False Positives, Lost Diversity, and the Technical Limits of Deduplicating Training Data

ELI5
Data deduplication removes repeated text from a training set. But the algorithms measure surface overlap, not meaning — so they can delete rare, unique examples by mistake and still miss copies that were lightly reworded.
Removing duplicates makes language models measurably better. After deduplication, models emit memorized training text roughly ten times less often, a result Lee et al. demonstrated in their 2022 ACL paper. The same study found a single 61-word English sentence repeated more than 60,000 times in the C4 corpus — the kind of pathological redundancy that pulls a model toward parroting instead of generalizing. So far, so clean.
Now watch what happens at the boundary. Feed the same fuzzy-matching pipeline two commercial contracts that are genuinely different agreements — different parties, different obligations — but built from the same legal boilerplate. A shingle-based matcher can score them as roughly 99% similar and discard one as a duplicate, an illustrative case the Zilliz engineering team described from trillion-scale practice. The algorithm didn’t malfunction. It did exactly what it was told: measure overlapping word sequences. It just has no idea that the dates it ignored were the entire point.
That gap — between what these systems measure and what we want them to understand — is where every technical limit of deduplication lives.
What the Matcher Actually Sees
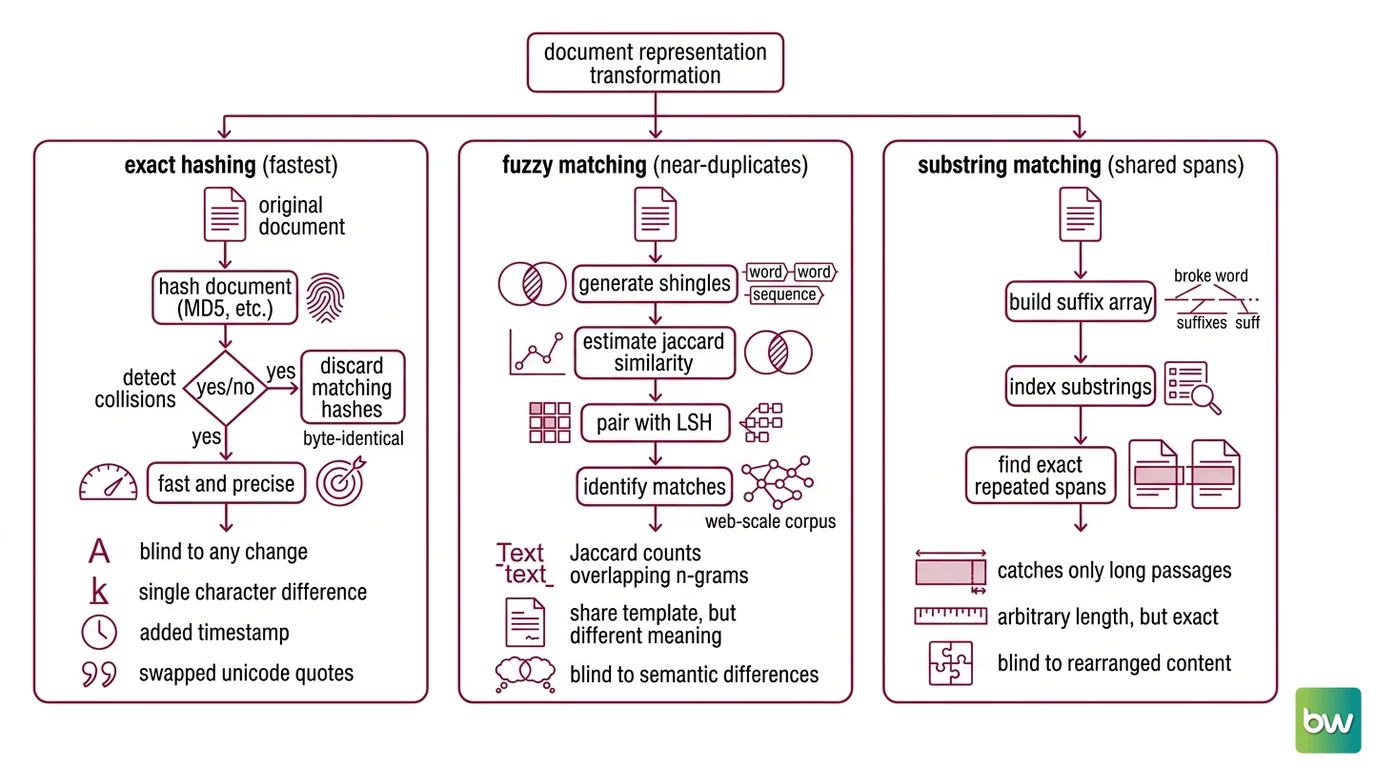
A Data Deduplication pipeline never reads a document the way you do. It converts text into a representation it can compare cheaply at scale, then declares two items “the same” when that representation crosses a threshold. The four dominant method families each pick a different representation — and each one trades a different kind of blindness for its speed.
What are the technical limitations of data deduplication for training datasets?
The limits come from a single design decision repeated across every method: to compare billions of documents, you must reduce each one to something smaller than itself, and every reduction discards information that might have mattered.
Exact hashing is the strict end. Tools hash each document — often with MD5 — and drop collisions. It is fast and precise in the literal sense: only byte-identical text matches. But a single changed character, an added timestamp, one swapped Unicode quote, and the hashes diverge completely. Exact hashing catches verbatim copies and is blind to everything else, which is why it is never used alone.
Fuzzy matching loosens this. MinHash estimates the Jaccard Similarity between two documents — the ratio of shared word-sequence “shingles” to total shingles — without comparing them directly. Pair it with Locality Sensitive Hashing and you get a system that finds near-duplicates across a web-scale corpus in roughly linear time. This is the workhorse. It is also the source of the contract problem: Jaccard similarity counts overlapping n-grams, so two texts that share a template score high regardless of whether the differences between them carry all the meaning.
Substring matching takes a third angle. A Suffix Array indexes every substring in the corpus, letting you find exact repeated spans of arbitrary length — a long quoted passage embedded in otherwise-original documents. It catches what shingling misses at the passage level, but it reasons about literal character sequences, not paraphrase.
Semantic deduplication is the newest family and the most ambitious. Semantic Deduplication embeds each document into a vector and removes items that sit too close together in that space. Abbas et al.’s SemDeDup work showed this could remove 50% of the LAION dataset with minimal performance loss while roughly halving training time. Embeddings capture meaning that n-grams cannot — but they inherit every bias of the encoder that produced them, and “too close” is still a threshold someone has to choose.
Four methods, four representations, one shared property: each measures a proxy for sameness, and the proxy is never the thing itself.
The Threshold Is a Dial, Not a Truth
Here is the part that trips up teams who expect deduplication to have an accuracy number. It doesn’t. The rate of mistakes is not a fixed property of the algorithm — it is a setting you tune, and every adjustment moves error from one column to the other.
Consider the LSH stage in a MinHash pipeline. LSH splits each document’s signature into bands and rows, and the band/row configuration governs which pairs even get considered as candidates. Loosen it — more bands — and you catch more genuine near-duplicates but also flag more innocent pairs as matches. Tighten it, and you miss real copies to avoid false alarms. The Zilliz engineers describe this directly: more bands means more false positives and fewer false negatives, all controlled by the bands-and-rows knob.
There are two ways to be wrong here, and they are not symmetric:
- A false positive deletes data that should have stayed. The two distinct contracts collapse into one. A rare dialect example gets removed because it shares phrasing with a common one. You lose signal, permanently, and you never see the gap it left.
- A false negative keeps a duplicate you wanted gone. A paragraph someone paraphrased survives because its shingles no longer overlap enough. The Memorization risk that motivated the whole exercise persists, just below your detection threshold.
You cannot minimize both at once with a single threshold. That is not an engineering oversight waiting for a better tool — it is the precision-recall tradeoff, and it is structural.
Not a measure of meaning. A measure of overlap. Every method on this list scores how much surface two documents share, then asks you to decide how much sharing counts as “duplicate.” The decision is yours, and the corpus cannot tell you whether you chose well.
What Aggressive Deduplication Quietly Costs
The false-positive column has a second-order effect that is harder to see and harder to measure: it erodes diversity. Rare data is, by definition, data that looks unlike most of the corpus — long-tail languages, unusual domains, edge-case phrasings. But “looks unlike most of the corpus” is not how a similarity matcher reasons. When a rare example happens to share structure with a common one, it sits in the danger zone, and an aggressive threshold removes it. These are precisely the examples that Active Learning pipelines spend compute trying to surface — and that deduplication can erase in a single pass.
This is where the honest answer is “we don’t have a clean number.” SemDeDup shows that large removals can be safe on some datasets. But the field has no single authoritative figure for how much rare, valuable data aggressive deduplication discards, and the synthetic benchmarks used to evaluate dedup quality carry biased and limited notions of what even counts as a duplicate. Diversity loss is an active risk, not a settled measurement — which means you cannot fully trust a tool to tell you when you’ve cut too deep.
If you turn the threshold, expect these effects
The mechanism predicts its own failure modes. You can use it to reason forward:
- If you tighten the similarity threshold to protect rare data, expect more surviving near-duplicates — and the privacy and memorization risks that Kandpal et al. tied to duplication come back with them.
- If you loosen it to scrub duplicates harder, expect the diversity of your long tail to thin, with no error message to warn you.
- If you rely on exact hashing alone, expect lightly-edited copies — reformatted, retimestamped, re-quoted — to pass straight through.
- If you switch to semantic deduplication to catch paraphrases, expect the encoder’s blind spots to become your pipeline’s blind spots.
Rule of thumb: Treat the deduplication threshold as a curation decision about your corpus, not a default to accept — the right setting depends on how much your value lives in the long tail.
When it breaks: Deduplication fails hardest when meaningful difference hides inside high surface overlap — near-identical templates with decisive small edits, or rare examples that structurally resemble common ones. The matcher sees similarity and deletes signal, and because the discarded data leaves no trace, the loss is invisible until a downstream evaluation exposes the gap.
The Tooling Doesn’t Remove the Judgment
Production tools make these tradeoffs faster, not automatic. NVIDIA’s NeMo Curator (v1.2.0, Apache 2.0) bundles all three classical families — exact via MD5, fuzzy via MinHash and LSH, and embedding-based semantic dedup — on GPU-accelerated infrastructure. The open-source Text Dedup library (v0.4.1) offers MinHash with LSH, SimHash, suffix-array substring matching, and a bloom-filter variant for single-machine and Spark workflows.
Both give you the dials. Neither tells you where to set them. That decision belongs to the same Training Data Quality judgment that governs Data Labeling And Annotation and Data Augmentation: it is a curation problem wearing an infrastructure costume. The pipeline scales the comparison; it does not supply the definition of “duplicate” that your dataset actually needs.
The Data Says
Deduplication reliably reduces memorization and privacy leakage, but it buys that reliability with a structural tradeoff it cannot escape: every method measures surface similarity as a proxy for sameness, and every threshold trades false positives against false negatives. The unmeasured cost is diversity — rare data that resembles common data, deleted without a trace. The limit is not the tooling. It is that “duplicate” is a judgment, and similarity is only a guess at it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors