From Context Vectors to Cross-Attention: How Encoder-Decoder Design Overcame the Bottleneck Problem
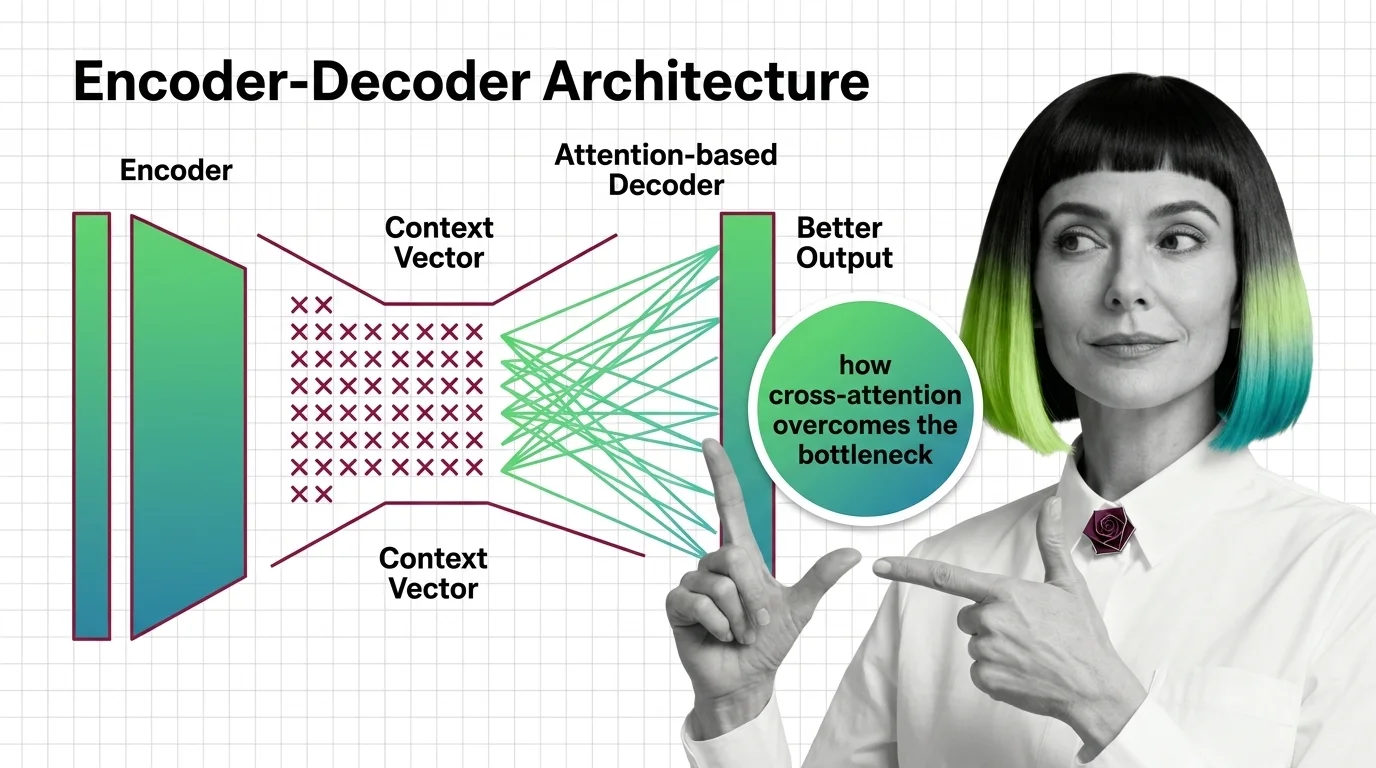
Table of Contents
ELI5
Encoder-decoder models compress input into a representation, then generate output from it. The bottleneck — losing information in compression — was solved by attention, which lets the decoder look back at every encoder position instead of one fixed vector.
In 2014, a neural network translated English to French at 34.8 BLEU — competitive with a decade of hand-tuned phrase-based systems — using nothing but an LSTM that read a sentence, compressed it into a vector, and generated the translation from that vector alone (Sutskever et al.). No explicit grammar. No alignment tables. No linguistic features.
And yet, performance collapsed on sentences longer than about twenty words.
The same compression that made the model elegant was silently destroying information. That failure pattern — invisible on short inputs, catastrophic on long ones — is the thread that pulled the entire field toward attention.
The Fixed-Length Funnel That Broke on Long Sentences
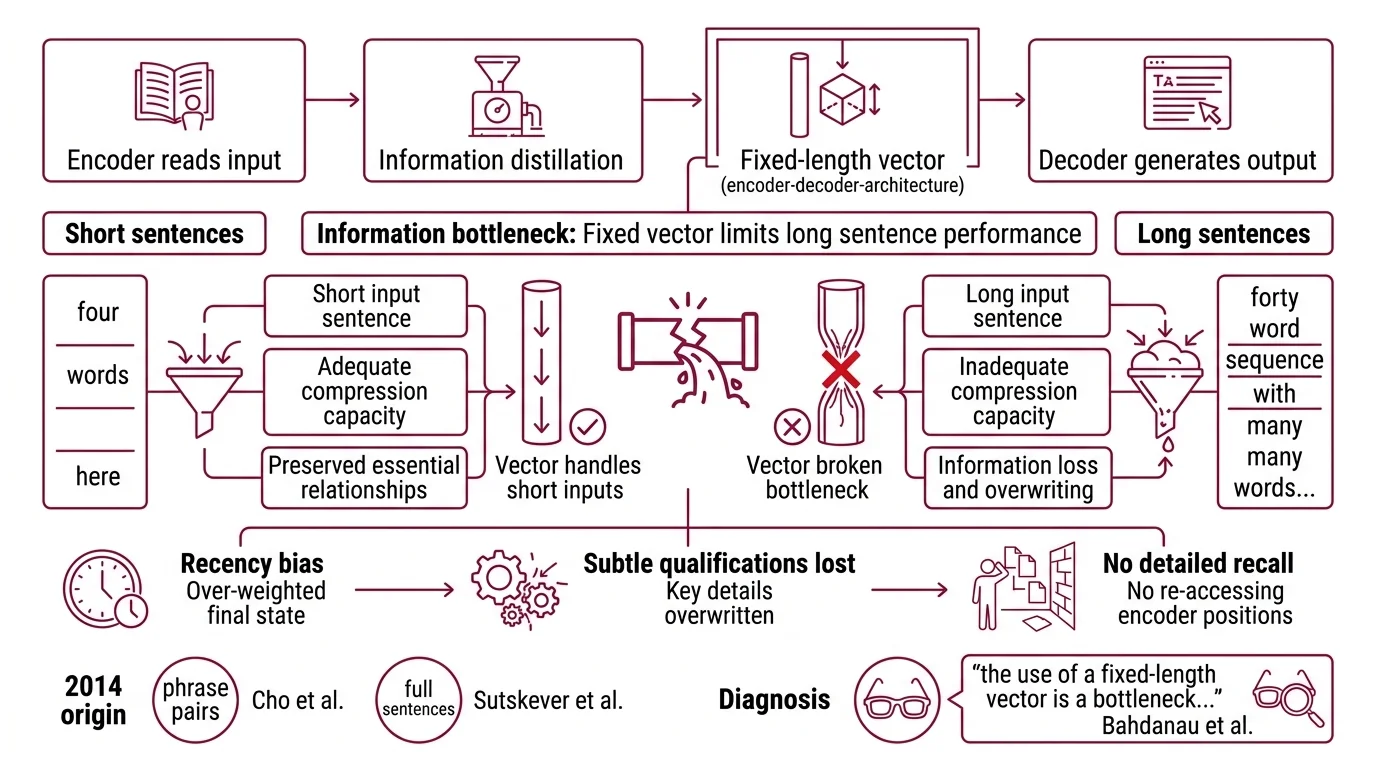
The Encoder Decoder Architecture in its original form works like a two-stage pipeline. The encoder reads the entire input sequence — word by word, position by position — and distills it into a single fixed-dimensional vector. The decoder then generates the output sequence conditioned on that vector, one token at a time.
This design was introduced almost simultaneously by two groups in 2014. Cho et al. coined the term “encoder-decoder” and demonstrated it with a pair of RNNs jointly trained on phrase pairs. Sutskever et al. showed that an LSTM encoder-decoder could handle full sentences, achieving that 34.8 BLEU score on WMT'14 English-to-French.
The elegance was real. The limitation was structural.
What is the information bottleneck problem in encoder-decoder models and why does it limit performance?
The bottleneck is geometric. A sentence of forty words and a sentence of four words must both be compressed into the same fixed-dimensional vector — typically a few hundred or a thousand floating-point numbers. For short sentences, that vector has enough capacity to preserve the essential relationships between words. For long sentences, it does not.
The diagnosis was precise: “the use of a fixed-length vector is a bottleneck in improving the performance of this basic encoder-decoder architecture” (Bahdanau et al.). The encoder’s final hidden state had to serve as a summary of everything the model had read; the decoder had no way to reach back and inspect individual positions.
Think of it as trying to recall an entire lecture from a single Post-it note. The note was written at the end of the lecture — so it carries a recency bias. The opening arguments, the middle examples, the subtle qualifications? Compressed, overwritten, or lost.
The information didn’t vanish because the model was weak. It vanished because the architecture imposed a geometric constraint: all input information had to pass through a fixed-width channel, regardless of how much information existed.
The symptom was measurable. Translation quality degraded systematically as source sentence length increased. Not randomly — systematically. That is the signature of a structural limit, not a training problem.
What is the difference between the fixed context vector approach and attention-based encoder-decoder models?
In the fixed-context approach, the decoder receives one vector — the encoder’s final hidden state — and that is all it gets. Every decoding step operates from the same compressed summary. The decoder cannot ask “what did the encoder see at position seven?” because position seven has been folded into the same fixed-width vector as every other position.
The Attention Mechanism changed the contract entirely.
Instead of compressing all encoder states into one summary, attention preserves all of them. At each decoding step, the decoder computes a weighted combination of all encoder hidden states — a dynamic summary that shifts depending on what the decoder is currently generating.
Bahdanau’s formulation used additive attention: the decoder’s current hidden state and each encoder hidden state are passed through a small feed-forward network that outputs an alignment score. These scores are normalized with softmax to produce attention weights — a probability distribution over encoder positions.
Not a static summary. A dynamic query.
The fixed-context model asks: “What was the input about?”
The attention-based model asks: “Which part of the input matters for the word I am generating right now?”
That shift — from a single compressed representation to a per-step weighted retrieval — is what cracked the length barrier. The decoder could now allocate attention to distant positions, recovering information that the fixed-width vector had destroyed. But the attention mechanism still lived inside a recurrent architecture, where each computation depended on the sequential output of the previous step.
The question was whether the alignment principle could survive without recurrence entirely.
How Bahdanau’s Alignment Became the Transformer’s Cross-Attention
Bahdanau’s additive attention operated within the recurrent framework — each attention step depended on the RNN’s sequential hidden state. The Transformer Architecture, introduced by Vaswani et al. in 2017, stripped away recurrence and rebuilt the encoder-decoder around self-attention and cross-attention as its only structural primitives.
How does cross-attention let the decoder access all encoder positions instead of a single context vector?
In a Transformer encoder-decoder, cross-attention works through three projections. The decoder produces queries from its own masked self-attention output. The encoder produces keys and values from its final representation. The decoder’s queries are matched against the encoder’s keys using scaled dot-product attention, and the resulting weights are applied to the encoder’s values.
The geometry is precise: the encoder’s representation is computed once and reused across all decoder layers. Each decoder layer performs a fresh cross-attention computation, meaning each layer can attend to different parts of the input for different reasons — syntactic alignment in one layer, semantic correspondence in another.
This is where the architecture surpasses simple additive attention. Bahdanau’s model had one attention mechanism operating between one encoder and one decoder RNN. The Transformer has multiple heads of cross-attention at every decoder layer, each potentially specializing in a different type of input-output alignment.
The result: 28.4 BLEU on English-to-German and 41.8 BLEU on English-to-French (Vaswani et al.), setting new benchmarks while training significantly faster than recurrent models by enabling parallelism across positions.
The Inheritance Running Through Modern Architectures
The encoder-decoder pattern with cross-attention did not vanish when decoder-only models claimed the spotlight. It persists — and in specific domains, it carries advantages the causal-attention-only architecture cannot replicate.
T5 treats every NLP task as a text-to-text problem, funneling classification, translation, summarization, and question answering through the same encoder-decoder framework. With variants from 60 million to 11 billion parameters, T5 demonstrated that the architecture scales cleanly across parameter budgets (Hugging Face Docs). Bart took a different path: a denoising autoencoder where the encoder processes corrupted text and the decoder reconstructs the original, making it particularly effective for generation tasks like summarization.
Both models inherit the same cross-attention mechanism. The encoder builds a rich, bidirectional representation of the input. The decoder generates output while attending to that representation through cross-attention at every layer. The Teacher Forcing strategy — feeding ground-truth tokens as decoder input during training — remains standard for both, stabilizing the decoder’s learning by preventing error accumulation across long output sequences.
As of December 2025, Google released T5Gemma 2, built on Gemma 3 architecture, supporting multimodal input through SigLIP, a 128K context window, and over 140 languages (Google Blog). T5Gemma 2 merges self-attention and cross-attention into a unified mechanism with tied embeddings — an architectural compression that the original Transformer would not have attempted, but one that only makes sense because the cross-attention principle itself proved durable enough to survive redesign.
The inheritance is clean. From Bahdanau’s additive alignment to the Transformer’s scaled dot-product cross-attention to T5Gemma 2’s merged attention — each generation refined the mechanism without abandoning the core insight: the decoder should be able to ask the encoder about any position, at any step, for any reason.
Where the Architecture Predicts — and Where It Fractures
The encoder-decoder design carries a structural prediction that holds across implementations: if your task has a clear boundary between understanding input and generating output, the two-stack architecture gives the encoder freedom to build a bidirectional representation — something a decoder-only model, constrained to causal left-to-right attention, cannot do.
If you need summarization, translation, or any task where the full input should inform the first output token, the bidirectional encoder provides a representational advantage. If your input is long and your output short, the encoder processes the input in parallel while the decoder generates sequentially — a latency profile that favors encoder-decoder at smaller parameter budgets.
If your task is open-ended generation — conversation, creative writing, code completion — the decoder-only architecture is more natural. There is no clear “input” to encode separately from the “output” to generate; the boundary dissolves.
Rule of thumb: When the input-output boundary is crisp and the input is longer than the output, encoder-decoder wins on representational efficiency; when input and output blur into a continuous stream, decoder-only wins on flexibility.
When it breaks: Encoder-decoder versus decoder-only performance comparisons are scale-dependent. At very large parameter counts, decoder-only models compensate for causal attention limitations with sheer capacity. The encoder-decoder advantage is most pronounced at smaller scales, where the bidirectional encoder provides representational efficiency that raw parameter count alone cannot replace. Treating a benchmark result from one parameter range as a universal verdict is the most common misreading of the architecture comparison literature.
The Data Says
The encoder-decoder bottleneck was never a failure of training or data. It was a failure of geometry — forcing variable-length meaning through a fixed-width channel. Attention did not add intelligence to the architecture; it removed a constraint. Cross-attention is that removal made systematic, and every model built on it — from T5 to T5Gemma 2 — is proof that the principle survived each paradigm shift the field threw at it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors