From Diffusion to InstructPix2Pix: AI Image Editing Prerequisites

ELI5
AI image editors look like magic, but underneath they share three ingredients: diffusion models that hallucinate pixels, classifier-free guidance that aims the hallucination, and a training trick called InstructPix2Pix that taught diffusion to follow edit instructions.
The same network that draws a castle from a paragraph can also, given the instruction “make the roof red,” repaint only the roof of your castle without touching the windows. Mechanically, the two tasks share the same forward pass. Conceptually, they shouldn’t — one is synthesis, the other is surgery. The bridge between them was built in 2022 by a paper called InstructPix2Pix, and to read the bridge you need the three papers underneath it.
The Three Papers Under Every Modern Editor
When you type “change the sky to sunset” into GPT Image or drag a reference into Flux, the output is not retrieved from a database. It is sampled — a noisy latent representation is iteratively denoised until it looks like the image the instruction described. The stack that makes this possible, and that defines every serious tool for AI Image Editing today, has three load-bearing ideas. You cannot reason about the behavior of modern editors without them.
What do you need to understand before learning AI image editing?
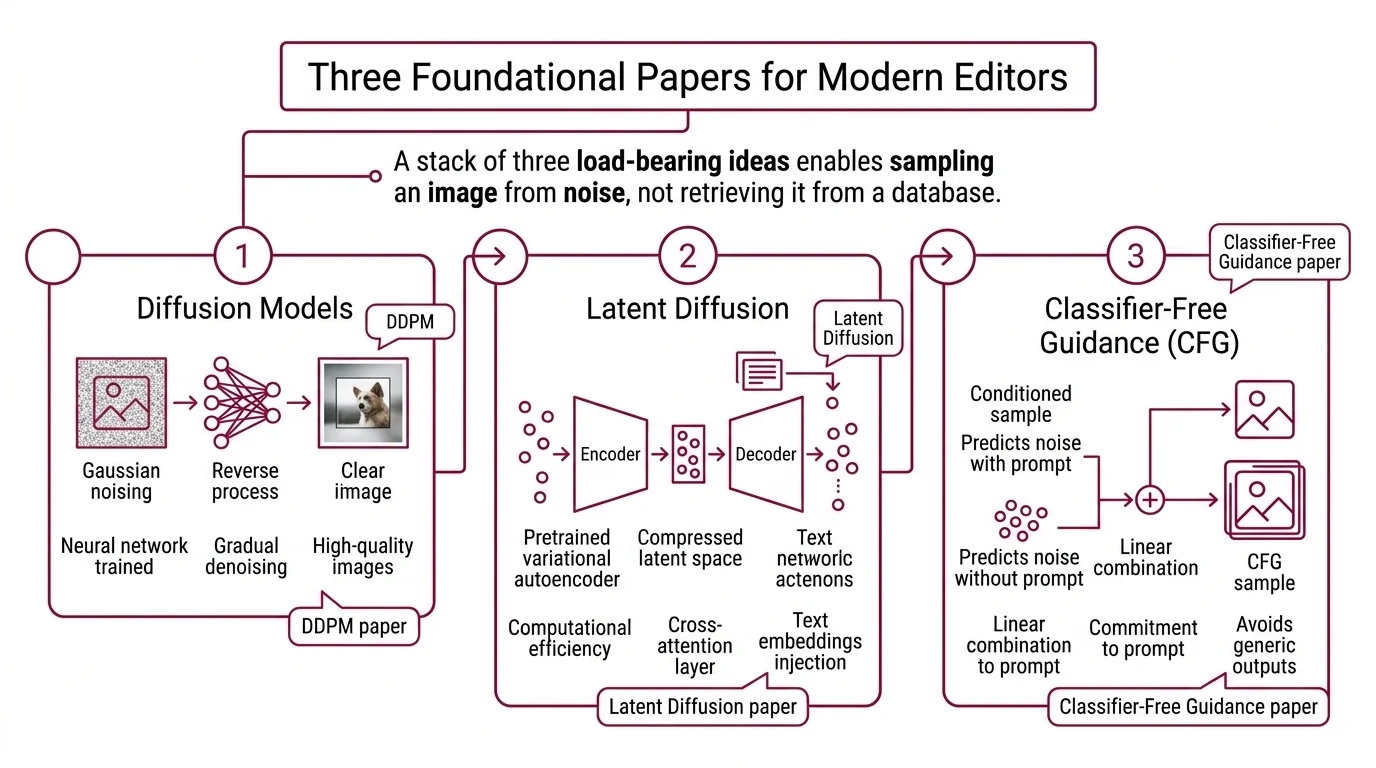
Three pieces of prior work, in order.
First: the class of models known as Diffusion Models. The DDPM paper showed that a neural network trained to reverse a gradual Gaussian noising process could generate high-quality images from pure noise, achieving an FID of 3.17 on CIFAR-10 (DDPM paper). The mechanism is counterintuitive: the network never learns to draw directly. It learns, at each noise level, what noise was probably added — subtract that noise, and you move one step toward a cleaner image. Repeat for dozens of steps and a photograph materializes out of static.
Second: latent diffusion. Operating the denoising process in pixel space is computationally expensive; every step updates millions of values at once. The Latent Diffusion paper showed that the whole process could be moved into the compressed latent space of a pretrained variational autoencoder, with a cross-attention layer injecting text embeddings into each denoising step (Latent Diffusion paper). This is the architecture Stable Diffusion builds on, and it is why an RTX card in your laptop can generate a 1024×1024 image at all.
Third: classifier-free guidance (CFG). A bare conditional diffusion model tends to produce generic outputs; its samples satisfy the prompt loosely but without commitment. CFG trains the same network to predict noise both with and without the text condition, then extrapolates the conditional prediction away from the unconditional one at inference time (CFG paper). The guidance scale is the extrapolation strength. The slider labeled “prompt strength” in a modern image tool is almost always this knob.
How these three stack into a single forward pass
At inference, the model is handed a noise sample, a text embedding, a guidance scale, and a number of steps. It runs the denoiser once per step, computing both conditional and unconditional noise predictions and blending them per CFG. Each step moves the latent toward the manifold of images that the text embedding describes. The final latent is decoded back to pixels by the VAE.
Not painting. Steering.
The model is not drawing; it is being pushed through a high-dimensional probability space by the text embedding, with CFG controlling how aggressive the push is. This reframing is the key to understanding how editing works, because editing is a small variation on the same operation.
How InstructPix2Pix Turned Generation Into Editing
Text-to-image diffusion conditions on a text prompt. Image editing needs to condition on two things: an input image AND an instruction. You cannot naively add an image-conditioning channel to a pretrained text-to-image model and expect it to work — there is no training data aligning source images, edit instructions, and target images at scale. This was the gap InstructPix2Pix closed.
How the model learned to follow edit instructions
Brooks, Holynski, and Efros synthesized the missing dataset instead of collecting it. Their pipeline used GPT-3 to generate plausible edit instructions paired with before-and-after captions, then used Stable Diffusion plus Prompt-to-Prompt to render matching image pairs that preserved layout while applying the semantic change. The result was roughly 450,000 (input image, instruction, edited output) triplets — synthetic, but consistent (InstructPix2Pix paper). Fine-tuning a text-to-image diffusion model on this dataset produced a model that, at inference, performs the whole edit in a single forward pass with no per-example optimization. No inversion. No fine-tuning at runtime. Seconds per edit.
The trick is that the instruction prompt and the input image are both passed as conditioning signals. The model interprets the instruction relative to the image, and classifier-free guidance is extended to two independent scales — one governing how faithfully the output resembles the input image, the other governing how strongly the instruction is applied. These are the two sliders that appear, sometimes renamed, in every instruction-based editor since.
Why this matters for models that are not InstructPix2Pix
Modern editors like Seedream, HunyuanImage 3.0-Instruct (released January 2026), Qwen-Image-Edit, and the flagship Adobe Firefly Image Model 4/5 generation do not use the InstructPix2Pix architecture directly. Several have moved to autoregressive multimodal transformers or mixture-of-experts backbones instead of diffusion. GPT Image 1.5, currently leading the Artificial Analysis image-editing leaderboard as of early 2026, is reportedly autoregressive rather than a diffusion model (OpenAI). What they inherit from InstructPix2Pix is the paradigm: a single forward pass, an instruction-conditioning signal, and a training distribution of synthetic or curated edit triplets.
What the Stack Predicts Will Fail
Because the stack is known, the failure modes are predictable. An instruction-following editor is a model trained on a distribution of edits; it behaves well inside that distribution and breaks at its edges. The breaks are not random. They are geometric.
What are the technical limits of instruction-based image editing?
Four failure modes recur across architectures, and each is a consequence of how the training data was built (InstructPix2Pix paper).
- Object counting fails. Instructions like “add three more apples” or “remove two of the four chairs” are poorly served because the synthetic training triplets rarely enforced precise counts. Models learn what “more apples” means qualitatively, not quantitatively.
- Spatial instructions fail or invert. “Move the mug to the left” or “swap the two figures” expects the model to reason about absolute position and relative geometry. Diffusion models encode scenes holistically; they have no explicit coordinate system. The model improvises a translation and sometimes applies it in the wrong direction.
- Viewpoint changes fail. “Show this from behind” or “rotate 90 degrees” requires 3D reasoning that a 2D image distribution cannot provide. The model hallucinates a plausible alternate view rather than reconstructing geometry.
- Identity preservation degrades under large edits. Preserving a face, a logo, or a specific object across a heavy edit is unreliable. The larger the instructed change, the further the latent drifts from the input, and the more the fine-grained identity features get overwritten.
If you are benchmarking editors, these four categories are where leaderboard winners and losers separate. Qwen-Image-Edit-2511 (released December 2025) improved specifically on multi-person consistency and geometric reasoning — which tells you where the research frontier believes the hardest problems sit.
Rule of thumb: Instruction-based editing works for global semantic changes — style, lighting, material, content replacement — and breaks for anything requiring explicit counting, coordinates, or geometric reasoning.
When it breaks: Ask for “two fewer chairs” or “move the lamp six inches left,” and a single forward pass will confidently produce the wrong count, the wrong direction, or a preserved identity that has quietly drifted. The model is not lying; it is sampling from the distribution it was trained on, and that distribution does not contain coordinates.
Licensing & currency notes:
- FLUX.2 [klein] 4B — Apache 2.0. Safe for commercial use.
- FLUX.2 [dev] / [klein] 9B — FLUX Non-Commercial License, NOT Apache 2.0. Commercial deployment requires a paid license. Confirm the license before shipping a derivative.
- InstructPix2Pix (2022) — Still the canonical paper for teaching the concept, but superseded in practice by GPT Image 1.5, Gemini 3 Pro Image, HunyuanImage 3.0-Instruct, and FLUX.2 Edit. Read the original to understand modern editors; use the modern editors to produce real work.
The Data Says
Every modern instruction-based image editor inherits the same conceptual stack: diffusion as the generative prior, classifier-free guidance as the steering mechanism, and a synthetic-triplet training scheme in the spirit of InstructPix2Pix. The architectures have diverged — some are now autoregressive rather than diffusion — but the editing paradigm is stable. Understand why the stack works, and you understand why “add three apples” and “move left” are still the requests that fail in early 2026.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors