From Chain-of-Thought to Tool Use: Prerequisites and Technical Limits of Agent Planning
Table of Contents
ELI5
Agent planning is what happens when a language model decomposes a task into steps, calls tools to execute them, and decides what to do next. It rests on three primitives: chain-of-thought, tool use, and the loop that fuses them.
A demo agent runs five steps and lands on the right answer. The same agent runs twenty steps and lands somewhere unrecognizable. Nothing about the model changed — only the chain length. Agent Planning And Reasoning is built on top of three older primitives, and each of those primitives carries a failure mode that compounds the moment you stack one on the next. The interesting question is not what agents can do. It is why they reliably stop working at a length that anyone running them in production has already encountered.
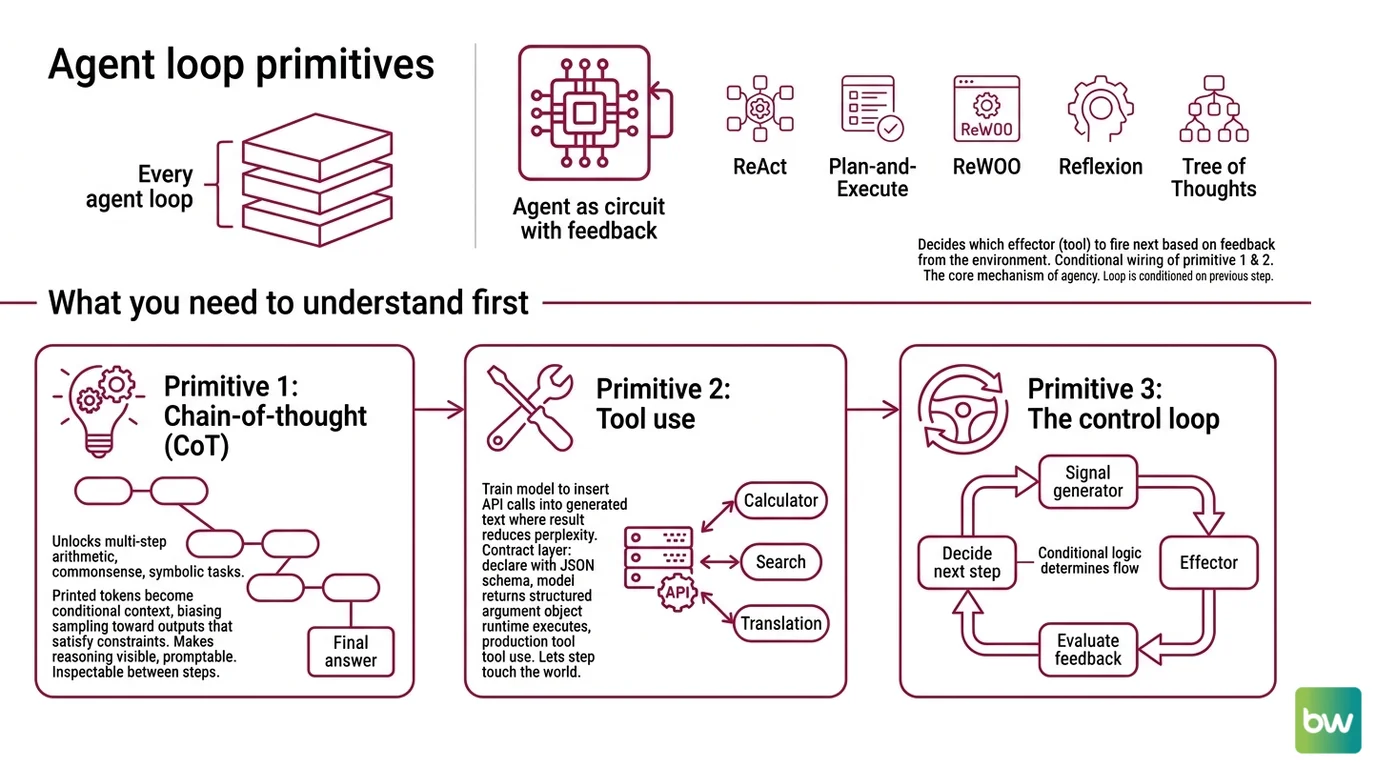
The Three Layers Beneath Every Agent Loop
Think of an agent the way you would think of a circuit with feedback. There is a signal generator (the language model), a set of effectors (the tools it can call), and a control loop that decides which effector fires next based on what just came back. Every named pattern in 2026 — ReAct, Plan-and-Execute, ReWOO, Reflexion, Tree of Thoughts — is a different way of wiring this loop. None of them invents new physics. They reorganize three primitives that already existed.
What do you need to understand before learning agent planning and reasoning?
You need to understand three things in order, because each one only makes sense once the previous one is in your head.
The first primitive is chain-of-thought (CoT). In 2022, Wei et al. showed that prompting a model with a few examples of intermediate reasoning steps unlocks multi-step arithmetic, commonsense, and symbolic tasks that the same model fails at when asked for an answer directly (Chain-of-Thought paper). The mechanism is not “the model thinks.” The mechanism is that the printed intermediate tokens become part of the conditional context for the next token, which biases sampling toward outputs that satisfy intermediate constraints. CoT made multi-step reasoning visible and promptable. Without it, no agent loop has anything to inspect between steps.
The second primitive is tool use. Toolformer (Schick et al., 2023) showed that a model could be trained to insert API calls — calculator, search, translation — into its own generated text wherever the call’s result would reduce the perplexity of the surrounding tokens (Toolformer paper). Soon after, OpenAI and Anthropic converged on a contract layer: declare each tool with a JSON Schema, and the model returns a structured argument object the runtime can execute (OpenAI Function-Calling Docs). This is the production form of tool use. CoT lets the model reason about a step. Function calling lets the step touch the world.
The third primitive is the agent loop itself. ReAct (Yao et al., ICLR 2023) interleaves Thought, Action, and Observation in one trajectory: the model writes a thought, emits an action the runtime executes, receives the observation as a token sequence, and then writes the next thought conditioned on what came back (ReAct paper). On HotPotQA and Fever it beat vanilla action models; on ALFWorld and WebShop, one-shot ReAct beat imitation and reinforcement-learning baselines trained on more than a hundred thousand tasks. Every modern agent SDK — LangGraph’s create_react_agent, the OpenAI Agents SDK, CrewAI — is a re-skin of this loop. If you understand the loop, you understand the substrate. Everything else is a wiring diagram on top of it.
The reason these three primitives form a stack is that each one solves a problem the previous one created. CoT made reasoning visible but disconnected from the world. Tool use connected reasoning to the world but did not say when to call which tool. ReAct said when to call which tool but did not say how to plan more than one step ahead.
That last gap is where the named planning patterns live.
Four Patterns, Four Bets on the Same Loop
Once a community has a working agent loop, the next question is always the same: what is the right amount of structure to impose on it? Pure ReAct interleaves thought and action one step at a time, which is responsive but expensive in tokens and prone to drifting. The four canonical 2026 patterns each pick a different point on the structure-versus-flexibility curve.
Plan-and-Solve (Wang et al., ACL 2023) is the upfront-decomposition bet. A planner module reads the task and writes out a sequenced plan; an executor then runs the steps (Plan-and-Solve paper). It was originally designed to address three failure modes of zero-shot CoT: calculation errors, missing-step errors, and semantic misunderstanding. LangChain ships this pattern as the Plan-and-Execute tutorial — the names are used interchangeably, but the paper is Plan-and-Solve and LangGraph’s tutorial is Plan-and-Execute. It is the right pattern when the steps are knowable in advance and the world will not surprise the plan.
ReWOO — Reasoning Without Observation — is the token-efficiency bet (Xu et al., 2023). It splits the agent into Planner, Worker, and Solver, and crucially generates the entire plan before any tool calls happen, so the long system prompt is not repeated on every step (ReWOO paper). The original 2023 evaluation reports five-times-better token efficiency and a four-percent accuracy gain on HotpotQA versus ReAct, with the reasoning offloaded from a 175B model to a 7B one — though the design targets that overhead, and modern function-calling APIs with shorter system prompts narrow the gap. ReWOO’s trade-off is structural: a plan that cannot see observations cannot adapt to surprising tool outputs.
Reflexion (Shinn et al., NeurIPS 2023) is the self-critique bet. The agent attempts a task, an evaluator gives binary or scalar feedback, a reflector module writes a verbal critique, and that critique is stored in Agent Memory Systems as episodic memory before the agent retries (Reflexion paper). No weight updates — Shinn et al. called it “verbal reinforcement learning.” The original paper demonstrated 91% pass@1 on HumanEval against a GPT-4-class baseline of 80%; current frontier reasoners exceed those numbers without Reflexion at all. The pattern still matters. The specific 2023 percentages are a snapshot of one model.
Tree of Thoughts (Yao et al., NeurIPS 2023) is the deliberative-branching bet. Instead of a single chain, the model generates several candidate “thoughts” per step, scores them itself, and explores with breadth-first or depth-first search and backtracking (Tree of Thoughts paper). On the Game of 24, GPT-4 with CoT solved four percent of problems; GPT-4 with Tree of Thoughts solved 74 percent. The cost is brutal: branching factor times depth blows up the token bill, and newer reasoning models like o1 and DeepSeek-R1 already do something like internal tree search at inference time, which makes explicit ToT prompting less of a lift on them.
A useful way to read these four is as a decision matrix. If your steps are knowable, choose Plan-and-Execute. If your tool overhead dominates, ReWOO. If success is verifiable and worth retrying, Reflexion. If the search space is wide and the answer is checkable, Tree of Thoughts. None of them is universally best. Each pattern fixes one limit and creates another. This is also why Anthropic’s “Building Effective Agents” guidance recommends the simplest design that works — most reliable production agentic systems are workflows on predefined paths, not autonomous agents (Anthropic Engineering). The same logic applies inside Multi Agent Systems, where coordination overhead amplifies whichever ceiling each sub-agent already has.
Where Each Pattern’s Ceiling Lives
Once you see the patterns as bets on the same loop, the next question is mechanical: where does the loop break? The answer is four physics, and every named pattern hits at least one of them.
What are the technical limitations of ReAct, Plan-and-Execute, and Reflexion patterns?
The first physics is error compounding. If a single step succeeds with probability p, a chain of n independent steps succeeds with probability p^n. At 0.95 per step, a five-step chain runs at roughly 77 percent, a ten-step chain at 60 percent, and a twenty-step chain at 36 percent (Reliability compounding, MindStudio). This is illustrative arithmetic, not a measurement of any specific system — but every Thought→Action→Observation cycle multiplies again, which is why aggressive plans almost always degrade faster than their authors expect. ReAct multiplies the cost most directly. Plan-and-Execute amortizes by reducing the number of LLM calls per step. ReWOO does the same more aggressively. Reflexion adds a layer that can recover from failure but costs another LLM call to do it.
The second physics is long-horizon collapse. Recent work on context-folding research (2025) reports that even the strongest models’ accuracy approaches zero past about 120 sequential steps; on harder variants, performance collapses inside 15 steps. Independently, Chroma’s Context Rot study finds that performance degrades with input length even when retrieval is 100 percent perfect — the length itself, not the noise inside it, hurts the model (Context Rot, Chroma). Plan-and-Execute and ReWOO both try to flatten this by replacing a long trajectory with a short plan plus short executions. They do not abolish the effect.
The third physics is the CoT faithfulness gap. Multiple 2025 studies suggest that the printed chain is often not a faithful representation of the model’s internal reasoning. A study on DeepSeek-R1 reports that the model acknowledges a strong harmful hint in 94.6 percent of cases but reports under two percent of the helpful hints it demonstrably uses (DeepSeek-R1 faithfulness study). The “Mirages of Logic” survey enumerates four hallucination types in CoT — premise, operation, logic, and conclusion errors (Mirages of Logic). This is an active research debate, not settled science. The practical upshot is that the printed chain is evidence about the answer, not a transcript of how the answer was reached.
The fourth physics is the reliability versus capability gap. The τ-bench paper introduced pass^k — does the agent solve the same task correctly k times in a row — and the original paper reported that even state-of-the-art function-calling agents passed under 50 percent of retail tasks single-shot, and under 25 percent on pass^8 (τ-bench paper). These are 2024 model snapshots, and Sierra has since released τ²-bench and τ³-bench; the headline gap remains, but the specific percentages should be read as a 2024 baseline, not as today’s number. The companion signal is GAIA: at launch in November 2023, humans scored 92 percent and GPT-4 with plugins 15 percent (GAIA paper). By 2026, top agents close that gap considerably — Claude Sonnet 4.5 leads HAL GAIA at 74.6 percent — but “easy for humans, hard for agents” remains the framing.
A 2025 failure-mode taxonomy (arXiv 2509.25370) finds that memory and reflection errors are the most common sources of error propagation, and that they typically arise in early-or-mid trajectory steps and become hard to reverse once they begin (Where LLM Agents Fail). That finding is what supports the engineering rule below.
Rule of thumb: Cap any agent chain at fewer than five sequential steps without a verifier, and choose the planning pattern by which physics you are trying to escape — token cost (ReWOO), unknown step structure (ReAct), recoverable failure (Reflexion), or wide search (Tree of Thoughts).
When it breaks: Agent loops break when long-horizon collapse and error compounding meet a task whose verifier is missing or weak. Past roughly fifteen steps on hard tasks and roughly 120 steps in general, accuracy approaches zero — and because failures cascade through memory, no single pattern recovers gracefully without an external check that decides whether the trajectory is still on track.
Security & compatibility notes:
- LangChain Core (CVE-2025-68664): Serialization injection in
load()/loads()defaults affects every LangGraph ReAct, Plan-and-Execute, and Reflexion stack. Patched in 1.2.5 / 0.3.81 with breaking changes — review and pin before upgrading.- AutoGen / Semantic Kernel: In maintenance mode as of Microsoft Agent Framework 1.0 GA (April 3 2026). Older Plan-and-Execute and Reflexion tutorials still run but get no new features.
- SWE-bench Verified: Training contamination confirmed in early 2026; OpenAI stopped reporting on it. Treat any 2026+ Verified score above 85 percent with caution and prefer SWE-bench Pro for comparisons.
The Data Says
Agent planning is not one capability. It is a stack of three primitives — chain-of-thought, tool use, the ReAct loop — and a vocabulary of four patterns that trade structure for flexibility. The patterns do not abolish the four physics that govern the loop. They reroute around one of them while exposing another. Choose the pattern by the failure mode you are trying to escape, not by the demo it produced.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors