From Courtroom Fabrications to Finix-S1's 1.8% Error Rate: Hallucination Failures and Fixes in 2026
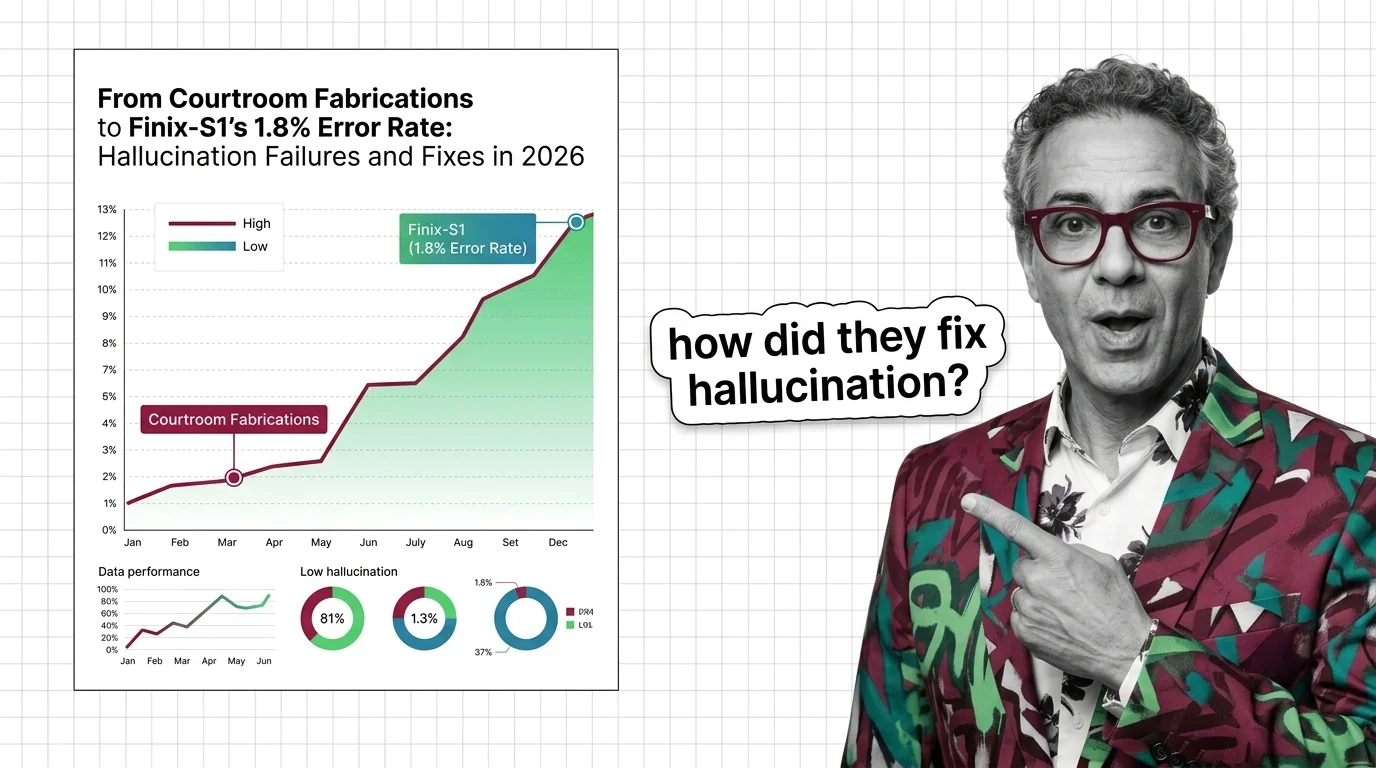
Table of Contents
TL;DR
- The shift: Harder benchmarks reveal frontier models still hallucinate above 10% while specialized models push below 2% – a two-tier accuracy split the industry has not priced in.
- Why it matters: Over 1,180 documented legal cases and six-figure sanctions prove hallucination is no longer a technical curiosity – it is a liability event.
- What’s next: The gap between benchmark accuracy and real-world reliability becomes the defining deployment challenge of 2026.
The AI industry reduced Hallucination rates by 96% between 2021 and 2025 on standard benchmarks. In the same window, courts escalated sanctions against attorneys who trusted those models from thousands to six figures.
Both numbers are verified. The contradiction between them is the story.
The Accuracy Split Nobody Priced In
Hallucination is not being solved. It is fracturing into two separate problems, and most organizations are preparing for the wrong one.
Vectara’s hallucination leaderboard just reset the playing field. The dataset expanded from 1,000 articles to 7,700 – spanning 10 domains with documents up to 32K tokens (Vectara Blog). The evaluation model upgraded to HHEM-2.3. Scores from the old benchmark are not comparable to the new one.
The results exposed a structural gap.
AntGroup’s Finix-S1-32B landed at 1.8% on the new benchmark – top of the leaderboard for grounded summarization (Vectara’s GitHub). OpenAI’s GPT-5.4-nano came in at 3.1%. Google’s Gemini-2.5-Flash-Lite at 3.3%.
The frontier reasoning models? GPT-5, Claude Sonnet 4.5, Gemini-3-Pro, Grok-4, Deepseek-R1 – all above 10%.
That is not a footnote. It is a divide between models optimized for Factual Consistency on constrained tasks and models built for general reasoning.
The first group is getting remarkably accurate at restating what exists in a source document. The second group is still guessing when documents get long and complex.
Where Fabrication Meets Consequence
The benchmark numbers are abstract. The courtroom numbers are not.
A database tracking AI fabrication in legal filings has documented 1,180 instances since mid-2023 (Charlotin Database). The pace is accelerating.
In March 2026, two sanctions landed in the same month. The Sixth Circuit imposed $30,000 for fabricated citations (Suprmind). An Oregon court went further – $109,700 in Couvrette v. Wisnovsky for AI-generated case law that did not exist.
Last year, three attorneys on the MyPillow case were fined $3,000 each for fake citations (NPR).
Stanford research found that leading models hallucinate on 69-88% of complex multi-source legal queries – tasks far removed from simple summarization (Suprmind).
Medicine carries the same risk. ChatGPT hallucinated non-existent cancer treatments in 12.5% of tested cases. Whisper showed hallucination rates of 50-80% in medical transcription settings (Suprmind).
One industry estimate puts global losses from hallucination at roughly $67.4 billion in 2024 (Suprmind). Treat that as order of magnitude, not a precise figure. The liability direction is clear regardless.
Who Is Pulling Ahead
AntGroup earned the top spot by specializing. Finix-S1-32B’s 1.8% rate is for Grounding-constrained summarization – not open-ended generation. On the old 1,000-article dataset, the same model scored 0.6%. The gap reflects a harder test, not a worse model.
Vectara itself is winning by raising the bar. The expanded benchmark forced the entire leaderboard to reset. Labs that looked dominant on the easy test now have real numbers to explain.
Teams deploying Retrieval Augmented Generation with modular or agentic architectures are seeing up to 71% hallucination reduction (Lakera). Naive RAG is prototype-only in 2026. Agentic RAG and corrective RAG are where production deployments are landing.
Who Just Got Exposed
Frontier labs whose flagship models scored above 10% on complex summarization. The harder benchmark retracted their claimed accuracy gains.
Legal teams deploying any model without Chain-of-Thought verification and grounding infrastructure. The sanctions trajectory moved from $3,000 per attorney to $109,700 per case in under a year.
Medical AI deployments without Calibration layers. Fabrication on cancer treatment recommendations is not a bug to patch – it is a deployment that should not exist without human review.
Any organization still relying on a model’s Knowledge Cutoff as a proxy for accuracy. The leaderboard proved that being current and being correct are different problems entirely.
What Happens Next
Base case (most likely): The two-tier split deepens. Specialized grounding models push even lower on constrained tasks. Frontier models improve on hard benchmarks but remain well above the specialists through 2026. Legal sanctions become routine. Signal to watch: A federal court establishes sanctions an order of magnitude above current maximums. Timeline: Q3 2026.
Bull case: A frontier lab ships a reasoning model that matches the specialized leaders on the hard benchmark while maintaining general capability. The two tiers converge. Signal: A top-5 reasoning model closing the gap with Finix-S1 on the 7,700-article dataset without sacrificing other benchmarks. Timeline: Q4 2026 – Q1 2027.
Bear case: A high-profile medical or legal AI failure causes irreversible harm. Regulatory backlash freezes deployment in those sectors. Signal: A state or federal regulator issues an emergency moratorium on AI in a specific professional domain. Timeline: Any time.
Frequently Asked Questions
Q: Worst real-world examples of AI hallucination in legal and medical systems? A: An Oregon court levied $109,700 in sanctions for fabricated case law in March 2026. In medicine, ChatGPT fabricated non-existent cancer treatments in 12.5% of tested cases, and Whisper showed 50-80% hallucination rates in medical transcription.
Q: Which LLMs hallucinate the least according to Vectara leaderboard 2026? A: As of March 2026 on the harder 7,700-article benchmark, Finix-S1-32B leads at 1.8%, followed by GPT-5.4-nano at 3.1% and Gemini-2.5-Flash-Lite at 3.3%. Old benchmark scores are not comparable.
Q: How is the AI industry solving the hallucination problem in 2026? A: Three tracks: specialized grounding models pushing below 2%, expanded benchmarks testing real-world difficulty, and agentic RAG architectures delivering up to 71% hallucination reduction. Court sanctions are accelerating adoption of verification infrastructure.
The Bottom Line
The hallucination problem did not get solved. It split in two. Constrained summarization is approaching reliability. Complex real-world tasks – legal reasoning, medical recommendations, multi-source synthesis – remain dangerously unreliable. You are either deploying with grounding infrastructure or you are deploying a liability.
Disclaimer
This article discusses financial topics for educational purposes only. It does not constitute financial advice. Consult a qualified financial advisor before making investment decisions.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors