From Data Curation to Checkpoints: The Building Blocks of a Modern Pre-Training Pipeline
Table of Contents
ELI5
Pre-training is the industrial process that gives a language model its general knowledge — filtering massive text, removing duplicates, distributing training across GPUs, and saving checkpoints — before any task-specific learning begins.
Here is something that should bother you: two models trained on the same volume of web text can differ dramatically in downstream performance — not because of architecture, not because of hyperparameters, but because one team spent months on data curation while the other spent a weekend. The pipeline between raw internet and trained weights is where most of the engineering actually lives. Fine Tuning and RLHF get the press coverage, but they inherit whatever the pre-training pipeline gives them — and they cannot repair a corrupted foundation.
The Assembly Line Nobody Sees
Think of Pre Training as industrial chemistry. The raw material — web crawls, academic papers, code repositories — arrives contaminated, redundant, and unevenly distributed. What happens between “download CommonCrawl” and “start gradient descent” determines whether the resulting model reasons or merely sounds like it does. The pipeline has five broad stages, each with its own failure modes, its own tooling, and its own hard-won engineering lessons.
What are the main stages of an LLM pre-training pipeline?
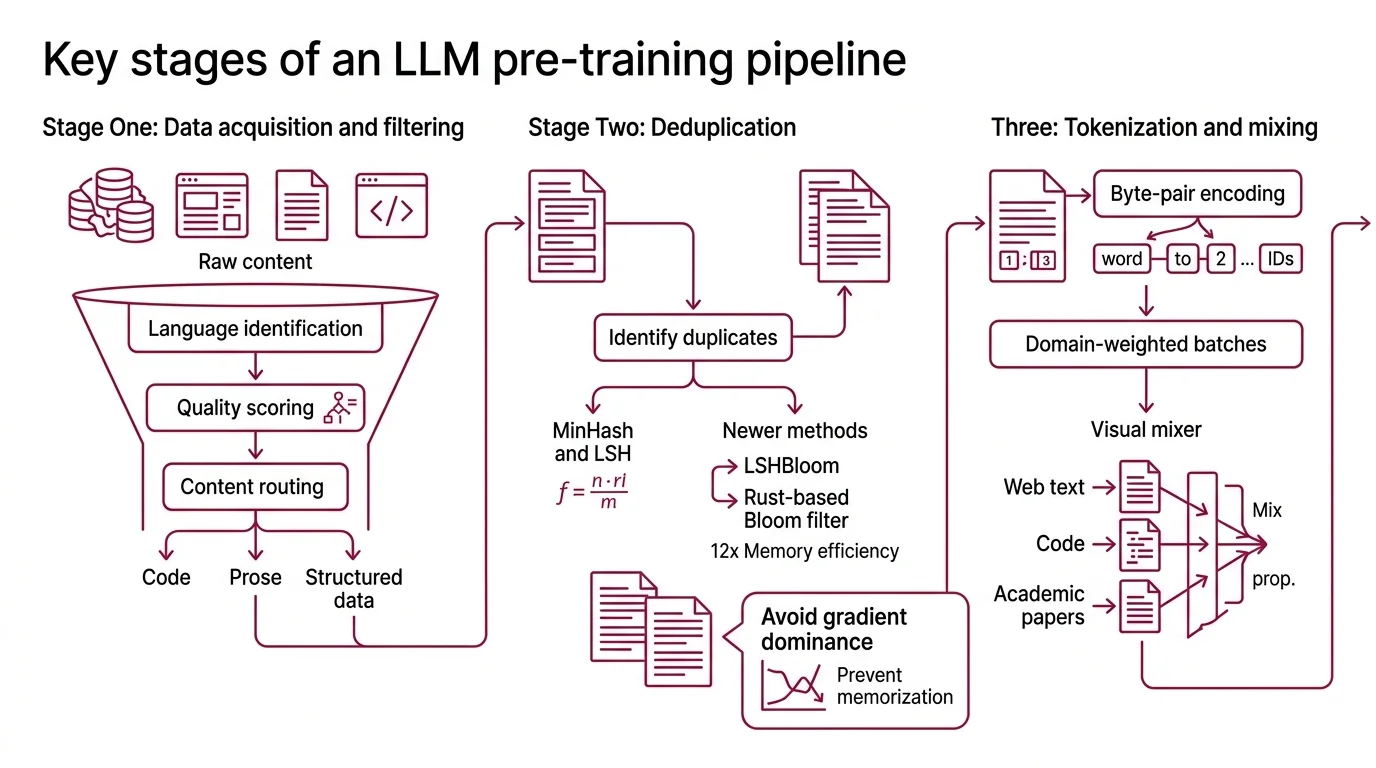
Stage one: data acquisition and filtering. Raw web crawls are noisy — boilerplate HTML, cookie banners, duplicated paragraphs, machine-generated spam. Modern pipelines run multi-pass filtering: language identification, quality scoring (often with a small classifier trained on curated examples), and content-type routing that separates code from prose from structured data.
Stage two: deduplication. Duplicate text is not merely wasteful; it distorts the gradient landscape. A paragraph repeated thousands of times across CommonCrawl receives disproportionate gradient updates, biasing the model toward memorizing that specific phrasing rather than learning the underlying pattern. The dominant approach uses MinHash with locality-sensitive hashing to identify near-duplicate documents at scale. A newer method, LSHBloom, replaces traditional signature comparison with Bloom filters and achieves roughly 12x the throughput (arXiv LSHBloom). Dolma’s toolkit takes a different path — a Rust-based Bloom filter engine that prioritizes memory efficiency during deduplication (AI2 Dolma GitHub).
Not memorization by choice. Gradient dominance.
Stage three: tokenization and mixing. The filtered corpus is tokenized — typically with byte-pair encoding — and split into domain-weighted batches. The ratio of web text to code to academic papers is a design decision that shapes what the model will be good at; there is no universal optimal mix.
Stage four: distributed training. At the scale of hundreds of billions of parameters, no single GPU holds the full model. Frameworks like Megatron-LM decompose training across tensor parallelism, pipeline parallelism, data parallelism, expert parallelism, and context parallelism — each trading off memory, communication bandwidth, and compute efficiency. Megatron-Core reports up to 47% Model FLOP Utilization on H100 clusters, scaling to 462 billion parameters (NVIDIA Megatron-Core). DeepSpeed provides an alternative path through its ZeRO optimizer stages, which partition optimizer state, gradients, and parameters progressively across devices.
Stage five: checkpointing. Training runs that cost millions in compute cannot afford to lose progress to a hardware failure. Checkpoints capture the full optimizer state — not just model weights but momentum buffers, learning rate schedules, and data loader positions — so training resumes from the exact iteration where it stopped.
How do data curation tools like FineWeb and Dolma prepare training corpora for pre-training?
FineWeb and Dolma represent two engineering philosophies applied to the same problem.
FineWeb, maintained by Hugging Face, processes approximately 15 trillion tokens of English text drawn from 96 CommonCrawl snapshots spanning 2013 to 2024 (Hugging Face FineWeb). Its backbone is datatrove, an open-source library that implements the full curation pipeline: URL filtering, language detection, quality classification, and deduplication. The v1.4.0 release in July 2025 added six new CommonCrawl snapshots from 2025. FineWeb-2 extends coverage to over 1,000 languages (Hugging Face FineWeb-2). One caveat worth noting: FineWeb’s token counts use the GPT-2 tokenizer, so the reported figure shifts depending on which tokenizer you apply.
Dolma, built by the Allen Institute for AI, takes a more compositional approach — 3 trillion tokens assembled from web, academic, code, books, and encyclopedic sources (AI2 Dolma GitHub). Where FineWeb is a curated web crawl, Dolma is a curated blend. Its deduplication engine uses Rust-based Bloom filters optimized for speed and memory efficiency. The toolkit is available via pip under the ODC-BY license, which means you can modify and redistribute both the tools and the data.
The practical distinction matters. FineWeb optimizes for volume and English-language web quality. Dolma optimizes for source diversity and reproducibility. Neither is categorically better — the choice depends on whether your bottleneck is data volume or domain coverage. But understanding what these tools optimize for requires looking one layer deeper — at the math they are built on.
The Mathematical Scaffolding Below the Pipeline
The prerequisite stack for understanding pre-training is narrower than it appears, but each layer is load-bearing. Remove one, and the rest of the pipeline becomes opaque.
What math and machine learning concepts do you need before understanding LLM pre-training?
Linear algebra is the substrate. Every forward pass is a sequence of matrix multiplications; every attention head computes a weighted sum over value vectors. If you cannot read a matrix equation fluently, the training loop — the thing that turns raw text into a model — stays a black box.
Probability and information theory provide the objective function. Cross-entropy loss — the standard pre-training objective — measures the divergence between the model’s predicted token distribution and the actual next token. Perplexity, the exponentiated cross-entropy, gives an interpretable number: how many tokens the model is effectively choosing between at each prediction step. Lower perplexity means less uncertainty — the model narrows its candidates to fewer plausible continuations.
Optimization theory explains why training converges at all. Stochastic gradient descent and its variants — Adam, AdaFactor, LAMB — navigate a loss surface with billions of dimensions. Learning rate schedules, warmup periods, and gradient clipping are not arbitrary rituals; they control whether the optimizer converges, oscillates, or diverges entirely.
Masked Language Modeling — the training objective behind BERT-family models — masks random tokens and trains the model to predict them from bidirectional context. Autoregressive models (GPT-family) predict the next token given all previous tokens. These are different probability factorizations with different strengths: bidirectional models excel at understanding; autoregressive models excel at generation.
And then there are the Scaling Laws themselves. The Chinchilla ratio — approximately 20 tokens per parameter for compute-optimal training, published by Hoffmann et al. in 2022 — became something like gospel for a few years. But in practice, teams now train well beyond that ratio. Llama 3’s 8-billion-parameter model trained on 15 trillion tokens, roughly 1,875 tokens per parameter (AIMultiple). Why? Because inference cost scales with parameters, not with training data. A smaller model trained longer costs less to serve than a larger model trained less — and you only train once, but you serve forever.
Not waste. Economics.
The Densing Law, proposed in 2025, captures this shift: parameter efficiency improves exponentially over time, driven by architectural innovation rather than brute-force scale (AIMultiple). The implication is that the number of parameters needed for a given performance level keeps shrinking — which means the optimal training budget keeps shifting toward more data and smarter curation, not bigger models.
What the Pipeline Predicts About Failures
The implications of this architecture are asymmetric. A well-curated dataset with a mediocre training framework still produces a usable model. A badly curated dataset paired with the best distributed training infrastructure produces a model that has memorized spam.
If your deduplication is incomplete, expect the model to regurgitate specific phrases verbatim — not because it chose to memorize them, but because those phrases dominated the gradient signal during training.
If your domain mix is skewed toward web text, expect weaker performance on code and structured reasoning. The model absorbed the prior distribution of the internet, which is heavy on informal prose and light on formal logic.
If your checkpoint strategy saves only model weights without optimizer state, a resumed training run starts with cold momentum buffers. The optimizer has to rediscover the trajectory it was already on — hundreds of GPU-hours spent retracing steps.
Rule of thumb: Budget at least as much engineering time for data curation as for training infrastructure. The model will never outperform its data.
When it breaks: The hardest failure is silent — a subtle quality regression in one CommonCrawl snapshot introduces enough noise to degrade downstream benchmarks by a few points, visible only after weeks of training and millions in compute. There is no compiler error for bad data.
Compatibility notes:
- Megatron-Core FSDP refactor (BREAKING): The namespace moved from
megatron.core.distributed.custom_fsdptomegatron.core.distributed.fsdp.src.megatron_fsdpin recent releases. Update import paths before upgrading.- Megatron-Core Python 3.10 deprecation: The upcoming v0.17.0 release (release date not yet confirmed) drops Python 3.10 support; plan for Python 3.12 or later.
The Data Says
Pre-training is not a single operation — it is an industrial process with distinct engineering disciplines at each stage. The gap between teams that treat data curation as a weekend task and teams that treat it as a core competency shows up across benchmarks. The math underneath — cross-entropy, scaling laws, optimizer dynamics — is not decoration. It is the reason some pipelines produce models that reason and others produce models that autocomplete.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors