False Positives, Dialect Bias, and Adversarial Bypasses: The Hard Limits of Automated Toxicity Detection
Table of Contents
ELI5
Toxicity classifiers learn surface patterns — specific words, dialect markers, sentence structure — rather than semantic intent. This makes them systematically over-flag minority speech while remaining vulnerable to adversarial inputs engineered to evade detection.
Run a sentence through a toxicity classifier. Now rewrite the same thought in African American English and run it again. The score jumps — not because the meaning changed, but because the statistical model underneath learned to associate certain dialectal patterns with what its training data labeled “toxic.” Think of it like a smoke detector calibrated on a single type of smoke: it triggers on steam from a hot shower, misses smokeless accelerant entirely, and never actually learned to detect fire. The system built to protect vulnerable communities is penalizing their speech, and the mechanism is not a bug. It is a predictable consequence of how these classifiers learn.
The Dialect Penalty: How Classifiers Mistake Identity for Intent
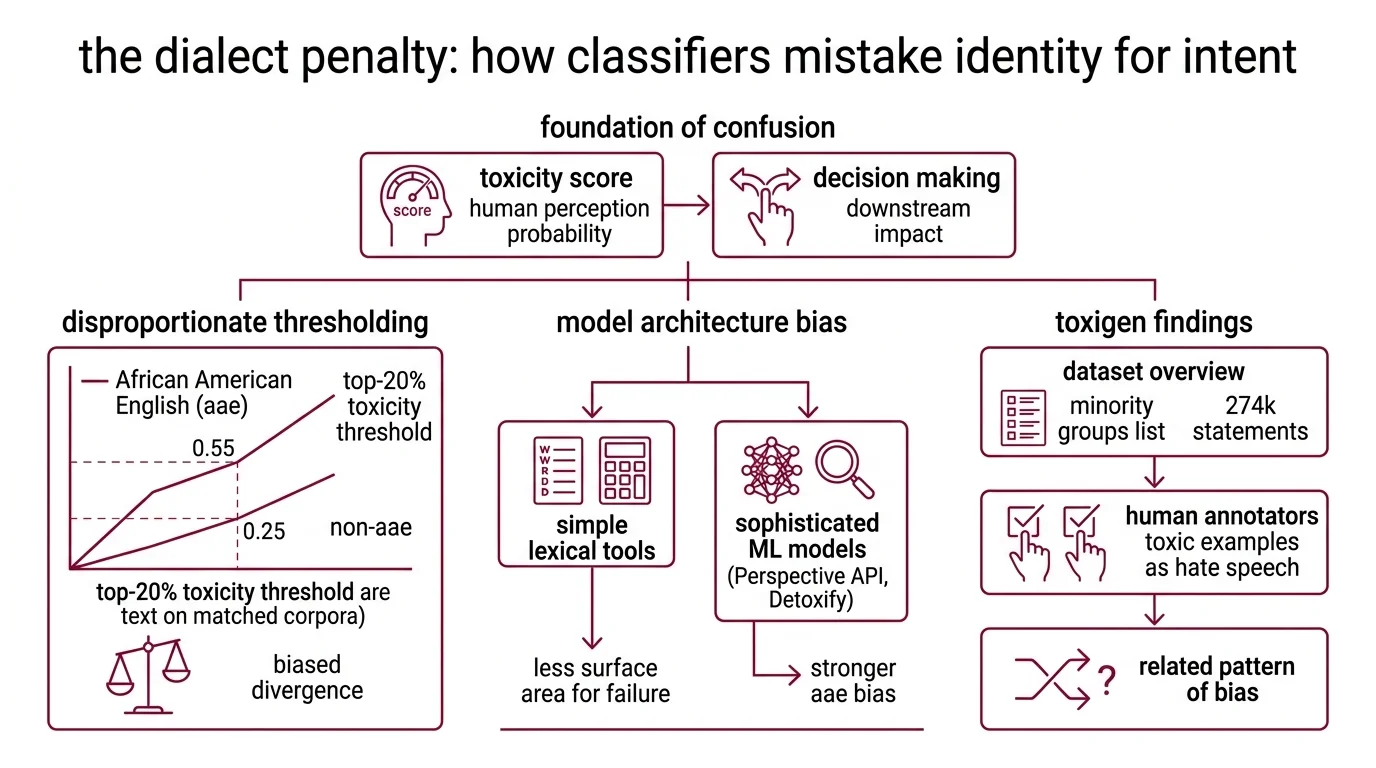
The gap between what a Toxicity And Safety Evaluation classifier measures and what it claims to measure begins with a foundational confusion. A toxicity score from Perspective API represents the probability that a human reader would perceive a comment as toxic — a confidence estimate, not a severity rating (Lasso Moderation). That distinction reshapes how every downstream decision should be interpreted, and it is almost universally ignored.
Why do toxicity classifiers produce false positives on African American English and minority dialects
A large-scale analysis of toxicity model behavior across dialects found that the top-20% toxicity threshold sits at 0.55 for African American English text versus 0.25 for non-AAE text on matched corpora from CORAAL and Buckeye datasets; 77% of similar-pair divergences were biased against AAE (Resende et al.). In practice, an AAE speaker needs a score more than twice as high to cross the same moderation threshold as a speaker of Standard American English.
The pattern beneath this is counterintuitive. ML-based toxicity models — including Perspective API and Detoxify — show substantially stronger AAE bias than simpler lexical tools like VADER and TextBlob (Resende et al.). More sophisticated models produced more biased outcomes. The reason traces to architecture: neural classifiers learn contextual co-occurrence patterns from training data, and when that data over-represents dialectal features in toxic-labeled examples, the model absorbs the association as signal rather than confound. A lexical tool, which counts word occurrences without learning co-occurrence structure, has less surface area for this particular failure.
Toxigen, a dataset of 274,000 toxic and benign statements covering 13 minority groups — where 94.5% of toxic examples were confirmed as hate speech by human annotators — revealed a related failure mode. Toxicity classifiers falsely flag text that merely mentions minority groups, over-relying on lexical cues like group names and culturally associated terms rather than evaluating semantic intent (Hartvigsen et al.). The classifier learned that certain words appear near toxicity. It did not learn why.
Not detection. Pattern matching.
The Adversary’s Advantage: Reasoning Past the Guard
If classifiers struggle with benign text that resembles toxic patterns, the mirror problem is equally severe — toxic text engineered to avoid those patterns. The same statistical shallowness that generates false positives generates false negatives, and adversarial researchers have learned to exploit this symmetry with increasing precision.
How do jailbreaks and adversarial prompts bypass AI safety classifiers in 2026
Harmbench, the field’s standardized evaluation framework for automated Red Teaming For AI, catalogs 510 curated harmful behaviors tested across 18 attack methods and 33 large language models. The benchmark confirmed what security researchers already suspected — safety classifiers can be bypassed with systematic effort, and the required effort is decreasing.
The scale of that vulnerability shifted in 2026. A study published in Nature Communications demonstrated that large reasoning models can autonomously Jailbreak target models with a 97.14% overall success rate, using fully autonomous multi-turn attack strategies across multiple reasoning models and target systems — in controlled laboratory conditions (Hagendorff et al.). Real-world rates will vary by deployment context. But the laboratory result reveals the structural problem: the attacker models required no human orchestration. They reasoned through safety barriers by identifying inconsistencies in the target’s refusal logic, adapting their approach across conversation turns the way a human red-teamer would.
The arms race is structurally asymmetric. Defenders must anticipate every possible attack vector; an attacker needs only one path through. Llama Guard 4 — Meta’s latest safety classifier at 12 billion parameters, pruned from Llama 4 Scout and expanded to handle multimodal inputs across text and images — improved English output filtering by four percentage points in recall and eight in F1 score over its predecessor (Meta AI). Those are meaningful gains. But when adversarial success rates approach near-total effectiveness under controlled conditions, incremental classification improvements address a shrinking fraction of the actual threat surface.
According to a cross-classifier evaluation, the false positive rate across available safety classifiers spans from near zero for well-resourced models to well over a third for smaller, faster alternatives — though direct comparison across tools requires controlling for evaluation methodology, language, and threshold selection (AAAI RTP-LX). That spread is itself informative: there is no consensus on what constitutes adequate safety classification, and models that minimize false positives typically accept higher miss rates on genuinely harmful content.
The Confidence Illusion: What a 0.6 Score Actually Tells You
Both failure modes — dialect false positives and adversarial false negatives — converge on a deeper measurement problem. The scores themselves are widely misunderstood, and the misunderstanding shapes how moderation systems make their most consequential decisions.
What are the technical limitations of automated toxicity scoring at scale
False positives and false negatives from Perspective API tend to cluster in the mid-confidence range (Lasso Moderation). This is precisely the range where moderation decisions carry the highest stakes — where a platform must choose between removing content and leaving it visible — and it is where the classifier performs worst.
The score represents a probability estimate of human perception, not a measurement of objective harm. There is no ground truth to calibrate against, because toxicity is partially subjective: reasonable annotators disagree, cultural context shifts meaning, and the same statement can be harmful in one community and unremarkable in another. The classifier collapses this irreducible ambiguity into a single scalar, and any threshold applied to that scalar will be simultaneously too sensitive for some populations and too lenient for others.
Scale compounds every weakness. At platform volume — millions of comments per hour — even a small false positive rate translates into hundreds of thousands of incorrectly suppressed messages per day. The same pattern-matching limitation that drives Hallucination in generative models — confident output without semantic grounding — produces confident misclassification in safety models. The classifier does not know what harm is. It knows what harm looked like in its training corpus.
And the infrastructure itself is shifting. Perspective API is scheduled for full shutdown by the end of 2026, with no migration support, forcing organizations that built moderation pipelines around it into an unplanned architectural transition (Tisane Labs).
Deprecation note:
- Perspective API shutdown: Full service termination scheduled for December 31, 2026. No migration support provided. Quota requests accepted only until February 2026 (Tisane Labs).
Designing Around a Classifier That Cannot Understand Harm
If a classifier learns dialect markers as toxicity signals, deploying it without dialect-aware calibration will systematically suppress minority voices. If adversarial reasoning models can bypass safety classifiers with near-total success under laboratory conditions, defenses anchored exclusively in classification will erode as reasoning capabilities scale. And if the core scores are most unreliable in the decision-critical mid-range, any moderation system built on a single threshold is making its worst mistakes on its most ambiguous cases.
These are not independent problems. They are three symptoms of one architectural limitation: classifiers that learned surface correlations rather than semantic understanding of harm.
Rule of thumb: Treat automated toxicity scores as one signal in a multi-layered system, never as the final decision — route high-confidence extremes to automated action and mid-range scores to human review.
When it breaks: The framework fails completely when adversarial inputs are crafted to exploit the classifier’s learned decision boundary. An attacker who understands the model’s statistical patterns can consistently produce harmful content that scores below any automated threshold, rendering single-classifier architectures inadequate against motivated adversaries.
The Data Says
Automated toxicity classifiers fail in two symmetric directions — over-flagging minority speech and under-detecting adversarial toxicity — because they learned the surface features of harm rather than its semantics. Until classification architectures can distinguish between a word’s identity and its intent, this dual failure is structural, not temporary.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors