Fairness by Numbers: When Bias Metrics Mask Structural Inequality Instead of Fixing It
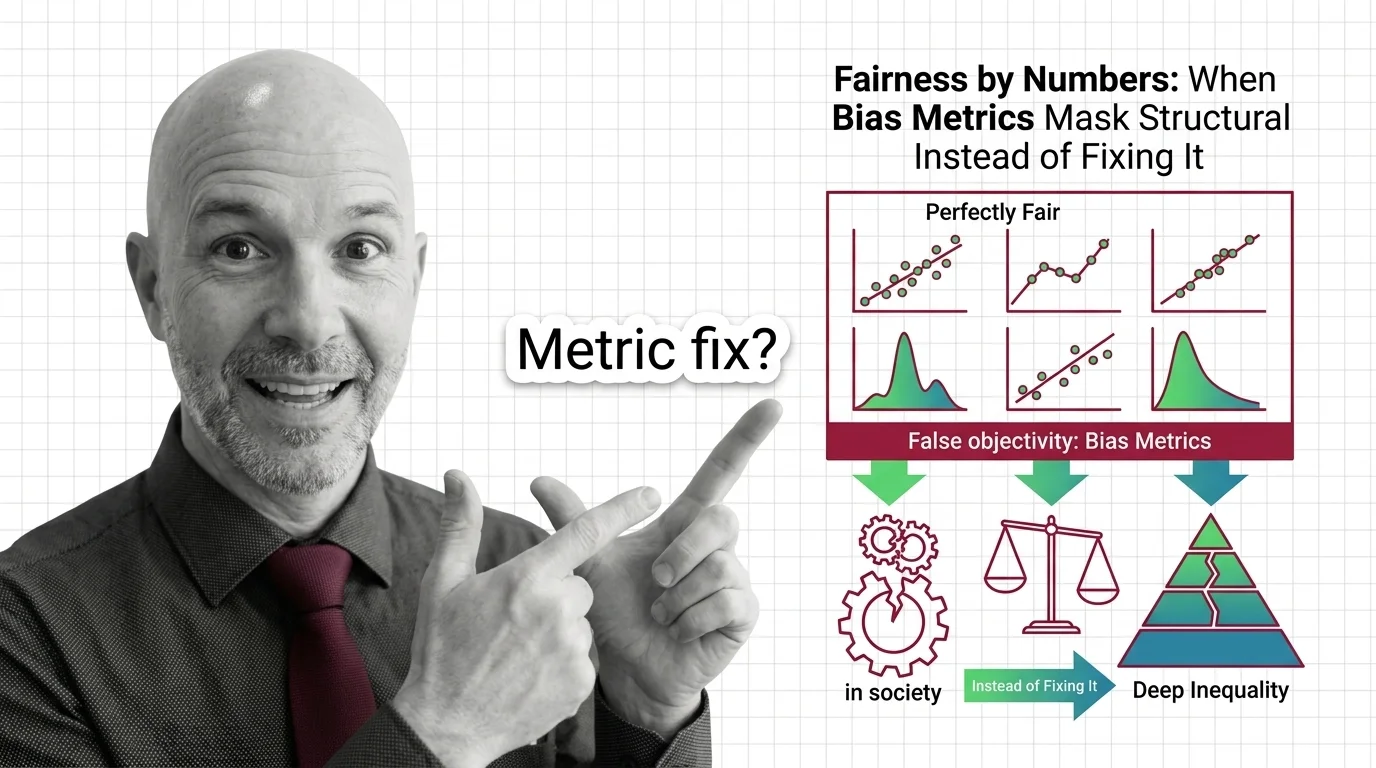
Table of Contents
The Hard Truth
If a hiring algorithm rejects candidates from disadvantaged communities at the same rate it rejects everyone else, is it fair? What if the reason it rejects them equally is that it learned to penalize the zip codes where they live — and the metric you chose cannot see the difference?
We have more tools for measuring fairness than at any point in the history of computation. One toolkit offers over seventy metrics. Another integrates with every major ML framework. Regulatory bodies are drafting enforcement deadlines. And yet the hardest question in algorithmic fairness is not how to measure bias — it is whether measurement, by itself, does anything about the conditions that produce it.
The Comfort of Having a Number
There is something deeply reassuring about a fairness score. It translates a moral question — are we treating people justly? — into a technical answer: a ratio, a threshold, a pass/fail gate. Demographic Parity offers a clean formulation: selection rates should be equal across groups, regardless of qualification. Equalized Odds refines the demand: true positive rates and false positive rates should match across Protected Attribute categories. Each metric carries the authority of mathematics — precise, reproducible, apparently beyond argument.
This precision is not accidental. It responds to a genuine need. When ProPublica investigated the COMPAS recidivism tool, they found that Black defendants were roughly twice as likely to be falsely flagged as high-risk (ProPublica). Northpointe, the company behind COMPAS, countered that predictive parity — the positive predictive value — was equal across races. Both claims were mathematically correct. They measured different things.
The dispute was never about arithmetic — it was about which harm counts.
The Case for Counting
The case for Bias And Fairness Metrics is not trivial, and it would be dishonest to treat it as such. Before these tools existed, the default was worse: unexamined intuition, unchallenged assumptions, disparities visible only to the people experiencing them. Fairness metrics made a specific kind of harm legible. They gave engineers a vocabulary for Disparate Impact that had previously belonged only to civil rights lawyers and sociologists. They made it possible to say, with evidence, that a system was treating protected groups differently — and to demand a fix.
Toolkits like AI Fairness 360 and Fairlearn operationalized that vocabulary. AIF360 packages over seventy metrics and ten mitigation algorithms under one framework, though its last release was April 2024 and its development pace appears to have slowed (AIF360 GitHub). Fairlearn, now at v0.13.0, integrates directly with scikit-learn, TensorFlow, and PyTorch — making fairness checks a standard pipeline step rather than an afterthought (Fairlearn GitHub). The NIST AI Risk Management Framework formalized the idea that bias is not only computational but systemic and human-cognitive, pushing organizations to address it across governance, mapping, measurement, and management functions.
These are genuine contributions. The question is what happens when the contribution becomes the entire conversation.
The Assumption Inside the Equation
Every fairness metric carries a hidden premise: that the relevant categories are the right ones, that the thresholds are meaningful, and that satisfying the metric constitutes progress toward justice. But the Impossibility Theorem — proved independently by Chouldechova in 2017 and by Kleinberg, Mullainathan, and Raghavan in 2016 — demonstrated something uncomfortable. When base rates differ between groups, it is mathematically impossible to simultaneously equalize false positive rates, false negative rates, and positive predictive values (Chouldechova 2017).
This is not a bug in any particular toolkit. It is a structural property of classification itself, visible in any properly constructed Confusion Matrix. And it means that choosing a fairness metric is never a neutral technical decision — it is a moral one, because every metric privileges one kind of harm over another.
Who makes that choice? In most organizations, it falls to the engineering team, sometimes to a product manager, occasionally to a compliance officer. Rarely to the people whose lives are shaped by the outcome. The question of who decides which fairness metric to use, and what threshold counts as “fair enough,” is treated as an implementation detail when it is, in reality, a political one.
The Precedent We Keep Forgetting
There is a pattern in the history of institutions worth remembering here. Standardized testing emerged in the early twentieth century as a tool for fairness — a way to replace nepotism and social prejudice with objective measurement. The SAT, the IQ test, the civil service examination: each promised to see ability where society saw only status. And each, over decades, revealed the same structural problem. The measurement was precise. The conditions it measured were not equal. The test could not close the gap between a well-funded suburban school and an underfunded one. It could only document the gap — and, in doing so, give it the appearance of inevitability.
Algorithmic fairness metrics are tracing the same arc. A system can satisfy demographic parity and still operate within a policy framework that is punitive, exclusionary, or extractive. A lending algorithm that denies credit equally across racial groups is not “fair” if the credit scoring model it relies on was built on decades of redlining data. The metric measures a property of the model. The harm lives in the pipeline — in the data, in the policy, in the institution that runs it.
FAccT 2024 research confirmed what this pattern suggests: algorithm modification alone is insufficient because it rarely engages with the structural root causes of bias (ACM FAccT 2024). A technically fair system can still automate inequality if the inequality is baked into the inputs. The metric does not lie. It simply does not see what it was not designed to measure.
The Arithmetic of Justice Is Not Justice
Thesis: Fairness metrics are necessary instruments of accountability, but treating them as sufficient evidence of fairness allows institutions to claim ethical compliance while leaving structural inequality untouched.
This is not a call to abandon measurement. It is a demand that measurement be placed in context. Counterfactual Fairness gestures toward this by asking whether a decision would have been the same had a person’s protected attributes been different — a thought experiment that forces the analysis beyond surface-level parity. But even counterfactual fairness operates within the model’s learned world, which is itself a product of the structural conditions it cannot see.
The EU AI Act, with enforcement of high-risk system requirements beginning August 2, 2026, mandates representative training data and bias examination (EU AI Act). Penalties for prohibited AI violations reach up to EUR 35 million or 7% of global turnover. That is progress — but mandating bias examination does not specify which bias to examine, or whose definition of fairness to apply. The regulatory framework creates an obligation without resolving the underlying philosophical disagreement about what fairness means in practice.
Approximate fairness — accepting small metric gaps rather than demanding exact equality — may be practically achievable. But the question remains who decides how small is small enough, and whether those gaps compound in ways that are invisible at the level of a single metric but devastating at the level of a community.
The Questions We Owe Each Other
Can fairness metrics create a false sense of objectivity about AI discrimination? The evidence suggests they can — not because the metrics are wrong, but because they are precise about the wrong thing. A score that says “this model treats groups equally” can be simultaneously true and misleading if the groups were never equal to begin with.
The honest path forward is not to build better metrics, though that work matters. It is to insist that every fairness evaluation answer two questions: fair compared to what? And fair according to whom? Until those answers are surfaced — not embedded in default settings, not delegated to engineering teams, not buried in documentation that nobody reads — the metrics serve the institution more than the people they claim to protect.
Where This Argument Is Weakest
If fairness metrics are insufficient, the alternative is not obvious. Without quantitative measurement, bias becomes a matter of opinion — and opinion has historically favored whoever holds power. The strongest objection to this essay is that imperfect measurement is still better than no measurement at all, and that demanding structural solutions before accepting technical ones may leave vulnerable populations waiting indefinitely for either. That objection deserves serious weight. The risk of this argument is that it becomes a reason to do nothing.
The Question That Remains
We built tools to count unfairness. We got better at counting. The unfairness did not decrease at the same rate. At some point we will have to decide whether the purpose of a fairness metric is to change the world — or to make it easier to live with the world as it is.
Disclaimer
This article is for educational purposes only and does not constitute professional advice. Consult qualified professionals for decisions in your specific situation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors