Agent Memory Architectures: Prerequisites and Hard Limits
Table of Contents
ELI5
Agent memory is not a bigger context window. It is a system of tiers, retrievers, and graphs that decide what an agent should remember, what it should retrieve right now, and what it should let decay.
A team builds a coding assistant. It has a million-token context window, perfect recall within a session, and a confident answer for every question. After three weeks of customer use, it still cannot remember that one specific user prefers tabs over spaces. The context window did not shrink. The memory was simply never there.
This is the gap that Agent Memory Systems are designed to close. Bigger windows do not produce continuity; they produce expensive forgetting.
Why Memory Is Not the Same as Context
The context window is short-term memory with a hard cliff at the token boundary. Once the conversation rolls past that boundary, the model has no awareness it ever existed. Memory systems are the subsystem that decides what gets pulled back across that cliff and in what form.
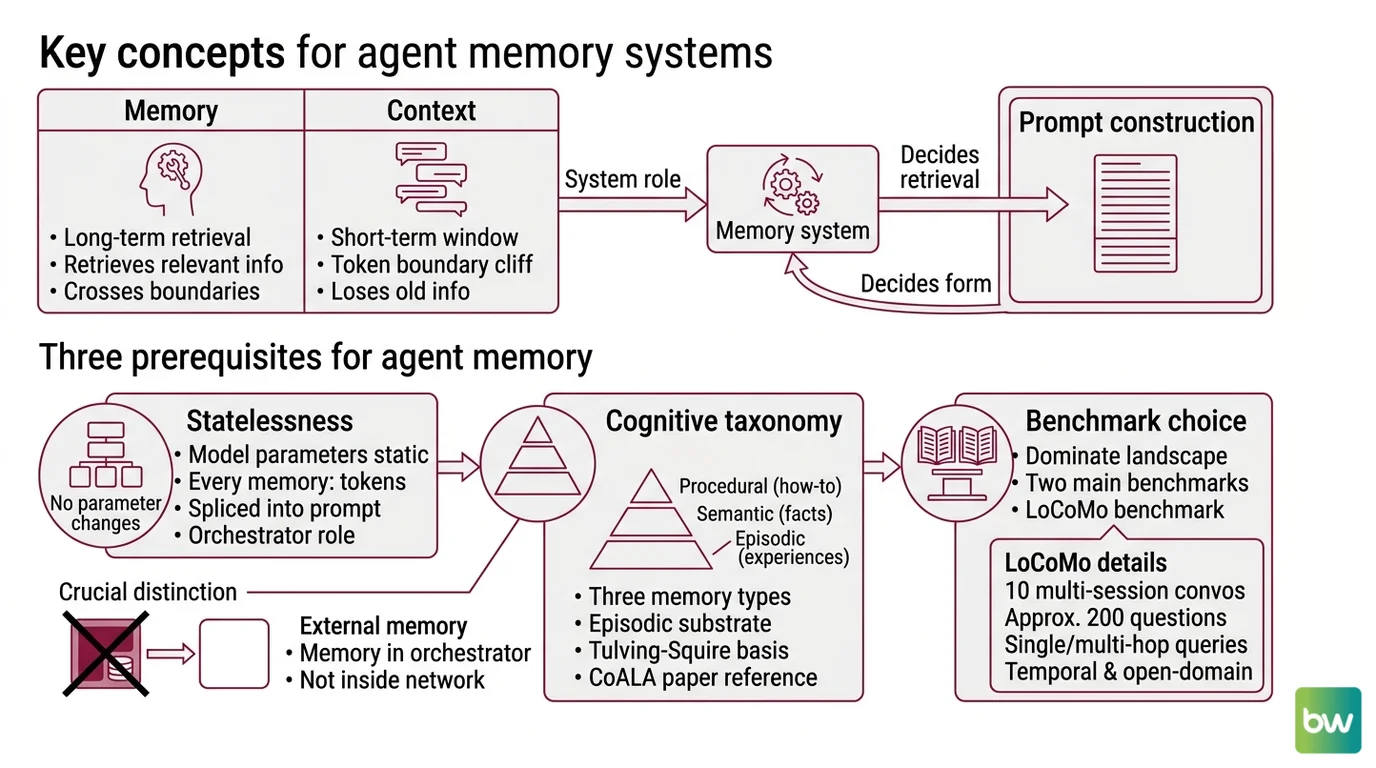
Before any architectural comparison makes sense, three distinctions need to be in place — what kind of memory is being stored, where it lives in the inference loop, and how it gets retrieved.
What do you need to understand before learning agent memory systems?
Three prerequisites, in this order.
Statelessness comes first. A MemGPT-style architecture is not “teaching” the LLM anything new. The model parameters do not change between turns. Every “memory” is a string of tokens that the orchestrator splices into the prompt at inference time.
Not weights. Tokens.
This sounds obvious. It is the source of most confused architecture diagrams — diagrams where memory is drawn as something happening “inside” the model, when in fact memory lives in the orchestrator, not in the network.
The cognitive taxonomy comes second. Cognitive science distinguishes three memory types — episodic (what happened, when), semantic (general facts), and procedural (how to do things). Tulving’s original split, plus Squire’s procedural memory work from 1987, was ported to LLM agents in the CoALA paper (Atlan summary). Episodic Memory stores instance-specific past interactions; semantic and procedural memories are abstractions built on top of that episodic substrate. Treating “memory” as one undifferentiated bucket is the fastest way to build a system that retrieves the wrong thing at the wrong time.
Benchmark choice comes third. Two benchmarks dominate the 2026 landscape. The Locomo Benchmark ships ten multi-session conversations with around 200 questions covering single-hop, multi-hop, temporal, and open-domain queries (LoCoMo paper). LongMemEval curates 500 questions across five abilities — information extraction, multi-session reasoning, knowledge updates, temporal reasoning, and abstention. LongMemEval’s headline finding is that commercial chat assistants and long-context LLMs show roughly a 30% accuracy drop on memorizing information across sustained interactions (LongMemEval paper). Picking the wrong benchmark is how vendors end up “winning” tasks their users do not actually have.
These three together — stateless inference, the cognitive taxonomy, and the benchmark target — are the foundation. Architectures only make sense once those are settled.
Three Architectural Bets, One Shared Substrate
Most production memory systems in 2026 are making one of four bets about where memory should live and how to retrieve it. The bets are not mutually exclusive — many stacks combine two — but the dominant flavor changes the failure modes you inherit.
The first bet is OS-style tiering. Letta (which absorbed the standalone MemGPT runtime — the “MemGPT” name now refers to both the 2023 origin paper and the agent type inside Letta) keeps three tiers: Core Memory living in-context like RAM, Recall Memory as searchable conversation history, and Archival Memory as long-term storage queried through tools (Letta Docs). The agent itself decides what to page in and out. The analogy is precise: it is virtual memory for an LLM, and the page faults are paid in latency.
The second bet is token-efficient extraction. Mem0 treats every conversation as raw substrate from which a small set of stable “memories” gets distilled, indexed, and retrieved on demand. The Mem0 paper and accompanying vendor blog report 91.6% on LoCoMo and 93.4% on LongMemEval with the token-efficient algorithm, pulling roughly 7,000 tokens per retrieval against a baseline that loaded full context. The vendor-reported latency drop is large — 1.44s p95 versus 17.12s for full-context retrieval, with about a six-percentage-point accuracy trade-off compared to dumping everything in (Mem0 Blog).
The third bet is temporal knowledge graphs. Zep, built on the Graphiti engine, models facts as graph edges where every edge carries a validity interval — when the fact became true, and when it was superseded. Where Mem0 collapses memories into stable facts, Zep keeps the timeline intact and lets the agent ask “what did the user prefer last week?” without retrieving every interaction in between. Zep paper-reports 94.8% on Deep Memory Retrieval and a P95 retrieval latency around 300ms via hybrid semantic + BM25 + graph traversal (Zep paper).
The fourth bet is the file-system bet. ByteRover stores memory as a markdown-file Context Tree — no vector database, no graph database, no embeddings service required. The vendor-reported numbers are 96.1% overall accuracy on LoCoMo and 92.8% on LongMemEval-S at roughly 1.6s in production conditions (ByteRover Blog). Treat all of these claims with the appropriate caveat: every vendor in this list publishes their own benchmark configuration, and there is no neutral 2026 leaderboard comparing all architectures on identical hardware and prompts. “State of the art” is a set of overlapping, vendor-controlled claims, not a settled ranking.
The remaining mainstream options sit closer to specific stacks. Supermemory runs a vector-graph engine with hybrid vector + BM25 search at sub-300ms and integrates well with MCP-based clients. Langmem is the LangChain SDK for long-term memory primitives — Memory Managers, Prompt Optimizers, episodic and procedural types built on the LangGraph store; it is primarily designed for LangGraph and offers limited value outside that stack, so it is best treated as part of a LangGraph commitment rather than an independent architectural choice.
The shared substrate underneath all four bets is the same. A retrieval step selects a small number of tokens to splice back into the prompt at inference time. The differences are in what gets stored, what gets indexed, and how decay is modeled — not in whether the LLM has changed.
Where Every Architecture Hits the Wall
A retrieval-based memory system can only return what it stored, and it can only store what its extraction pipeline decided was worth storing. That filter is where every architecture leaks.
What are the technical limitations of agent memory systems?
Three classes of limitation show up regardless of which architectural bet you make.
The first is staleness with confidence. Highly-retrieved memories — the ones the system surfaces most often — drift toward becoming “confidently wrong” rather than just outdated, because they keep winning the relevance race even after the underlying fact has changed (Towards Data Science). Detecting when a high-relevance memory has gone stale is an open research problem. Temporal graphs like Zep address it explicitly with validity intervals, but only for facts that the extraction pipeline modeled as facts in the first place. Anything stored as semantic gist loses its timestamp the moment it is summarized.
The second is the retrieval-reasoning trade-off. Training models for stronger reasoning via reinforcement learning has been observed to increase tool-hallucination rates in lockstep with task gains (Asanify report). The same capability that makes an agent better at deciding which memory to retrieve also makes it more likely to invent a memory that does not exist. Stronger agents do not eliminate this; they shift where the failure surfaces — from “did not retrieve the right memory” to “retrieved a memory that was never stored.”
The third is context degradation under sustained interaction. Long conversations exhibit memory drift and attention weakening — the model’s ability to focus on the most relevant tokens within its working window erodes as the window fills (Oracle Developers). Selective forgetting and compression are treated as features, not bugs; the question is whether your compression policy keeps the right things. The 30% accuracy drop LongMemEval measures on commercial assistants is the empirical signature of this failure mode at scale.
These three failure modes are not independent. A staleness problem looks like a hallucination, which looks like context degradation, depending on which layer you instrument first.
Rule of thumb: Pick your architecture based on the temporal structure of your data, not on the leaderboard number. Conversational preference data fits token-efficient extraction; evolving relationships and timelines fit temporal graphs; long-running stateful tasks fit OS-style tiering.
When it breaks: Memory systems fail predictably when the most-retrieved memory is also the most stale one. The relevance signal and the freshness signal are weakly correlated, and no production architecture has cleanly decoupled the two at scale.
The Data Says
Agent memory in 2026 is not one architecture winning over another; it is four different bets — tiered, token-efficient, temporal-graph, and file-tree — each posting vendor-reported numbers on overlapping benchmarks. The roughly 30% accuracy drop LongMemEval measures on commercial assistants is a ceiling that no single architecture has cleanly broken. The interesting work is happening at the failure-mode boundary, not the leaderboard.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors