From Baselines to Factorial Design: Prerequisites and Core Components of Ablation Experiment Design
Table of Contents
ELI5
An ablation study removes parts of an AI system one at a time and measures what changes — like disconnecting components of a machine to find which pieces actually do the work.
A team removes attention heads from a transformer, one by one. They record accuracy after each removal and publish a clean table. The numbers fluctuate — some heads seem critical, others do not. But the table reveals nothing, because without the right baseline, the right controls, and the right statistical framework, removal is just destruction with a spreadsheet.
The term itself borrows from neuroscience. Allen Newell introduced it in a 1974 tutorial on speech recognition, drawing an analogy with ablative brain surgery — the practice of removing tissue to understand which region governs which function (Wikipedia). The logic in machine learning is identical: if you want to know what a component does, take it away and observe what breaks. But observation without structure is anecdote. The distance between a useful Ablation Study and a meaningless one is not the removal itself — it is everything that must be true before the first cut.
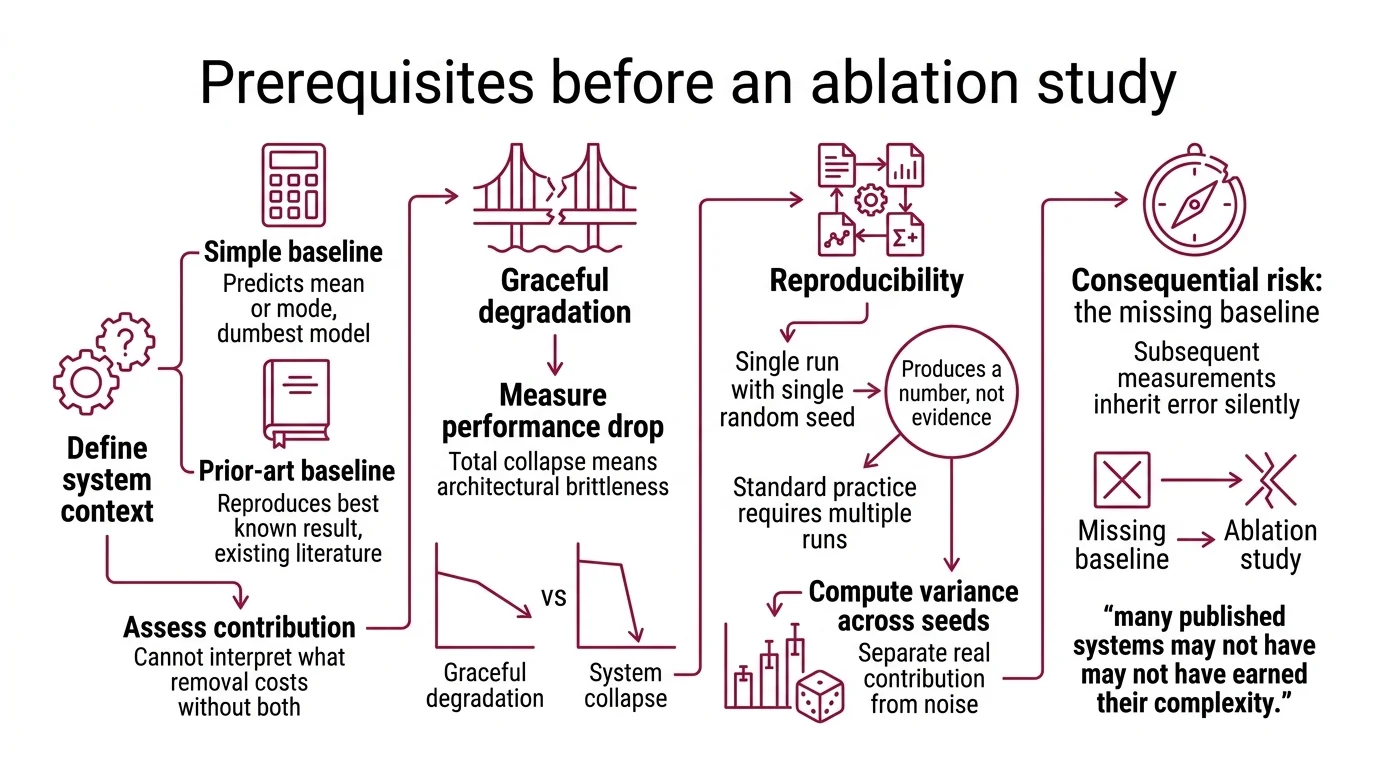
What Must Be True Before the First Cut
The prerequisite most practitioners skip is also the most consequential: the baseline. An ablation study measures contribution by comparing a full system to a reduced one. If the baseline is wrong — or missing entirely — every subsequent measurement inherits that error silently.
What do you need to understand before running an ablation study?
Three prerequisites. Each non-negotiable.
You need a baseline that means something. Two kinds are worth having: a simple baseline that predicts the mean or mode — the dumbest possible model that still produces output — and a prior-art baseline that reproduces the best known result from existing literature (ML@CMU Blog). The simple baseline tells you whether your system is better than guessing. The prior-art baseline tells you whether it is better than what already exists. Without both, you cannot interpret what removal costs.
A widely cited 2021 analysis found that in roughly 40% of published ML benchmarks, simple baselines were competitive with complex architectures (Iguazio) — though the primary source behind that figure has proven difficult to verify independently. The implication, if accurate, is uncomfortable: many published systems may not have earned their complexity.
You also need graceful degradation. If removing a component causes a total collapse rather than a measurable performance drop, the ablation tells you nothing about contribution — only about dependency. A system that crashes on any single removal is architecturally brittle, and ablation cannot distinguish importance from fragility in brittle systems.
And you need Reproducibility. A single run with a single random seed produces a number, not evidence. Standard practice requires reporting metrics across multiple seeds and computing variance. Without it, you cannot separate a real contribution from noise introduced by initialization — and in deep learning, initialization noise can be remarkably persuasive.
What is the difference between ablation study and hyperparameter tuning?
This confusion surfaces constantly, and the distinction is structural.
Hyperparameter Tuning accepts the architecture as given and asks: what parameter values produce the best performance? The learning rate changes. The dropout rate changes. The architecture does not.
An ablation study asks the inverse: given this architecture, which structural components contribute to performance, and by how much? You remove a Regularization layer, a skip connection, an entire attention module, and you measure what the system loses.
Not optimization. Attribution.
Tuning asks “how good can this get?” Ablation asks “why is this good at all?” Conflating them produces experiments that optimize without understanding — and understanding is the entire point of the exercise.
The Architecture of Systematic Removal
Once the prerequisites hold, the experiment itself demands precise machinery. The components of an ablation study are individually straightforward, but their interactions determine whether the results produce insight or noise.
What are the key components of an ablation study design?
Five elements form the anatomy of a well-designed ablation experiment.
The full model — your complete system, trained and evaluated — serves as the reference point against which all reduced versions are compared.
The ablation targets are the specific components you intend to remove. These split into two broad categories: model ablation trials, which target architectural components like layers, heads, or modules; and feature ablation trials, which target data features or input channels (Wikipedia).
The removal strategy matters more than most experimenters acknowledge. The five primary sub-types — removal (drop entirely), replacement (swap with a simpler alternative), perturbation (inject noise), architectural modification (vary width or depth), and data ablation (train on subsets) — each test fundamentally different hypotheses about contribution. Replacing a component with a random baseline tests a different question than removing it entirely, and choosing the wrong strategy can mask the very effect you are trying to measure.
The evaluation protocol is where most ablation studies quietly fail. Model Evaluation requires that every reduced model be trained and evaluated under identical conditions — same data splits, same compute budget, same stopping criteria. Any asymmetry between the full model and its reduced variants introduces confounds that cannot be disentangled from the ablation effect itself.
The comparison framework closes the loop. A percentage drop in accuracy is not, by itself, evidence. You need the statistical apparatus to determine whether the observed difference reflects a real contribution or sampling noise.
What statistical methods are used to evaluate ablation study results?
The statistical layer of ablation is where rigor either holds or collapses entirely.
The minimum requirement is straightforward: report your chosen metrics — accuracy, Precision, Recall, and F1 Score, or task-specific measures — with variance across multiple random seeds. A single-seed result is a point estimate with unknown uncertainty; publishing it as a finding is publishing a sample size of one.
When the effects are small — and in mature systems they often are — formal significance testing becomes essential. The standard threshold remains p ≤ 0.05, but the choice of test matters considerably. Bootstrap confidence intervals are recommended for comparing classifiers because they make no distributional assumptions about the performance metric (MachineLearningMastery). Parametric tests assume properties that accuracy distributions, in particular, rarely satisfy.
A Confusion Matrix adds diagnostic depth that aggregate metrics miss. Two models can produce identical accuracy but radically different error distributions — one might fail catastrophically on rare classes while the other distributes errors evenly. Ablation without per-class analysis can hide the most important signal: that a removed component protected performance on the long tail.
For standardized evaluation tasks, benchmarks like MMLU Benchmark provide external validity. But only if the benchmark itself is trustworthy. Benchmark Contamination can inflate scores in ways that make ablation comparisons meaningless — because both the full model and its reduced variant may benefit from leaked data, masking the actual contribution of the ablated component.
From Single Cuts to Factorial Surfaces
The most common ablation method — Leave-One-Component-Out — has a structural blind spot that becomes more dangerous as architectures grow more entangled. It tests each component in isolation, assuming contributions are independent. But neural network components interact; a skip connection might appear irrelevant on its own yet prove essential in combination with a specific normalization layer.
This is where factorial design enters the picture — borrowed from experimental statistics rather than invented within machine learning. Factorial ablation varies multiple components simultaneously to detect interaction effects. Instead of removing A, then removing B, you test all four combinations: full model, minus A, minus B, minus both. The interaction effect — the gap between what individual removals predict and what simultaneous removal reveals — can be the most important finding in the entire study.
The ABLATOR framework attempts to operationalize this idea through distributed execution of multi-factor ablation experiments, using a SearchSpace abstraction for factorial parameter variation (ABLATOR GitHub). As of its latest stable release — v0.0.1b3 from December 2023 — the framework remains pre-stable and should not be assumed production-ready. But the underlying principle — that ablation should be systematically factorial, not merely sequential — is sound experimental design regardless of available tooling.
A 2025 paper at EuroMLSys explores an even more recursive direction: using large language models to design and automate ablation studies themselves (EuroMLSys). The methodology appears mature enough to formalize beyond manual experiment planning.
Rule of thumb: if your system has several interacting components you intend to ablate, single-factor removal will almost certainly miss interaction effects. Plan for at least pairwise factorial combinations.
When it breaks: ablation assumes that removal cleanly isolates contribution. In heavily entangled architectures — where components share learned representations through residual paths — clean isolation is impossible. Removing one component shifts the distribution that others depend on, and the observed performance change reflects redistribution rather than contribution. You end up measuring fragility, not importance.
The Data Says
An ablation study is only as honest as its prerequisites. The baseline defines the reference frame; graceful degradation determines whether removal is informative; statistical rigor separates signal from noise. Skip any of these, and the experiment produces numbers without meaning — a table of losses that could belong to any system, about any component, proving nothing.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors