Contextual Retrieval: Prerequisites and Hard Limits at Scale
ELI5
Contextual Retrieval prepends a short summary to each chunk before embedding it, so search isn’t blindsided by missing context. Useful — once hybrid search and reranking are already in place.
A retrieval pipeline can pass every regression test and still leak. Chunks get embedded one at a time; whatever made them coherent in the source document — the section heading two pages back, the entity definition three sections earlier, the table caption that explained what “Q3” referred to — never enters the vector. The system returns matches that are technically similar and substantively wrong. Contextual Retrieval is one fix — and the wrong fix for several common situations.
The Pipeline You Need to Already Have
Contextual Retrieval is not a starting point. It is a refinement layer that sits on top of a working RAG pipeline, and the prerequisites are not optional. If the layers underneath are missing, prepending context to chunks mostly papers over the wrong problem.
What do you need to understand before learning contextual retrieval?
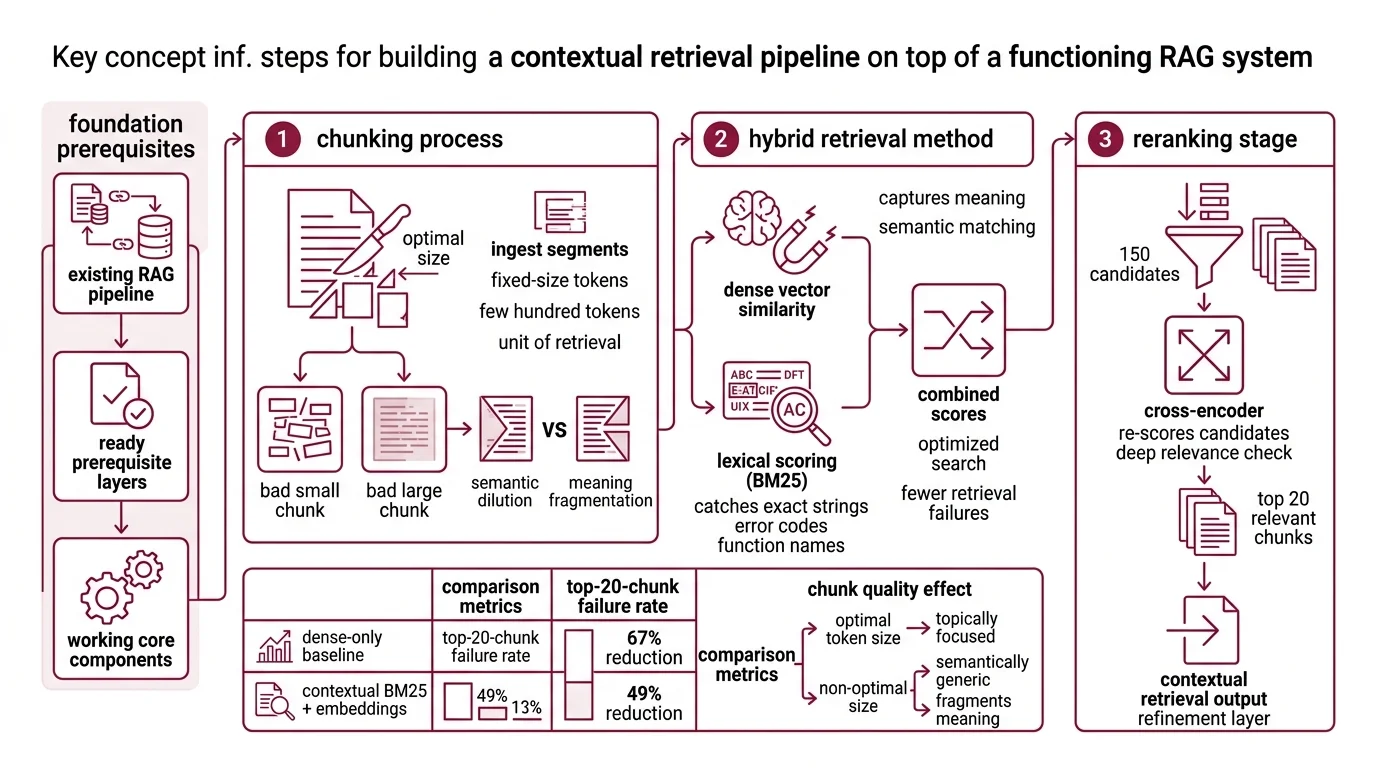
Three components must already work, in this order: chunking, hybrid retrieval, and reranking.
The first is chunking. A Retrieval Augmented Generation system ingests fixed-size segments — usually no more than a few hundred tokens, per Anthropic’s announcement — because dense embedding models have effective context windows that cap out well below typical document length. The chunk is the unit of retrieval. Choose it badly and no amount of contextualization saves you: a 2,000-token chunk dilutes the embedding into something semantically generic, while a 50-token chunk fragments meaning into shards. The “few hundred tokens” guidance is empirical — large enough to carry an idea, small enough to stay topically focused.
The second is hybrid retrieval. A Hybrid Search system combines dense vector similarity with lexical scoring (typically BM25). Dense embeddings capture meaning; BM25 catches exact strings — error codes, function names, identifiers — that semantic similarity routinely misses. Anthropic’s evaluation found that adding Contextual BM25 on top of Contextual Embeddings dropped the top-20-chunk failure rate from 5.7% to 2.9%, a 49% reduction over the dense-only baseline (Anthropic’s announcement). The dense layer alone gets you part of the way; the lexical layer closes the gap on queries that hinge on a specific token.
The third is Reranking. A reranking stage takes the top 150 candidates from the hybrid step and re-scores them with a cross-encoder before keeping the top 20 (Anthropic’s announcement). The cross-encoder reads query and chunk together — much more expensive per pair than a dot product, but tractable on a small candidate set. Layering reranking on top of Contextual Embeddings + Contextual BM25 cut the failure rate further to 1.9%, a 67% reduction over the baseline. The same evaluation showed top-20 outperforming top-5 and top-10, which means the generator downstream needs to handle longer windows of retrieved material — another design decision the reader has to commit to before contextualization helps.
There are also pre-retrieval techniques worth knowing about. Query Transformation (rewriting, expansion, HyDE-style hypothetical-answer generation) reshapes the query before it ever hits the vector store. Agentic RAG pushes the entire retrieval loop into a planner that can issue multiple queries and reason over partial results. Both are alternatives, not prerequisites — but they compete with Contextual Retrieval for the same engineering budget, and the cost shape is different. Query-side techniques add latency on every request. Contextual Retrieval pays once at ingestion and amortizes across queries — a distinction the AWS Machine Learning Blog calls out explicitly.
One prerequisite is implicit and worth naming: a knowledge base big enough to need retrieval at all. Anthropic’s guidance is direct — under roughly 200,000 tokens (about 500 pages), fit the corpus into a long context window with prompt caching and skip RAG entirely. The retrieval layer exists to compress search space; below the threshold, there is no search space worth compressing.
Where the Technique Breaks
Contextual Retrieval is well-defined, but it lives in a narrow operating range. Outside it, the math turns against you in ways that are not always obvious from the architecture diagram.
What are the technical limitations of contextual retrieval at scale?
The first limit is ingestion cost in absolute terms. The contextualization step calls an LLM once per chunk to generate the 50–100 tokens of prepended context. Anthropic reported $1.02 per million document tokens with prompt caching under Claude Haiku 3 (Anthropic’s announcement) — a striking number when prompt caching is doing the heavy lifting, and a misleading one if quoted out of season. The 2026 Claude lineup is different, the prompt-cache pricing is different, and the right thing to track is the cost shape: one-time at ingestion, batched, prompt-cached. Run it once per document version. Re-run when the document changes. Never run it per query.
The second limit is index drift. Every chunk is embedded with context generated from a specific snapshot of the parent document. If the document changes, the contextualization has to re-run for the affected chunks, and the cheapest way to detect “affected” is often to re-process the whole document. For a slowly evolving wiki this is fine. For a knowledge base ingesting telemetry summaries or daily compliance updates, the ingestion budget is no longer a one-time cost — it becomes a maintenance line item that competes with everything else on the platform team’s roadmap.
The third limit is the conflation problem. “Late interaction” gets thrown around as if it described what Anthropic does. It does not. Anthropic Contextual Retrieval (prepended context + hybrid + cross-encoder rerank) is structurally different from ColBERT-style late interaction (one vector per token, MaxSim scoring), which is structurally different from Late Chunking (mean-pool over a long-context embedding pass). Three techniques. Three cost profiles. Overlapping problems, but different mechanics — and the recommendation that fits one rarely fits another.
ColBERT and its descendants illustrate the trade-off in pure form. Late-interaction models store one vector per token instead of one vector per chunk — Weaviate puts the storage inflation at roughly 10× a single-vector dense index. ColBERTv2 adds residual compression that shrinks each vector from 256 bytes to 36 bytes (2-bit) or 20 bytes (1-bit), a 6–10× footprint reduction (ColBERTv2 paper). Even with compression, the recommendation from practitioners — including Weaviate’s own analysis — is to use late interaction as a reranking stage on top-K candidates rather than as the first-stage retriever over the full corpus. Run MaxSim over a billion vectors and the latency stops being a footnote.
Late Chunking, the Jina alternative, sidesteps the ingestion LLM call entirely: embed the full document with a long-context embedding model, then mean-pool the token vectors per chunk (Jina AI). The chunk vectors carry the document’s broader context without a separate generation step. The trade is dependency on a long-context embedding model — jina-embeddings-v3 ships with this natively, but if the stack is committed to a different embedder, the option is closed.
The fourth limit is evaluation reach. Anthropic’s headline numbers — 35%, 49%, 67% failure-rate reductions — come from one internal evaluation across nine datasets. Treat them as illustrative of the technique’s potential, not as a benchmark you should expect to hit on your own corpus. A code repository, a legal document set, and a customer support archive will respond differently to the same contextualization prompt. The right reading of those numbers is “this is what worked on Anthropic’s evaluation set”; the wrong reading is “this is what Contextual Retrieval will give you.” Not a benchmark. An invitation to run your own.
What the Cost Curve Predicts
The architecture decisions follow from the cost shape. Contextual Retrieval pays its bill at ingestion and amortizes across every subsequent query. Query-side techniques pay their bill on every request. The crossover point — when one approach beats the other — depends on three variables: corpus update frequency, query volume, and acceptable per-query latency.
- If the corpus updates rarely and query volume is high, Contextual Retrieval wins on long-run cost. The ingestion charge becomes a rounding error against query volume.
- If the corpus updates daily and queries are sparse, the ingestion math inverts. Chunks are being re-contextualized that nobody will retrieve.
- If the latency budget is tight and the corpus is small, skip retrieval entirely. Long-context windows with prompt caching are simpler and faster below 200,000 tokens (Anthropic’s announcement).
- If the evaluation shows a large gap between dense-only and dense+BM25, the bottleneck is lexical recall — fix that with hybrid search before adding contextualization. Contextualization will not rescue a query that needs an exact identifier match.
Rule of thumb: Contextualize only when hybrid search and reranking are already in place, the corpus is big enough to need RAG, and the update cadence is slow enough that ingestion runs are amortizable.
When it breaks: Contextual Retrieval breaks when the corpus changes faster than the ingestion budget can cover, when chunks arrive pre-fragmented in ways the contextualization prompt cannot recover (tables stripped of headers, code blocks split across boundaries), or when teams treat it as a substitute for missing prerequisites rather than a layer that depends on them.
A Less Obvious Consequence
The technique also subtly changes what counts as a “chunk failure.” Without contextualization, a chunk fails when the embedding does not match the query. With contextualization, a chunk can fail because the prepended context was generated from a misleading neighborhood — a section heading that turned out to refer to a different topic, a paragraph that summarized the document in language that does not appear in any specific section. The new failure mode is rare in well-structured documents and surprisingly common in noisy ones (mailing list archives, scraped support threads). The user sees a coherent answer with no signal that the framing was synthesized. The cure is either better source documents or a contextualization prompt that signals uncertainty when the surrounding material is ambiguous. Most pipelines do neither.
The Data Says
Anthropic’s evaluation across nine datasets showed Contextual Embeddings + Contextual BM25 + reranking driving the top-20-chunk failure rate from 5.7% to 1.9% — a meaningful reduction, but one that depended on every layer of the stack underneath being in place. The technique is a refinement, not a foundation. Below 200,000 tokens, skip RAG entirely; above it, build the prerequisites first and treat Contextual Retrieval as the layer that follows them.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors