From Coverage Metrics to Mutation Testing: What You Need to Know Before Using AI Test Generators
Table of Contents
ELI5
AI test generation tools write unit tests that compile and execute your code. That is not the same as catching bugs. Coverage tells you what code ran during the test. Mutation testing tells you whether the assertions would notice if the code lied.
A team runs an AI Test Generation tool over a payments module. The generated suite compiles, executes, and reports 91% line coverage. A separate run of a mutation testing tool over the same suite kills only about a third of the seeded faults. Same code. Same tests. Two completely different stories about whether the module actually works — and only one of them is true.
The Two Numbers Most Test Reports Don’t Show You
Coverage and mutation score are not competing metrics. They measure different things, at different layers of the test stack — and the gap between them is exactly where AI-generated test suites tend to fail. Before you let an AI tool fill a repo with tests, you need a clean mental model of what each number actually proves.
What do I need to understand before using AI test generation tools?
Three things, in order.
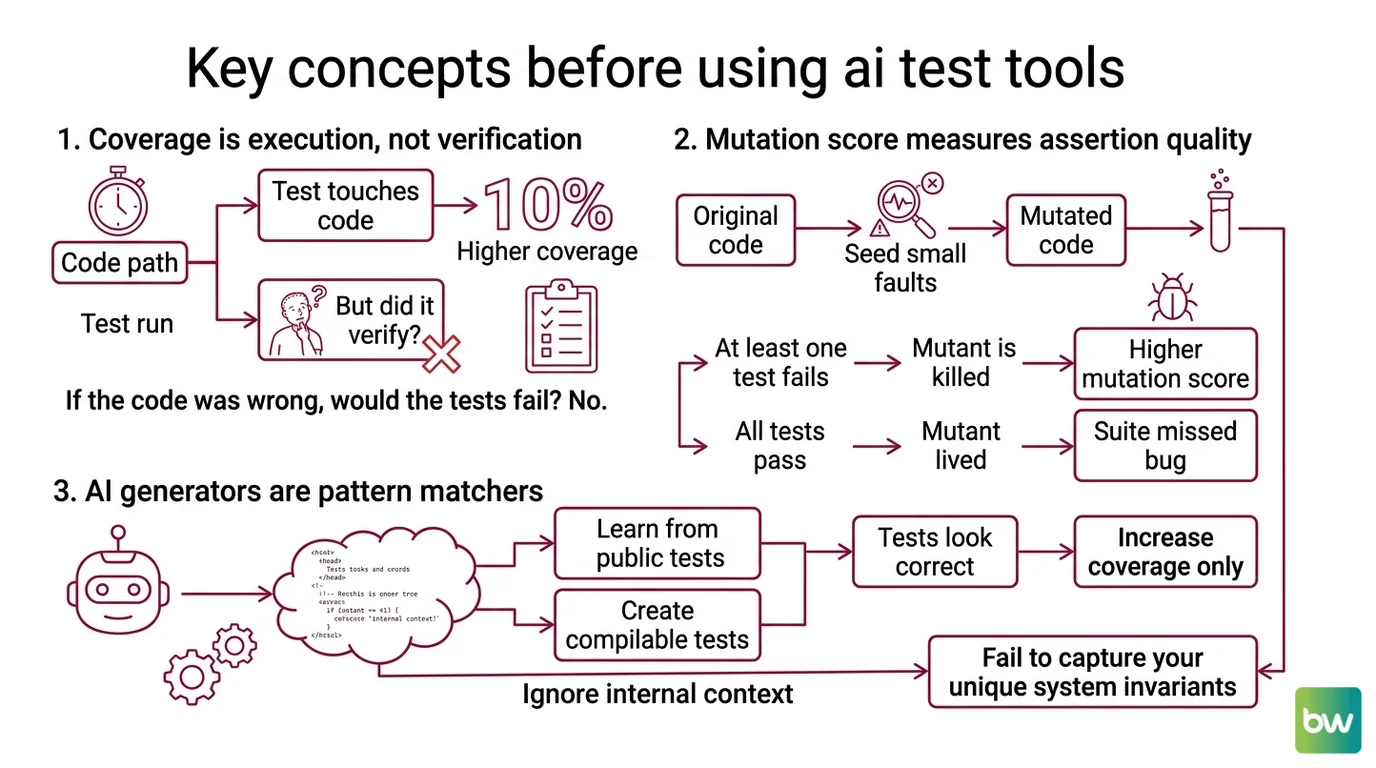
First, coverage is a measurement of execution, not verification. Line coverage records which lines the test runner touched. Branch coverage records which conditional outcomes were exercised. Neither one asks the question that matters: if the code were wrong, would my tests fail? A test that calls a function and ignores the return value drives coverage up. It also drives confidence up. Only one of those is justified.
Second, mutation testing measures whether your assertions are awake. A mutation testing framework seeds small, syntactically valid faults — flipping > to >=, replacing a return value with null, deleting a line — and re-runs your test suite against each mutated version of the code. If at least one test fails, the mutant is “killed.” If every test still passes, the mutant “lived” and your suite just told you it would not have noticed the bug. The mutation score is the percentage of non-equivalent mutants killed (PIT Mutation Testing).
Third, AI test generators are pattern matchers trained on tests that compile. They learned the shape of a unit test — arrange, act, assert — from millions of public test files. They are very good at producing tests that the language compiles, the runner accepts, and the coverage tool credits. They were not trained to recover the invariants of your system, because those invariants live in your head, your tickets, and your domain. Nowhere in the training data.
The reason these three points belong together is that they describe a single optimization loop. An AI generator optimizes for what it can see (existing code, existing tests, syntactic patterns). Coverage tools reward what is easy to count (execution). Mutation testing forces a different question (would a fault be detected) and routinely returns a much harsher answer.
How Mutation Testing Closes the Gap
The mechanics are deliberately simple. Take a function. Generate a population of mutants by applying a small set of well-defined operators: arithmetic substitution, boundary shift, return value replacement, conditional negation, statement deletion. Run the test suite against each mutant. Count the survivors.
Survivors are the interesting part. A surviving mutant is a falsifiable claim: “there is a bug-shaped change to your code that none of your tests would catch.” Sometimes the mutant is “equivalent” — semantically identical to the original — and the survival is meaningless. The rest of the time, it points at a specific assertion you forgot to write, or an edge case the test suite never considered.
Industrial measurements have shown the gap can be extreme. One Springer STTT industrial study reported cases where suites with 100% branch coverage achieved roughly 4% mutation score — every line ran, almost no fault was detected. The same study cites the main reasons teams resist adopting mutation coverage: build-system integration overhead, the perception that “branch coverage is good enough,” and the performance cost of running the suite once per mutant.
Tooling is mature enough to remove most of those excuses. PIT runs on Java and the JVM with Maven and Gradle integration. Stryker covers JavaScript, TypeScript, C#, and Scala through separate projects per language. mutmut handles Python via PyPI. The mechanism is the same in each: seed faults, re-run, count what your suite missed.
A note before going further. The correlation between mutation score and real fault detection is positive but not strict. An ICSE 2018 study by Papadakis et al. found a strong correlation with manually seeded faults and a moderate correlation with student-introduced faults, with the relationship weakening once test suite size was controlled for. Mutation score is a sharper instrument than coverage. It is not a guarantee that high score equals zero bugs.
Inside the AI Generator’s Optimization Target
Once you understand what mutation testing measures, the failure mode of LLM-based test generators becomes structural rather than mysterious. It is not that the model is “bad at testing.” It is that the model is optimizing for a target that overlaps with — but does not equal — bug detection.
Why do AI-generated tests fail to catch real bugs and produce false confidence?
Three mechanisms compound.
The training data is biased toward shape, not invariants. Public test files overwhelmingly follow the canonical setup → call → assert on observed output structure. The model learned that template thoroughly. So when you ask it to test calculateTax(order), it produces a test that calls calculateTax with a plausible-looking order and asserts that the result equals whatever the current implementation returns. The test will pass today. It will also pass after a regression that silently rounds the wrong way, because the assertion was harvested from the same code it is supposed to verify.
The optimization signal is compilation, not falsification. When AI test generators are evaluated, the most legible metric is “does this test compile and run.” Diffblue’s GPT-5 benchmark in 2025 reported that roughly 12% of GitHub Copilot-generated tests failed to compile even on the upgraded backend (Diffblue’s GPT-5 benchmark). The rest run. The next-most-legible metric is coverage. The metric almost nobody runs in the generator’s evaluation loop is mutation score. So the model is selected for tests that exist, not for tests that would fail when the code is wrong.
Assertions cluster around what is visible. A AI Code Completion model, including those repurposed for test generation, tends to assert on the things it can directly observe in the source: serialized outputs, hard-coded timestamps, mocked return values, fields that already exist in the function body. It rarely asserts on the invariants you actually care about — monotonicity, idempotency, conservation of total, error states, the contract with downstream consumers — because those invariants are not literally written in the code. They live in the requirements document you never wrote.
An arXiv survey of AI-driven tools in modern software quality assurance put rough numbers on the surface-level behavior: GPT-4 produced approximately 72.5% valid tests, with roughly 15.2% identifying edge cases the human developer had not considered, in one snapshot evaluation; accuracy dropped about 25% on harder algorithmic problems. Useful, often. Sufficient as a verification layer, no.
This is also why behavior-focused tools occupy a different niche. Diffblue Cover uses reinforcement learning specifically tuned for Java unit test generation and reports 100% compilation success on its targets; the company published a vendor-controlled benchmark in November 2025 claiming a 20x productivity advantage over LLM-based assistants. Qodo, formerly CodiumAI, released Qodo 2.0 in February 2026 with a multi-agent review architecture across Python, JavaScript, TypeScript, Java, and Go. Both attempt to move the optimization target away from “tests that compile” toward something closer to “tests that exercise behaviors.” Whether they close the mutation gap on your codebase is an empirical question your build pipeline can answer.
Not magic. Optimization geometry.
What This Predicts About Your AI-Generated Test Suite
Translate the mechanism into observations you can verify in your own build pipeline this week:
- If your AI-generated tests sit at very high line coverage but you have never run a mutation testing pass, expect the mutation score to be substantially lower than the coverage number — sometimes by a wide margin. One industry analysis from CodeIntelligently described a generated suite at roughly 91% line coverage but only about 34% mutation score; treat the specific figures as illustration from a single industry blog post, not as a benchmark, and run the measurement on your own code.
- If your generated tests assert primarily on serialized output or hard-coded values, expect them to survive almost every refactor and to fail to catch behavior-changing regressions. The tests will pass right up to the moment a customer reports the bug.
- If your team uses an AI test generator inside a CI loop that only gates on compilation and coverage, expect test volume to grow while bug-escape rate stays flat or rises. More tests, same blind spots.
- If you add a mutation testing stage and start triaging surviving mutants by hand, expect the surviving set to cluster around boundary conditions, error paths, and domain invariants — exactly the regions an LLM has no way to infer from source code alone.
Rule of thumb: before you trust an AI-generated test suite, measure the mutation score on a representative slice of the codebase, then compare it to the coverage number on the same slice. The size of the gap is the size of your false-confidence problem.
When it breaks: mutation testing carries a non-trivial runtime cost — the suite executes once per mutant, which on a large codebase can multiply CI time by an order of magnitude. Equivalent mutants also inflate the survivor count and require human triage. The technique pays for itself on critical modules (payments, auth, pricing, data integrity), not on every file in the repository.
The Geometry Behind the Gap
A useful way to hold all of this in one frame: coverage, mutation score, and AI Code Review signals are projections of the same test suite onto different axes. Coverage measures execution. Mutation score measures sensitivity to faults. Code review measures human judgment on whether the right things are being asserted. An AI test generator that is excellent on the first axis can be mediocre on the second and silent on the third. The right adoption posture is to read all three numbers — and to be most suspicious when the first one is the only one that looks good.
The Data Says
AI test generators are reliable producers of executable tests and unreliable producers of fault-detecting tests, because they were trained and evaluated on signals that reward the first behavior, not the second. Coverage is a measurement of test execution; mutation testing is a measurement of test sensitivity to faults. Until your build pipeline runs both, “we have AI-generated tests” tells you about the volume of tests in the repo, not about the safety of the code those tests are supposed to guard.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors