From Cosine Similarity to Anisotropy: Prerequisites and Hard Limits of Sentence-Level Embeddings
Table of Contents
ELI5
Sentence Transformers turn sentences into number vectors so machines can compare meaning. Before using them, you need to understand embeddings, attention, and distance metrics — and know the hard limits that silently cap what these vectors can represent.
Two sentences return near-identical cosine similarity scores. One describes a product feature; the other is a refund complaint. The retrieval system treats both as top matches for the same query — and from the model’s perspective, it isn’t wrong. Those sentences really are geometrically close. The question is why, and the answer lives in prerequisites most tutorials never mention.
The Geometry You Inherit Before Writing a Single Query
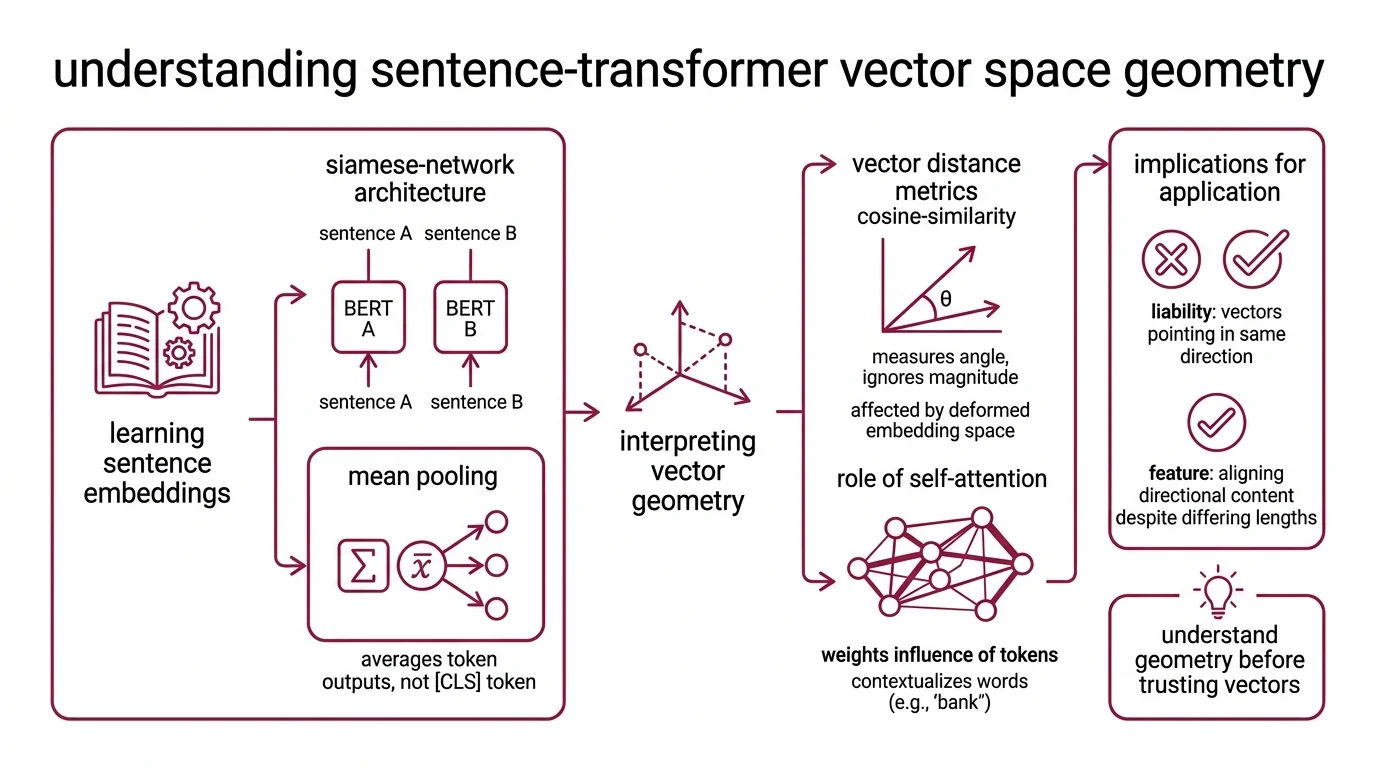
Every Sentence Transformers model hands you a vector — a fixed-length array of floating-point numbers that is supposed to capture what a sentence means. Before trusting that vector with anything consequential, you need to understand three things about the space it inhabits.
What do you need to understand before learning Sentence Transformers: embeddings, attention, and distance metrics?
The foundation is the Embedding itself: a learned mapping from variable-length text to a fixed-dimensional point in continuous space. The original SBERT paper — Reimers & Gurevych (2019) — introduced a Siamese Network architecture that passes two sentences through identical BERT encoders, applies mean pooling over token outputs, and compares the resulting vectors. Mean pooling averages the entire token sequence rather than relying on a single [CLS] token — a design choice that distributes semantic weight across positions instead of concentrating it at one potentially undertrained token. The distinction is not cosmetic; it determines whether the vector captures the full sentence or overfits to a single learned position.
The distance function matters as much as the vector itself. Cosine Similarity measures the angle between two vectors while ignoring magnitude entirely. Two documents of wildly different lengths can land close together if their directional content aligns. That sounds like a feature. It becomes a liability when the embedding space itself is deformed — when most vectors already point in roughly the same direction, regardless of what they encode. More on that geometric pathology shortly.
Attention is the engine underneath. BERT-family models use self-attention to weight which tokens influence the representation of which other tokens within a sequence. This is what makes the embeddings contextual: the word “bank” in “river bank” and “bank account” produces different vectors because attention routes information differently. But attention operates inside a fixed window, and its memory cost scales quadratically with sequence length. Every embedding is a lossy compression, and the parameters of that compression — window size, pooling strategy, attention depth — determine what survives the projection and what gets silently discarded.
These three prerequisites — embedding geometry, distance semantics, attention mechanics — are not background reading. They are the operating constraints of every sentence-level model. The original SBERT architecture reduced pairwise sentence comparison from roughly 65 hours to approximately 5 seconds, Reimers & Gurevych (2019). That speedup made semantic search practical at scale, but the speed was purchased by projecting each sentence into a space with hard geometric constraints that most retrieval pipelines never inspect.
Ceilings Encoded in the Architecture
The limits of sentence-level embeddings are not bugs to be patched. They are direct consequences of architectural decisions made during pre-training, and they constrain every downstream application — from Similarity Search Algorithms to retrieval-augmented generation pipelines.
What are the sequence length limits, domain shift problems, and recall ceilings in Sentence Transformers?
The most visible ceiling is sequence length. BERT’s positional encoding caps at 512 tokens — roughly 300 to 400 English words (SBERT Docs). The widely-used all-mpnet-base-v2 model truncates even earlier, at 384 tokens (SBERT Docs). Anything beyond that boundary gets silently dropped. If a document’s critical argument sits in paragraph twelve and the encoder only sees paragraphs one through five, no amount of index tuning recovers the lost meaning.
Modern embedding models have pushed this boundary considerably. As of March 2026, top-ranked models on the MTEB leaderboard — Gemini Embedding 001, NV-Embed-v2, Qwen3-Embedding-8B — accept 8,192 to 32,768 tokens. But the classic sentence-transformers models still cap at 384–512, and those remain among the most downloaded on Hugging Face. The gap between what people install and what the architecture actually handles is a quiet, persistent source of retrieval failures.
Domain shift is less visible and harder to diagnose. Ábaco et al. (2021) demonstrated that sequence length itself acts as a domain: performance degrades when the length distribution at inference differs from the distribution seen during training. You fine-tune on abstracts, then search over full papers. You train on product titles, then query with paragraph-length descriptions. The model hasn’t encountered a new topic — it has encountered a new shape, and that shape falls outside its learned distribution. The failure looks like a relevance problem. It is a geometry problem.
The recall ceiling is subtler still. Vector Indexing through approximate nearest neighbor algorithms trades exactness for speed, but even with a perfectly configured index, retrieval recall is bounded by the embedding’s capacity to separate relevant from irrelevant documents in vector space. If two semantically distinct documents map to nearby points — because the space is too compressed, too anisotropic, or too domain-mismatched — no index configuration fixes a deformed space. The geometry upstream determines what is findable downstream.
When Every Vector Points the Same Direction
The most counterintuitive failure mode in sentence embeddings is geometric. It has a name — anisotropy — and it means the vectors your model produces are not evenly distributed across the available dimensions. They cluster into a narrow cone, and that cone distorts every distance measurement you compute inside it.
Why do sentence embeddings suffer from anisotropy and representation collapse during training?
Ethayarajh (2019) measured the geometry of BERT, ELMo, and GPT-2 representations and found that all layers of BERT are anisotropic: embeddings occupy a narrow cone rather than spreading uniformly across dimensions. Upper layers are the most affected. Less than 5% of the variance in contextualized representations is explained by a static embedding, Ethayarajh (2019) — confirming that the representations are genuinely context-sensitive. But that context-sensitivity coexists with a space that concentrates its expressive range in a small geometric region.
The mechanism is straightforward once you see it. During pre-training, BERT optimizes masked language modeling: predict the missing token given its surrounding context. This objective does not require vectors to be uniformly distributed. It only requires that the model produce correct probability distributions over the vocabulary at each masked position. The geometry of the embedding space is a side effect, not a design target — and the side effect crowds representations together in ways that make cosine similarity progressively less discriminating. Two unrelated sentences can score high not because they share meaning, but because the cone they share is narrow enough to make every angle small.
Contrastive Learning offers the most studied repair. Gao et al. (2021) demonstrated with SimCSE that contrastive objectives regularize the embedding space toward uniformity: push positive pairs closer together, push negative pairs apart, and the narrow cone opens up. Their unsupervised approach — using dropout as minimal data augmentation to prevent representation collapse — achieved 76.3% average Spearman correlation on STS benchmarks with BERT-base; the supervised variant reached 81.6%, Gao et al. (2021). The improvement is real, but the mechanism is worth understanding: contrastive training reshapes the geometry itself, not the similarity function applied to it.
The story is less settled than it sounds. Recent work has questioned whether isotropy is always beneficial — forcing the space into a uniform distribution can destroy native features the model actually needs for specific downstream tasks. The relationship between uniformity and retrieval quality is not monotonic. There is a region where regularizing the geometry too aggressively erases the very distinctions the embedding was trained to make.
Not a simple fix. A trade-off surface.
What the Geometry Predicts for Your Pipeline
If you switch pooling from CLS to mean pooling on an off-the-shelf model, expect measurable improvement in similarity tasks — you are distributing the representational burden across all token positions instead of relying on a single one.
If you feed documents longer than the token limit without chunking, expect silent truncation. The model will not warn you. It will embed a prefix and discard the rest.
If you fine-tune on short text and then search over long documents, expect domain shift even when the topic stays constant. Length is a distributional feature the model has internalized, and violating it degrades recall in ways that look like relevance failures but are really geometric misalignment.
If you rely on cosine similarity in a highly anisotropic space, expect elevated baseline similarity between unrelated pairs. When vectors crowd into a cone, the angle between any two of them shrinks — not because they are semantically close, but because the space itself is malformed. Multi Vector Retrieval approaches, which represent each document as multiple vectors rather than a single point, can partially mitigate this by preserving finer-grained structure that single-vector compression loses.
Rule of thumb: Check the cosine similarity distribution of random sentence pairs in your embedding space before tuning anything else. If the median random-pair similarity sits unexpectedly high, your space is likely anisotropic enough to cap retrieval quality regardless of your reranker or index.
When it breaks: The hardest failure occurs when anisotropy and domain shift compound. A model trained on one domain, applied to another, with sequence lengths outside the training distribution, produces vectors that are simultaneously crowded and misaligned — and cosine similarity becomes nearly uninformative. No similarity search configuration recovers from a space where relevant and irrelevant documents are geometrically indistinguishable.
The Data Says
Sentence-level embeddings are geometry — and geometry has constraints that no prompt or index parameter can override. The prerequisites are real: without understanding attention windows, pooling trade-offs, and distance metrics, you cannot diagnose why retrieval fails. The hard limits are equally real: sequence length truncation, domain shift from length mismatch, and anisotropic collapse are architectural features, not configuration errors. Inspect the space before optimizing anything downstream.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors