From CNN Intuition to Data Hunger: Prerequisites and Hard Limits of Vision Transformers
ELI5
A ** Vision Transformer** cuts an image into fixed-size patches, treats each patch as a token, and runs an ordinary language-model transformer over the sequence. No convolutions, no pooling — just attention over image pieces.
In 2020, a team at Google took a language-model architecture, sliced images into 16×16 patches, threw out every convolution, and asked the network to sort it out. The paper was titled “An Image is Worth 16x16 Words” and the result was both embarrassing and revelatory — on ImageNet-1K the naïve transformer lost to a five-year-old ResNet, but on JFT-300M it pulled ahead (Dosovitskiy et al.). The entire ViT literature since then lives inside that cliff, and understanding why the cliff exists is the only way to read it.
The Mental Models You Need Before ViT Makes Sense
ViT does not reinvent perception; it borrows the NLP transformer and swaps tokens for patches. If your intuition is CNN-shaped, half of ViT will feel obvious and the other half will feel wrong.
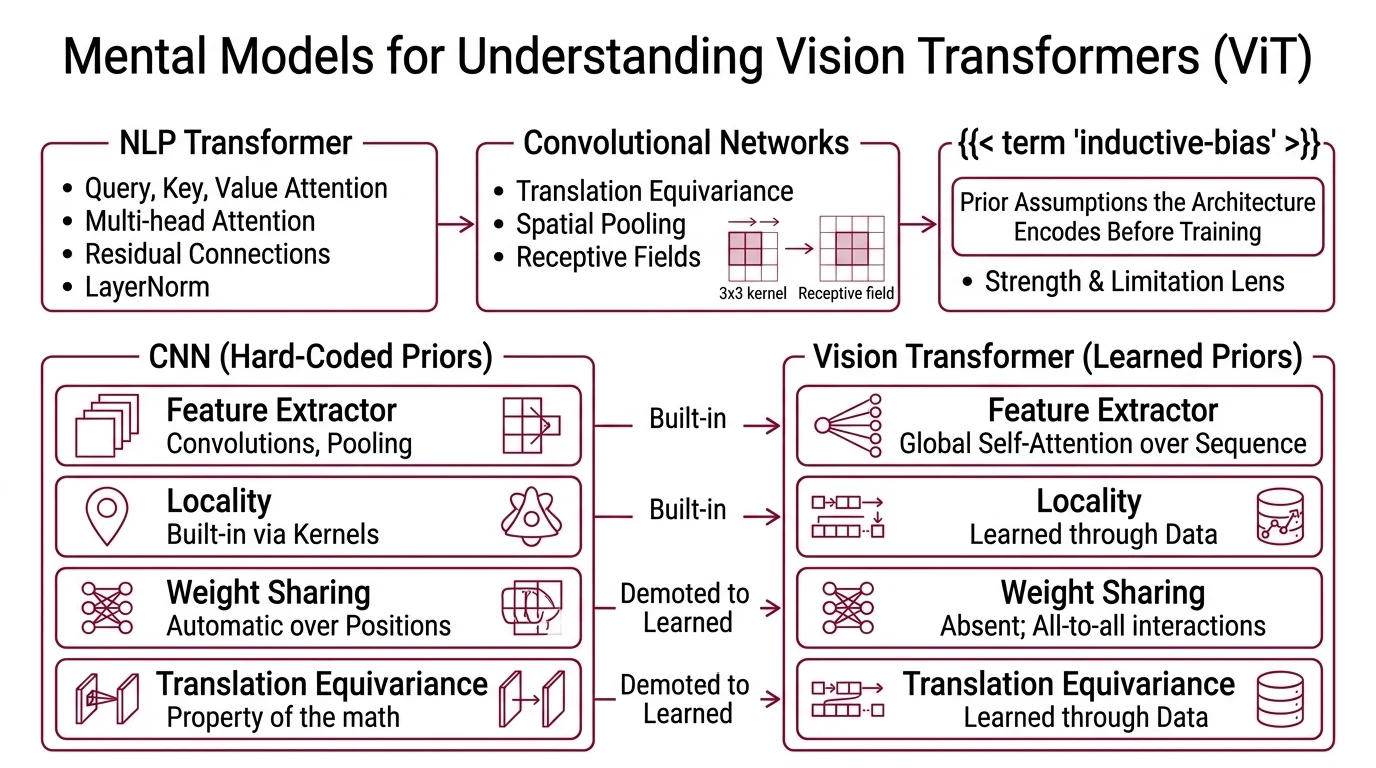
The disconnect lives in a single technical word: inductive bias.
What should I learn before studying Vision Transformers?
Three background threads, in order.
First, the NLP transformer — query, key, value attention; multi-head attention; residual connections with LayerNorm. ViT uses the same encoder with almost no modification; the only image-specific additions sit at the input (patching) and the output (classification head). If you cannot sketch a transformer block from memory, stop here and come back.
Second, convolutional networks — enough to understand translation equivariance, spatial pooling, and receptive fields. You do not need to build a ResNet from scratch. You do need to feel, in your hands, why a 3×3 kernel repeated twelve times eventually “sees” a much larger region of the input.
Third, Inductive Bias. This is the concept ViT papers invoke constantly and rarely explain. An inductive bias is a prior assumption the architecture encodes before it sees any training data. CNNs assume “features are local” and “features repeat across position.” A pure ViT assumes almost nothing about spatial structure, and that single shift is the lens through which every strength and every limitation of the architecture becomes readable.
How do convolutional neural network concepts map to ViT?
The mapping is direct, but every correspondence is also a demotion of a built-in prior into a learned one.
In a CNN, the feature extractor is a stack of convolutions with pooling — locality is hard-coded, weight sharing across positions is automatic, and translation equivariance (up to stride and pooling) is a property of the math itself. In ViT, the feature extractor is global self-attention over a flat sequence of patches. Each 16×16 patch becomes a single token through one linear projection; this Patch Embedding step replaces the entire convolutional stem (Dosovitskiy et al.). The two-dimensional grid disappears into a one-dimensional sequence of patch vectors, joined by a learnable Class Token — the [CLS] token prepended to the sequence, whose final representation becomes the image embedding used for classification.
What a CNN gets for free, a pure ViT must learn from data:
- Locality — in a CNN, every neuron sees a bounded receptive field. In ViT, attention connects every patch to every other patch from the very first layer. The network discovers, through gradient descent, that nearby patches are usually more relevant than distant ones.
- Translation equivariance — a CNN responds identically to a cat shifted five pixels to the right (approximately; pooling and strides break perfect equivariance). ViT only approximates this, through learned 1D positional embeddings that tell it where each patch sits in the grid.
- Weight sharing across positions — a convolution applies the same filter at every spatial location. ViT’s attention uses the same query, key, value projection matrices for every token, which is a weaker cousin of the same prior.
ViT trades architectural priors for architectural flexibility. What the architecture loses in sample efficiency, it gains in the ability to route information globally from the first layer — which is the thing attention was designed to do.
Where ViT Breaks: Data Hunger and Attention Cost
Every inductive bias is a form of compressed experience. Removing priors is not free; the data has to carry the weight the architecture no longer carries. This shows up in two measurable places — the scale of pretraining required for competitive accuracy, and the computational cost of attention at high resolution.
Why do Vision Transformers need massive datasets to outperform CNNs?
The original ViT paper made the trade explicit. Pretrained on ImageNet-1K (~1.3M images), plain ViT underperforms a well-tuned ResNet of similar compute. Pretrained on ImageNet-21k (~14M images, 21,000 classes), the two become competitive. Pretrained on JFT-300M, a Google-internal corpus of about 300M labeled images, ViT finally pulls clearly ahead (Dosovitskiy et al.).
This is the data cliff that gave ViT its “data-hungry” reputation.
The mechanism is the inductive-bias argument in reverse. A ResNet enters training already believing that nearby pixels are related; it only has to learn which relationships matter. A pure ViT enters training believing almost nothing; it has to learn both which patches are related and which relationships matter. With fewer training images, the model has no budget to learn the first problem — so it fails on the second one too.
Three workarounds broke the cliff, each by re-injecting bias from a different direction.
- Distillation — the DeiT recipe pairs ViT with a CNN teacher and adds a second “distillation token” to the input sequence. ViT-B trained this way reaches about 83% top-1 on ImageNet-1K using only the ~1.2M native images, no external corpus (Touvron et al.). The CNN’s locality prior leaks into the student through the distillation loss.
- Better recipes on mid-scale data — the AugReg study showed that heavy augmentation and strong regularization on ImageNet-21k match JFT-300M-level performance with roughly 25× less data (Ridnik et al.). The lesson: the original 300M number was partly a data-quantity problem and partly a training-recipe problem.
- Self Supervised Learning — Masked Autoencoders mask about 75% of patches and train an asymmetric encoder-decoder to reconstruct them. With no labels at all, ViT-Huge reaches roughly 88% ImageNet-1K top-1 after linear probing (He et al.). The reconstruction objective forces the network to build local and global structure simultaneously, which is exactly the bias the pure architecture does not ship with.
The “ViT needs 300M images” headline is true only for the original plain-ViT recipe. Distillation, self-supervision, and aggressive augmentation each break the rule in a different way — which is why modern open-weight backbones like DINOv2 (now succeeded by DINOv3, trained on about 1.7 billion images with a 7-billion-parameter ViT teacher and a new Gram-anchoring objective, per Meta AI Blog) and SigLIP ship as frozen feature extractors without asking practitioners to replicate JFT-300M.
What are the quadratic attention cost and high-resolution limits of ViT?
Global self-attention scales as O(N²) in the number of tokens, where N = (H × W) / P² for an H × W input image with patch size P (QT-ViT, NeurIPS 2024). Doubling the image side at a fixed patch size quadruples the token count — which means attention FLOPs and attention memory both grow roughly 16-fold.
This is why a 224×224 ViT-B/16 trains on a single workstation and a 1024×1024 plain ViT does not train at all on most hardware. The attention matrix itself is N × N entries per head, per layer; at 224×224 with 16×16 patches that is 196 tokens, which is comfortable, but at 1024×1024 it is 4,096 tokens and millions of attention entries per head per layer. Memory dominates before FLOPs do — the activations needed for backpropagation outstrip GPU memory long before the forward pass becomes slow.
Three classes of workaround dominate modern high-resolution vision.
- Windowed attention — the Swin Transformer restricts self-attention to non-overlapping local windows and shifts the windows between layers, restoring linear complexity in image size while preserving cross-window information flow. It is the reference hierarchical ViT for detection and segmentation.
- Linear and kernelized attention — approximations that replace the softmax with a factorable kernel, trading exactness for linear scaling in token count. QT-ViT is one recent example; the family is large and still evolving.
- Alternative sequence models — State Space Model backbones of the Mamba family, and sparse variants that pair ViT with Mixture Of Experts routing, promise attention-level modeling without the quadratic cost. None has yet displaced hierarchical ViTs as the default for dense prediction.
High-resolution ViT hits a memory wall before it hits a compute wall. If your inputs are 512×512 or larger, plan on a hierarchical variant, sparse attention, or a non-transformer backbone from the start — retrofitting is more painful than choosing correctly at the beginning.
What the Mechanism Predicts — and Where It Breaks
Once you hold the two mechanisms — missing inductive bias and quadratic attention cost — the catalogue of ViT variants stops looking like a zoo of random designs and starts looking like a small set of engineered responses to the same two problems.
If you change the input resolution, expect attention cost to scale quadratically. Doubling the side of the input is roughly a 16× memory decision, not a 4× one.
If you have less than a few million labeled images and no self-supervised pretraining, expect a pure ViT to underperform a CNN of similar compute. The data volume decides what the architecture is able to learn, not the other way around.
If you need dense prediction — detection, segmentation, depth estimation — expect to reach for hierarchical ViTs such as Swin, or CNN-augmented variants. Plain ViT produces a single-resolution feature map, and dense tasks want a pyramid.
If you need a general-purpose vision backbone in 2026, expect to reach for self-supervised features. DINOv3 and SigLIP 2 are the current defaults; original plain-ViT supervised pretraining remains useful for teaching and controlled experiments but is no longer the baseline modern teams build on (per Meta AI Blog).
Rule of thumb: pick the ViT variant by the constraint you cannot escape — data volume, input resolution, or compute budget — then accept whichever inductive-bias or efficiency trade that choice imposes.
When it breaks: pure ViT with supervised ImageNet pretraining at small data scales or at high input resolutions will either underperform a CNN or fail to fit in GPU memory. Not a bug. A direct consequence of trading architectural priors for attention — and of attention’s quadratic cost at scale.
The Data Says
Vision Transformers do not see images better than CNNs. They see images differently, by learning from data what CNNs assume by construction. That bargain is the entire ViT story, and its limits — measured in images pretrained on, and in tokens attended to — are the cost of the bargain, not its flaw.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors