From Context Windows to Speculative Decoding: Prerequisites and Technical Limits of Inline Code Completion
Table of Contents
ELI5
Inline AI code completion is autocomplete that finishes whatever you are typing. It works because the model sees the code before and after your cursor, runs it through a tokenizer, and predicts the most likely next characters under a tight latency budget.
You import a helper you wrote yesterday and the completer suggests a function name that does not exist. Same session, ten minutes later, it produces a 30-line method body that is structurally perfect and uses the obscure constant from a sibling file you never opened. Same model, opposite behaviors. The interesting question is not “is it smart” — it is “what changed between those two keystrokes.”
The answer is not in the model. It is in four prerequisites that sit underneath every AI Code Completion system: how your code is sliced into tokens, how much surrounding text reaches the GPU, how the model was trained to fill a gap, and how few milliseconds the serving stack has to respond before you notice lag. Each prerequisite explains one of the failure modes you already see. None of them is a bug.
The Four Prerequisites Hiding Inside Every Keystroke
Before the model assigns a probability to a single character of your suggestion, four things have already happened. They happen in order. Each one constrains what is possible at the next step, and each one leaks into the suggestions you accept and the ones you reject.
What do you need to understand before AI code completion: context windows, tokenization, and latency budgets?
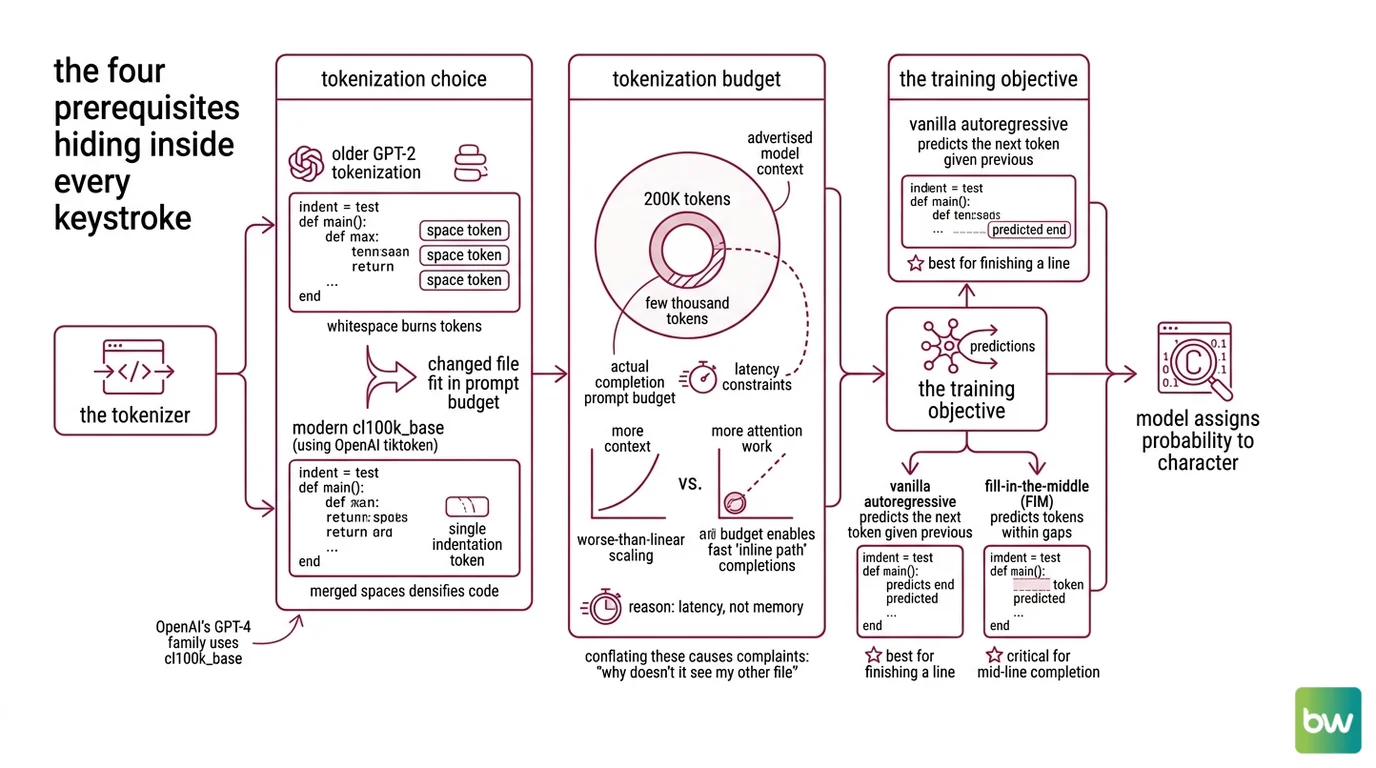
The first prerequisite is the tokenizer. Code does not enter the model as characters; it enters as integers, drawn from a fixed vocabulary the tokenizer learned during pre-training. OpenAI’s GPT-4 family uses cl100k_base, a byte-level BPE scheme with a vocabulary of 100,256 tokens (OpenAI tiktoken). The choice of tokenizer is not cosmetic. Older GPT-2 tokenization treated each space as its own token, so a block of indented Python burned tokens on whitespace. cl100k_base merges runs of spaces into single tokens, which densifies code and meaningfully changes how much of your file fits in a given prompt budget.
This is where the second prerequisite enters: the Tokenization budget the completer actually spends per keystroke is much smaller than the advertised model context. A vendor can ship a model with a 200K-token context and route only a few thousand tokens into the inline path. Cursor Tab, for example, uses roughly 2K–4K tokens per completion request even when the underlying model advertises 200K (Morph LLM analysis). The reason is latency, not memory — more context means more attention work, and attention work scales worse than linearly. The “completion prompt budget” and the “model context window” are not the same number, and conflating them is the source of most “why doesn’t it see my other file” complaints.
The third prerequisite is the training objective. A vanilla autoregressive language model predicts the next token given the previous tokens — useful for finishing a line, useless for completing in the middle of a function where there is code on both sides of the cursor.
Fill-in-the-Middle (FIM), introduced by Bavarian et al. (2022), solves this with a data transformation: during pre-training, take a fraction of documents, cut them into prefix–middle–suffix, and reassemble them as prefix–suffix–middle. The model still trains left-to-right, but it learns that when it sees a <suffix> token followed by a <middle> marker, the right move is to produce a span that bridges what came before and what comes after. The headline finding is that this can be done without hurting left-to-right perplexity — “FIM-for-free.” FIM is now the standard pre-training objective for StarCoder, DeepSeek-Coder, and Code Llama (Bavarian et al. (2022)).
The fourth prerequisite is the latency budget. Inline completion is a human-loop interface; if a suggestion arrives 400ms after you stop typing, your fingers have already moved on. “Sub-100ms p99” is the figure you see in product copy, though there is no single canonical source for it — treat it as the target shape of the budget, not a published industry standard. The serving stack pays for it with techniques like Speculative Decoding, introduced by Leviathan et al. (2022): a small draft model proposes a short sequence of tokens, the large target model verifies them in a single forward pass, and accepted tokens are emitted in batches instead of one at a time. The reported speedup on T5-XXL is 2X–3X with no change to the output distribution (Leviathan et al. (2022)). For inline completion, this is the difference between a suggestion you wait for and a suggestion that appears already typed.
The four prerequisites are not optional ingredients — they are the only knobs the system has.
Why the Suggestion Is Wrong
Once you see what the completer actually sees, the failure modes stop looking random. Each common complaint maps cleanly to one of the prerequisites above.
Why does AI code completion hallucinate APIs, miss repo context, and degrade on long files?
Hallucinated APIs — suggesting requests.get_json() when the library only exports requests.get().json() — are mostly a knowledge-acquisition problem. The model assigns high probability to a function signature that is statistically plausible given everything else it has seen, but the actual library API was either absent from training, ambiguous across versions, or overridden by a more frequent pattern from a different library. A 2025 taxonomy from Zhang et al. (Zhang et al., PACMSE 2025) groups the root causes into four buckets: training data quality, intention understanding, knowledge acquisition, and repository-level context awareness. Hallucinated APIs sit in the knowledge bucket. The model is not lying; it is sampling from a prior that does not know your package.json.
Missed repo context is the second bucket lighting up. Your utils/db.py defines a function the completer should clearly use, but the suggestion ignores it and reinvents a worse version inline. The cause is mechanical: that file is not in the prompt. With a 2K–4K-token effective budget, the completer cannot send your whole repo to the model on every keystroke, so it relies on retrieval — pulling the most relevant snippets from elsewhere in the codebase and pasting them into the prompt. RepoCoder is one of the most-cited approaches here, using iterative retrieval-then-generation (Zhang et al., PACMSE 2025); CatCoder and graph-based methods are alternatives. When retrieval is wrong, the model produces a fluent answer about a world that does not include your helper. The hallucination is downstream of a retrieval miss, not a reasoning failure.
Degradation on long files is the third symptom, and it is where context length stops being free. Even when the budget is generous, attention does not weight all tokens equally — relevant signals near the top of a 1,800-line file can be diluted by everything between them and the cursor. The Babble model that powers Cursor Tab post-acquisition advertises a 1,000,000-token context with sub-10ms inference targets (Supermaven Blog), but a large context only helps when the model can actually pick the right tokens out of it. Past a certain length, more context can hurt, because attention dilution makes the relevant information harder to find rather than easier.
Each of these failure modes is a consequence of the prerequisites, not a deviation from them. The completer is doing exactly what its training and serving stack permit — no more, and no less.
What the Prerequisites Predict
The point of naming the prerequisites is not taxonomy. It is prediction. Once you know which knob controls which behavior, you can read the symptoms of any inline completer and make educated guesses about what to do next.
- If you change tokenizers and your average tokens-per-line drops, expect to fit more relevant context into the same prompt budget — and expect suggestion quality on indented languages (Python, YAML) to improve more than on dense ones (minified JS).
- If you raise the effective prompt budget without changing the retrieval strategy, expect suggestions to get marginally better on small files and noticeably worse on very long ones, because attention dilution scales faster than naive intuition predicts.
- If you switch a completer to a FIM-trained backbone, expect “completion in the middle of a function” to improve sharply and “completion at end-of-line” to stay roughly the same — FIM helps where there is suffix context, not where the cursor sits at the tail.
- If a vendor reports decoding-time speedups (35% latency reduction and 3x token-per-second throughput, plus a 12% higher acceptance rate and 20% more accepted-and-retained characters versus their prior baseline, per GitHub Blog), expect the accept rate to rise from latency alone, not just from a smarter model. Faster suggestions get accepted more often because the human has not yet moved on.
Rule of thumb: when an inline completer disappoints, ask which prerequisite leaked — tokenizer, prompt budget, training objective, or latency — before asking whether the model is “good.”
When it breaks: the architecture’s hardest limit is the gap between advertised model context and effective completion budget. A 1M-token model that can only spend 4K per keystroke will keep missing repo context unless retrieval does the work that the context window cannot — and retrieval has its own ceiling.
Security & compatibility notes:
- Supermaven (standalone) discontinued: Standalone VS Code, JetBrains, and Neovim extensions were sunset on November 30, 2025, following Anysphere’s acquisition on November 12, 2024 (TechCrunch). The 1M-context Babble lineage now lives only inside Cursor Tab. Action: migrate any pinned IDE configs off the standalone extensions.
- GitHub Copilot billing change: Moved to usage-based (premium request) billing in 2026 (GitHub Blog (billing)). Older “unlimited completions” framing is outdated. Action: re-check seat economics before scaling team adoption.
The Data Says
Inline AI code completion is a layered system, not a model. Hallucinated APIs trace to training data, missed repo context traces to prompt budget and retrieval, long-file degradation traces to attention dilution, and latency-driven UX traces to decoding tricks like speculative decoding. The 2026 leaders — Cursor Tab on the post-acquisition Babble lineage, GitHub Copilot on its custom completion model — are converging on the same playbook because the prerequisites leave no other path.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors