie About
A mechanism becomes useful once you can predict where it will mislead you. Three if/then predictions follow directly from the four limits above.
- If your retry logic re-runs an agent step and the trace looks identical, you almost certainly captured the first run twice. Non-determinism plus provider caching means a truly fresh re-run rarely produces a byte-identical trace.
- If you compare two dashboards built on different frameworks and the “average agent latency” numbers differ by an order of magnitude, you are probably comparing CLIENT spans against INTERNAL spans. Same metric name, different physics.
- If your cost dashboard suddenly shows zero token usage on a subset of spans, an instrumentation upgrade probably swapped Recommended attributes around — most likely the deprecation of
gen_ai.prompt/gen_ai.completiontoward span events.
Rule of thumb: Trace what is deterministic (inputs, model, parameters, latency, tool choices) with high fidelity. Treat outputs as a sample, not a record — pipe them through evaluation, not through trace assertions.
When it breaks: The hardest failure mode is silent: a framework instrumentation upgrade changes attribute names mid-quarter, your alerting rules still match the old names, and you stop being paged for incidents that are happening. Pin instrumentation versions, watch the changelogs of the libraries that emit your spans, and treat the GenAI semconv release notes as a first-class dependency until the spec stabilizes.
The Deeper Reason Tracing Cannot Carry the Whole Load
There is an older idea hiding underneath all of this. Distributed tracing was invented for systems where the interesting variation lives in the graph — which service called which, in what order, with what latency. Agents move the interesting variation into the content — what the model decided, against what probability landscape, conditioned on what context window.
A graph-shaped tool cannot, on its own, render content-shaped variation. That is why the OTel GenAI events specification stores prompts and completions as a separate stream the Collector can prune. The trace tree is the skeleton. The events are the flesh. Pretending the skeleton is the whole animal is the most common observability mistake teams make in their first six months with agents.
The Data Says
Agent observability requires three prerequisites — W3C Trace Context propagation, an OTLP backend, and the still-Development OpenTelemetry GenAI semconv — and inherits four hard limits from the moment you turn it on: non-replayable runs, prompt content that must live in events, span-kind ambiguity, and framework instrumentation drift. Treat the GenAI semconv as a moving target until it leaves Development, pin your instrumentation versions, and design dashboards on the attributes the spec marks Required, not Recommended.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors