Alpha Channels, Trimaps, and the Hard Limits of AI Background Removal
ELI5
** AI Background Removal** is alpha estimation — the model predicts how transparent each pixel should be, not which pixels are the subject. Hair, glass, and motion-blurred edges live in the gray band between foreground and background, exactly where that estimate is hardest.
You drop a studio portrait into a remove.bg or rembg pipeline. The body comes back clean. Then you zoom in on the hair, and the cutout looks like a silhouette stamped from cardboard. You try a glass tumbler and the model erases it as if it were never there. Different failures, identical root cause — and that root cause is not “the AI doesn’t know what the subject is.” The system was never trying to answer that question.
The Equation Hidden Behind Every Cutout
Most people picture a background remover as a smart eraser: the model recognises the subject, decides what to keep, and wipes the rest. That intuition is wrong by one whole layer of abstraction. The model is solving an equation borrowed from image compositing, and the equation is what creates the limits.
Not segmentation. Alpha estimation.
What concepts do you need to understand before using AI background removal?
Three background threads, in order of how directly they shape the output.
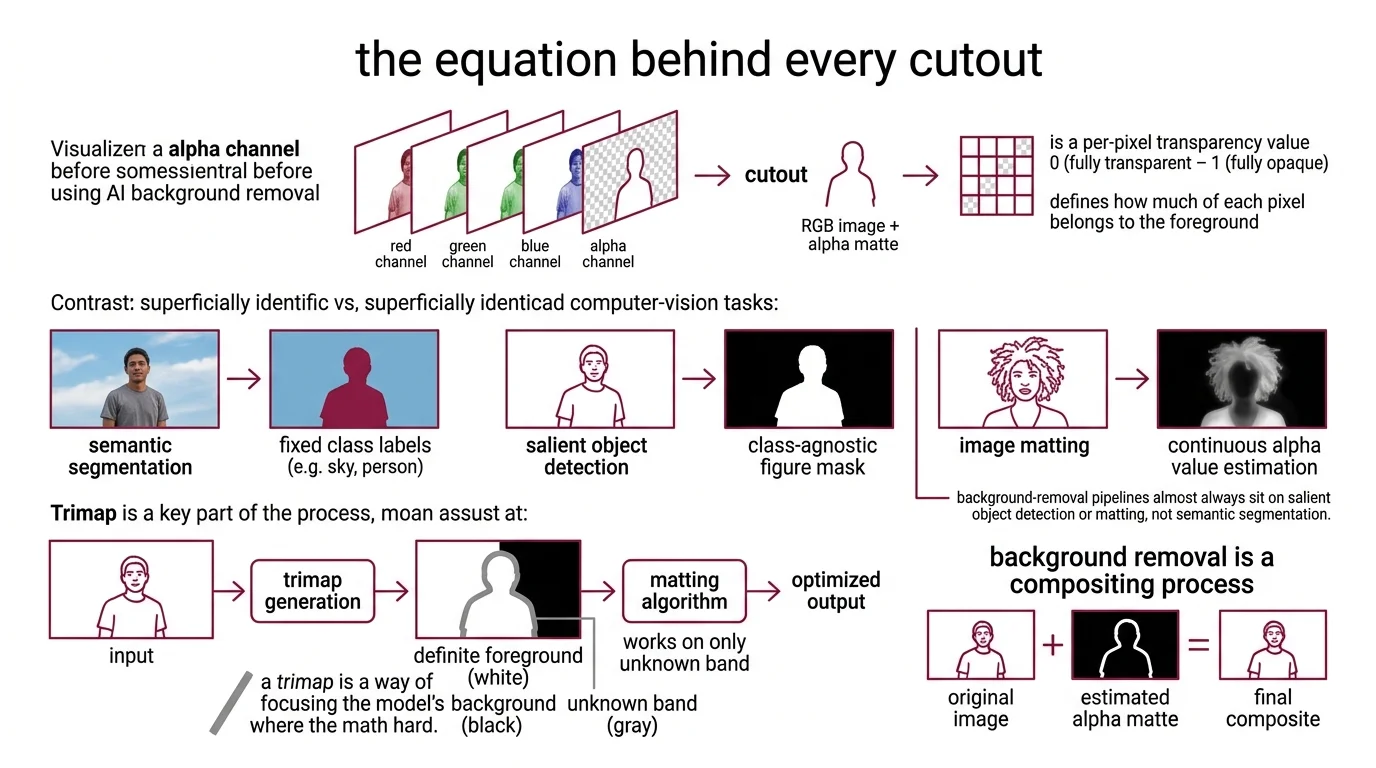
First, the alpha channel — the fourth channel that sits next to red, green, and blue. Alpha is a per-pixel transparency value between 0 (fully transparent) and 1 (fully opaque). A “cutout” is not a cropped image; it is an RGB image plus an alpha matte that tells the compositor how much of each pixel belongs to the foreground.
Second, the difference between three computer-vision tasks that look superficially identical but solve different problems. Semantic Segmentation assigns one class label per pixel from a fixed vocabulary — sky, road, person, sheep. Salient Object Detection is class-agnostic; it produces a binary or near-binary mask of “the salient figure” without naming it. Image matting goes further still and estimates a continuous alpha value per pixel. Background-removal pipelines almost always sit on salient object detection or matting, not semantic segmentation (per Frontiers SOD review).
Third, the Trimap — a three-region map that splits the image into definite foreground (white), definite background (black), and an unknown band (gray) along the contested edge. The matting algorithm only solves the equation inside the unknown band; the rest is given. A trimap is a way of admitting which pixels are easy and putting all of the model’s effort where the math is hard (per LearnOpenCV’s matting tutorial).
If you internalise nothing else, internalise this: background removal is a continuous regression problem at the edges, sitting on top of a discrete classification problem in the interior.
How do alpha channels, trimaps, and image matting relate to background removal?
The bridge between the three is a single line of math known as the compositing equation:
I = αF + (1 − α)B
Every observed pixel I is modelled as a linear blend of an unknown foreground colour F and an unknown background colour B, weighted by the unknown alpha α. For RGB inputs, that is three equations per pixel — one for each channel — and seven unknowns: three for F, three for B, and one for α.
Three equations. Seven unknowns.
The matting problem is mathematically ill-posed: there are infinitely many (F, B, α) triples that explain any given observed pixel. A trimap collapses that ambiguity for the easy regions — pixels marked white have α = 1, pixels marked black have α = 0 — and leaves the network to estimate α only inside the unknown band. Deep Image Matting, the first end-to-end CNN for this task, did exactly that: it took the image and a hand-drawn trimap as input and learned to output the alpha matte, with a separate refinement stage on top (Deep Image Matting site).
Modern background-removal models go a step further and try to skip the trimap altogether. U²-Net reformulates the task as salient object detection with a nested U-structure of ReSidual U-blocks, producing a near-alpha mask without any user input (U²-Net GitHub). BRIA RMBG is built on the BiRefNet architecture and outputs an 8-bit grayscale alpha matte directly from a single image, trained on more than fifteen thousand manually labelled licensed images according to BRIA’s own model card. SAM 2 treats the trimap as a prompt — a few clicks, a box, or a mask — and returns a segmentation rather than a true matte, but Meta reports about a 6× speedup on images compared with the original SAM (Meta AI).
The trimap never disappeared. It moved inside the network, where it now lives as an implicit prior learned from training data.
Where the Model Goes Blind
Once you hold the matting equation in your head, the catalogue of “AI background removal failure cases” stops looking like a list of unrelated bugs. Each failure is a place where the underlying assumption — that every pixel is a clean linear blend of one foreground colour and one background colour — stops being true. The architecture cannot fix what the equation does not represent.
What are the technical limits of AI background removal on hair, transparency, motion blur, and complex edges?
Four failure regions show up consistently across the matting literature, and each maps onto a specific way the compositing equation breaks (per Matting Survey, MDPI 2023).
Fine details — hair, fur, fibres. A single hair occupies a fraction of a pixel, so the captured colour is genuinely a blend of strand colour and background colour. The math of the equation is correct here; the problem is that the unknown band is enormous relative to the strand thickness, and small errors in α compound visually because human vision is acutely sensitive to silhouette quality. Dedicated matting models like BRIA RMBG-2.0 and the hair-tuned remove.bg pipeline are explicitly trained to lower gradient error in these regions, which is why they outperform general-purpose segmenters on portraits. They still produce visibly degraded edges on tightly curled or back-lit hair, because the training distribution simply does not contain enough of those configurations.
Transparent and translucent objects — glass, water, light bulbs. This is the regime where the equation itself fails, not the model. A glass tumbler is not a foreground that occludes a background; it is an optical element that refracts the background through its body. The observed pixel is no longer a simple αF + (1 − α)B blend — it is a non-linear function of the background through a lens. A regression-based matting model can only output an α value, so its best behaviour is to mark the entire object as background (and erase it) or as foreground with a flat alpha (and keep a ghostly silhouette). Diffusion-based matting research — Matting by Generation (SIGGRAPH 2024), DRIP (NeurIPS 2024), and SDMatte (ICCV 2025) — reframes the problem as conditional generation and partially closes this gap, but the papers themselves note that semi-transparent regions with high-frequency texture, such as patterned sheer fabric or refracted backgrounds, still fail.
Motion blur. A blurred edge is a temporal blend, not a spatial one — the camera integrated several positions of the subject across the exposure window. Single-image background removers do not have a dedicated motion-blur head; tools like Rembg, BRIA RMBG-2.0, and Remove Bg treat the blur as if it were ordinary semi-transparency, which produces either a hard-edged cutout that clips the trail or a soft alpha that bleeds the wrong colour into the trail. Video-matting models such as RVM and Generative Video Matting handle this case by reasoning across frames, but those models are not what runs inside a one-image API.
Complex semi-transparent edges — sheer fabric, smoke, frosted glass, water droplets. Any region that is simultaneously translucent and high-frequency violates the assumption that F is a single colour inside the unknown band. The equation has no clean solution; the model has no clean prior. This is the region where current 2026 systems fail most predictably.
The pattern is consistent: the model fails wherever the compositing equation does.
Security & compatibility notes:
- rembg path traversal (CVE-2026-40086): Directory-traversal vulnerability in the HTTP server’s custom-model endpoints (
u2net_custom,dis_custom,ben_custom). Pin to rembg ≥ 2.0.75, released 8 April 2026 (per Snyk Advisory and rembg releases).- rembg Python compatibility: rembg requires Python ≥ 3.11; pymatting and numba pins previously broke installs on newer interpreters, so verify the target environment before recommending it.
- BRIA RMBG-2.0 license: The model is released under CC BY-NC 4.0. Any commercial product use requires a paid agreement with BRIA — this is a contractual gate, not a formality (per BRIA Hugging Face).
What the Math Predicts
Once the equation is in front of you, the rest of the system stops being mysterious. It predicts most of what teams discover by trial and error.
If you change the input distribution, expect the dedicated background-removal model to degrade faster than the generalist segmenter. BRIA RMBG-2.0 and the remove.bg pipeline are tuned for the alpha matte at portrait and product-photo edges; on a satellite image or a microscopy slide, a class-agnostic prompter such as SAM 3 will often produce a more usable mask, even though it returns a segmentation rather than a true matte.
If you need an alpha matte and your subject is opaque with clean edges, expect U²-Net or rembg’s BiRefNet session to be sufficient, and reach for a heavier matting model only when hair, fur, or thin structures appear. The compositing equation is solvable in this regime; spending budget on a larger model often buys very little.
If you need to remove a background from an image containing transparent or translucent objects, expect the off-the-shelf result to be wrong. Diffusion-based matting research is the most promising direction — early 2024–2025 papers reformulate matting as conditional generation and handle some semi-transparent cases — but as of April 2026 these methods are still mostly research-grade.
If you need video, expect the single-image tooling to fail across motion blur and temporal coherence. Use a video matting model with explicit temporal reasoning, not a frame-by-frame loop over a still-image API.
Rule of thumb: match the model to the part of the equation you need solved — opaque interior, fine alpha edge, or genuinely translucent material — and stop expecting one network to cover all three.
When it breaks: background removers fail on transparent surfaces, semi-transparent high-frequency texture, and motion-blurred edges because the compositing equation I = αF + (1 − α)B does not describe those pixels — the limit is mathematical before it is architectural, and no amount of additional training data on a regression matting model will fully close it.
The Data Says
AI background removal is a continuous alpha-estimation problem dressed in the clothing of subject detection. Modern dedicated matters — BRIA RMBG-2.0, U²-Net inside rembg, the remove.bg API — are excellent at the cases where the compositing equation describes the image, and predictably weak everywhere it does not. The next gain in this field will come from Diffusion Models reframing matting as generation rather than from another regression network trained on more portraits.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors